虚拟内存
对主存的抽象,支持处理器通过虚拟寻址的方式来引用主存
三个功能
- 缓存磁盘上的虚拟地址空间的内容
- 简化内存管理、链接、加载等
- 简化内存保护(通过PTE加保护位)
内存映射
将虚拟内存片和disk上的文件片关联起来,来初始化虚拟内存片
mmap
动态内存分配 显示分配器、隐式分配器。
malloc
Virtual Memory Concepts
Why VM?
- Uses main memory efficiently
- Use DRAM as a cache for parts of a virtual address space
- DRAM主存作为虚拟地址空间的一部分的缓存?虚拟地址空间还有一部分是啥?就是磁盘本身上的地址?
- Simplifies memory management
- Each process gets the same uniform linear address space
- Isolates address spaces
- One process can’t interfere with another’s memory
- User program cannot access privileged kernel information and code
Address Space
Physical Addressing 物理寻址
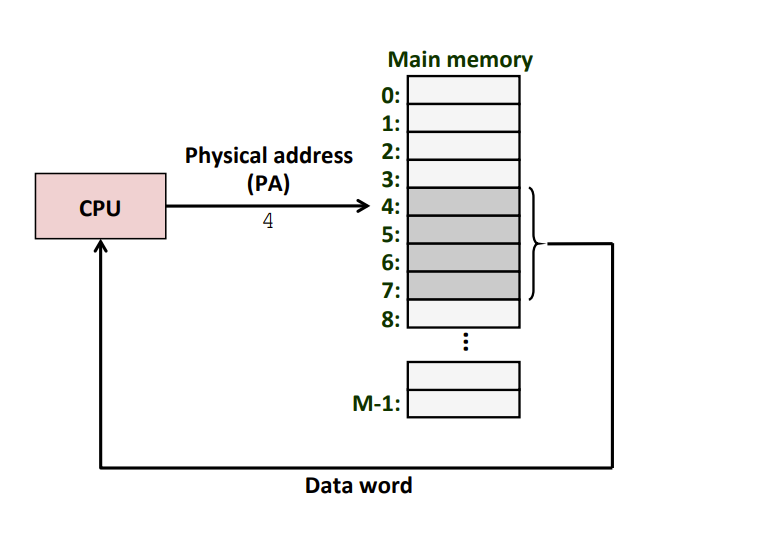
- Physical Address (PA) 物理地址:计算机的主存被组织成一个由M个连续的字节大小的单元组成的数组,每字节都有唯一的物理地址。
- Physical Addressing 物理寻址:
- CPU访问内存的一种方式
- 示例:读取物理地址4处开始的4字节字。
- CPU执行加载指令,生成一个有效物理地址,通过内存总线,把它传递给主存;
- 主存取出从物理地址处开始的4字节,并将它返回给CPU,CPU会将它存放在一个Reg中。
- 早期的PC、嵌入式微控制器等使用Physical Addressing
Virtual Addressing 虚拟寻址
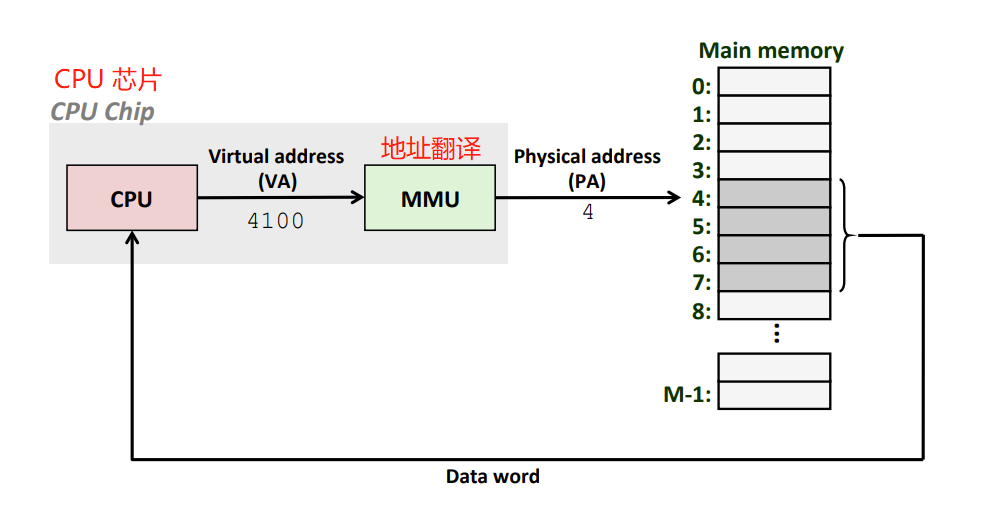
- Virtual Address (VA) 虚拟地址
- Virtual Addressing 虚拟寻址
- CPU通过生成一个虚拟地址(VA)来访问主存,然后进行地址翻译:生成的这个虚拟地址先通过MMU(Memory Management Unit)转换成物理地址
- MMU:利用存放在dram中的page table来动态翻译虚拟地址,该表的内容由os管理。
- MMU是硬件实现的,而非os的一部分
- MMU本身不保存page table,而是通过到dram中去查询
Address Space
Linear address space 线性地址空间
- 空间中的地址为连续的非负整数 {0,1,2,3…}
Virtual address space 虚拟地址空间
- 在一个带虚拟内存的系统中,CPU从一个由N=2^n个地址的地址空间中生成虚拟地址,这个地址空间称为虚拟地址空间Virtual address space
- 现代系统通常支持32位、64位虚拟地址空间
- {0,1,2,3…,N-1}
Physical address space 物理地址空间
- 对应于系统中物理内存的M个字节,M不一定是2的幂
- {0,1,2,…,M-1}
地址空间的概念,区分了数据对象(字节)和他们的属性(地址)。
虚拟内存基本思想:允许每个数据对象(字节)有多个独立的地址,其中每个地址都选自一个不同的地址空间。
主存中的每字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址。
VM as a Tool for Caching
众所周知 计算机系统中 上层是下层的缓存
那么 主存是如何作为 磁盘的缓存的呢?
要通过VM系统这个机制 来使得 主存作为磁盘的缓存
下面介绍VM系统
VM系统
虚拟内存 是 给磁盘上的一块字节序列组织起来 给他们每人一个地址 ,这个地址就是虚拟地址,所有虚拟地址在一起就叫虚拟地址空间,DRAM主存可从虚拟内存空间VM SPACE 里 取出东西 缓存到主存DRAM中
virtual memory is an array of N contiguous bytes stored on disk — 虚拟内存被组织为一个由存放在磁盘上的N个连续的字节大小的单元组成的数组
- 虚拟内存中的(也即磁盘的这块空间)每个字节都有一个唯一的虚拟地址,作为数组的索引
The contents of the array on disk are cached in physical memory (DRAM cache) — 磁盘上数组的内容被缓存在主存中
These cache blocks are called pages (size is P = 2^p bytes)
磁盘上的数据被分割成块,作为磁盘和主存之间的传输单元(如第6章所述)。
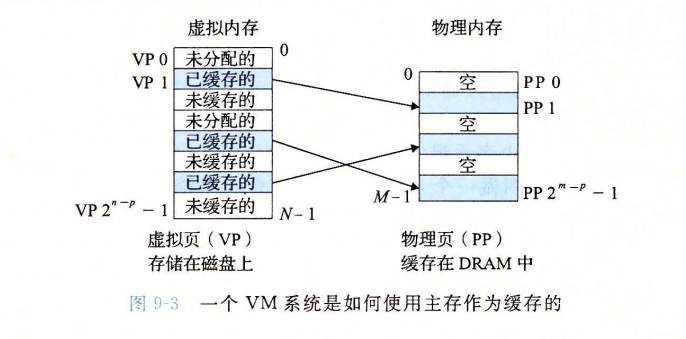
**虚拟页 Virtual Page (VP)**:VM系统将虚拟内存分割为虚拟页的大小固定的块。每个虚拟页大小为 P = 2^p 字节。也即,将磁盘的一块空间,分为一个个虚拟页,(每个字节,每个虚拟页有相应的虚拟地址。)
物理页 Physical Page (PP) / 页帧 page frame:物理内存被分割为物理页,大小也为P字节。
虚拟页面被分为三个不相交的子集
- 未分配的:VM系统还未分配(或者创建)的页。未分配的块没有任何数据和他们关联,因此也就不占用任何磁盘空间
- 缓存的:当前已经缓存在物理内存(主存)中的已分配页
- 未缓存的:未缓存在物理内存(主存)中的已分配页
DRAM Cache Organization DRAM作为缓存的组织结构
DRAM作为缓存的不命中比SRAM缓存不命中的代价昂贵很多
- DRAM is about 10x slower than SRAM
- Disk is about 10,000x slower than DRAM
因此
- 虚拟页往往很大: typically 4 KB,sometimes 2 MB
- 全相联
- Any VP can be placed in any PP
- Requires a “large” mapping function – different from cache memories
- 复杂精密的替换算法
- Write-back rather than write-through
Enabling Data Structure: Page Table 页表
VM系统需要判断 一个虚拟页VP是否缓存在DRAM中的某个地方
- 如果是(命中),系统则必须要确定这个虚拟页VP存放在那个物理页PP中
- 如果不是(未命中),系统必须判断这个虚拟页VP存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,然后将虚拟页VP从磁盘复制到DRAM中,替换这个牺牲页。
os软件 + MMU中的地址翻译硬件 + 存放在物理内存中叫做页表的数据结构 实现该功能
Page table 页表
- Array of Page Table Entry(页表条目)
- maps virtual pages to physical pages.
- virtual address space 虚拟地址空间 中的每个 VP虚拟页 在 Page Table页表 中一个固定偏移量处都有一个PTE。
- PTE的valid bit = 0
- NULL 表示这个虚拟页还未被分配
- 不是NULL ,则指向该虚拟页在磁盘的起始位置
- PTE的valid bit = 1
- 地址为DRAM中相应的物理页的起始位置
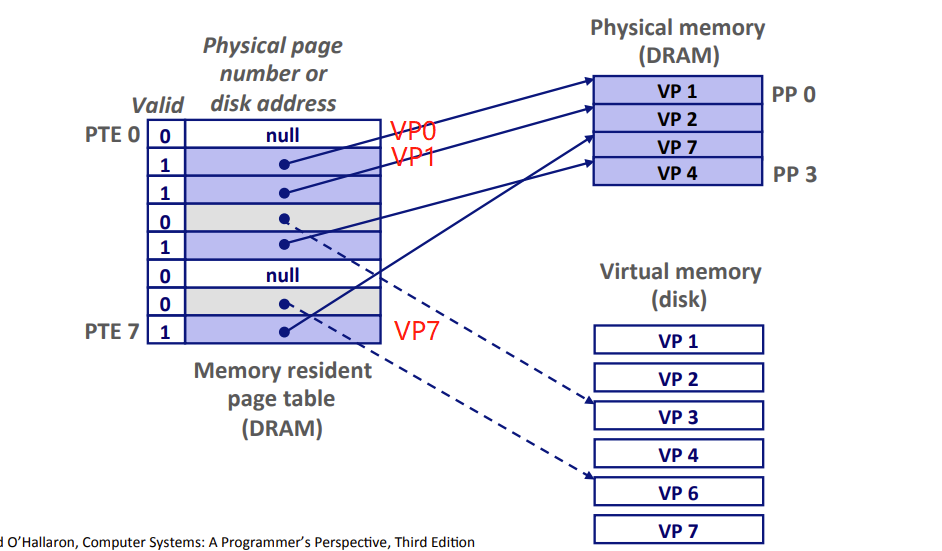
- valid bit = 1 : VP1、VP2、VP4、VP7被缓存在DRAM中
- valid bit = 0 :
- 非null : 已经被分配,但还没被缓存。VP3、VP6
- null : 没被分配。VP0、VP5
- PTE数量 = 虚拟地址空间大小 / 虚拟页大小 (因为一个VP相应的要有一个PTE)
Page Hit 页命中
示例:CPU要读取包含在VP2中的虚拟内存的一个字(已知VP2被缓存在DRAM中)
- VM页命中。对VP2中一个字的引用就会命中
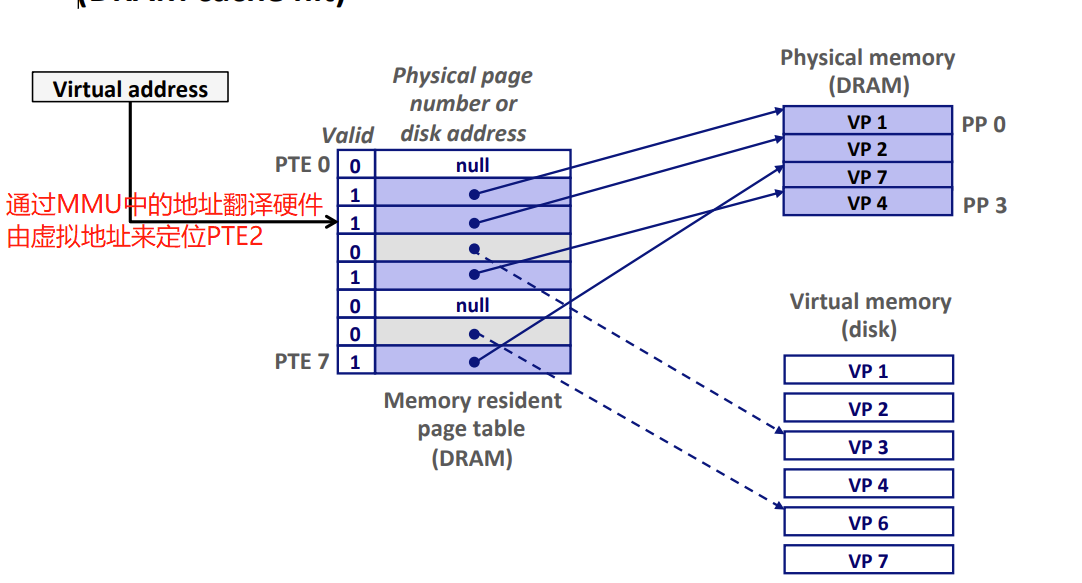
- VM页命中。对VP2中一个字的引用就会命中
虚拟地址VA —–MMU地址翻译硬件—-> 定位PTE –在内存中读取PTE–>
- —-> valid bit = 1 —-> VP2已经缓存在DRAM中 —>
- —-> 使用PTE中的DRAM(物理内存)地址(该地址指向PP1中缓存页的起始位置(在DRAM中的地址)) —–> 构造出这个字在DRAM中的物理地址
MMU如何工作具体看下面
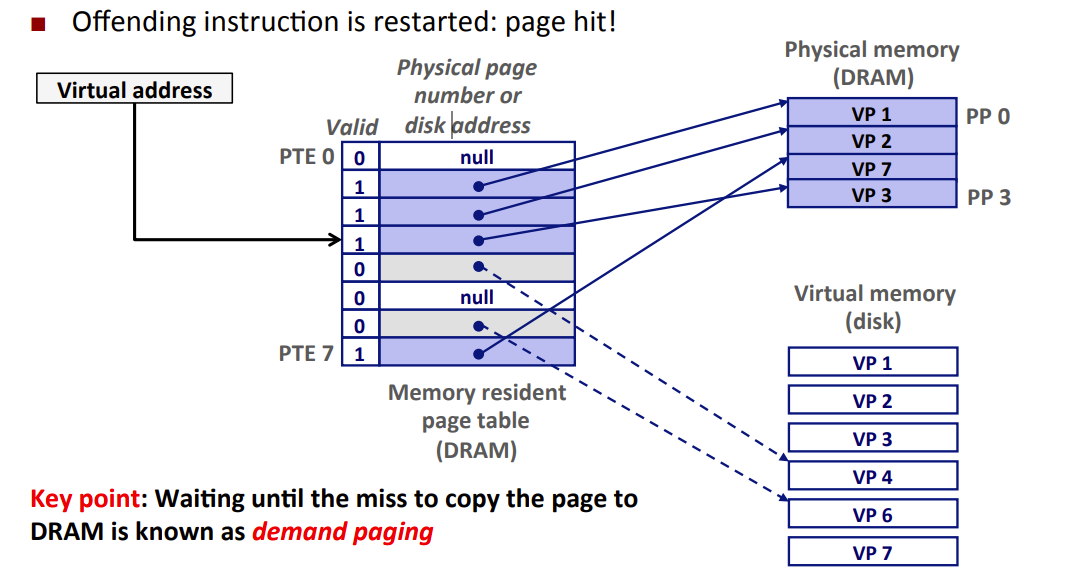
Page Fault 缺页
- 缺页 page fault:VM系统中,DRAM缓存不命中称为缺页
- reference to VM word that is not in physical memory (DRAM cache miss)
- 示例:CPU引用VP3中的一个字(已知VP3并未缓存在DRAM中)
- VP3不命中(缺页),对VP3中的字的引用也就不命中,触发Page Fault
- 虚拟地址VA —MMU的地址翻译硬件—-> 定位PTE —在主存中读取PTE—>
- valid bit = 0 —-> VP3没被缓存 && !=null —-> 指向虚拟页VP3在磁盘的起始位置
- —> 触发缺页异常 cause Page Fault
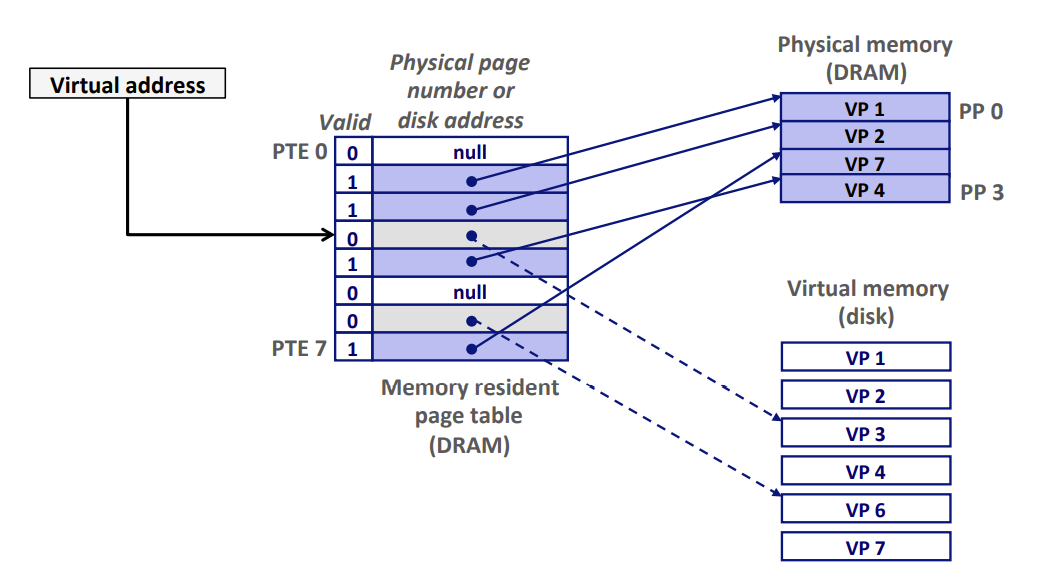
- —> kernel call Page Fault handler
- 在DRAM中选择一个PP存放的的VP作为牺牲页
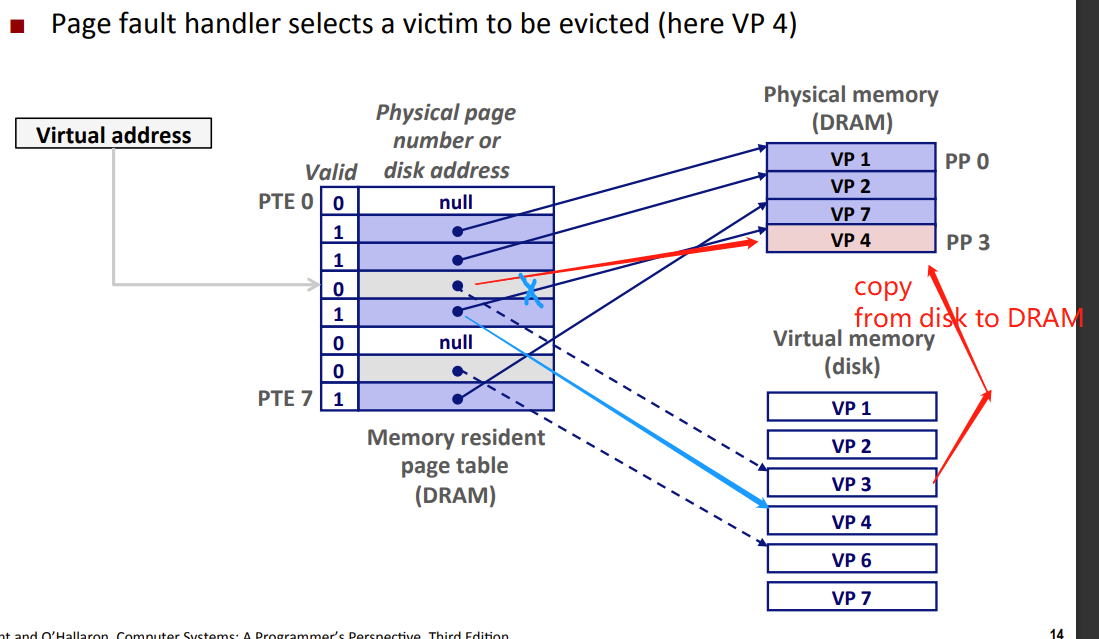
- kernel 将VP3从磁盘copy到DRAM,并更新PTE3,随后返回。
- 在DRAM中选择一个PP存放的的VP作为牺牲页
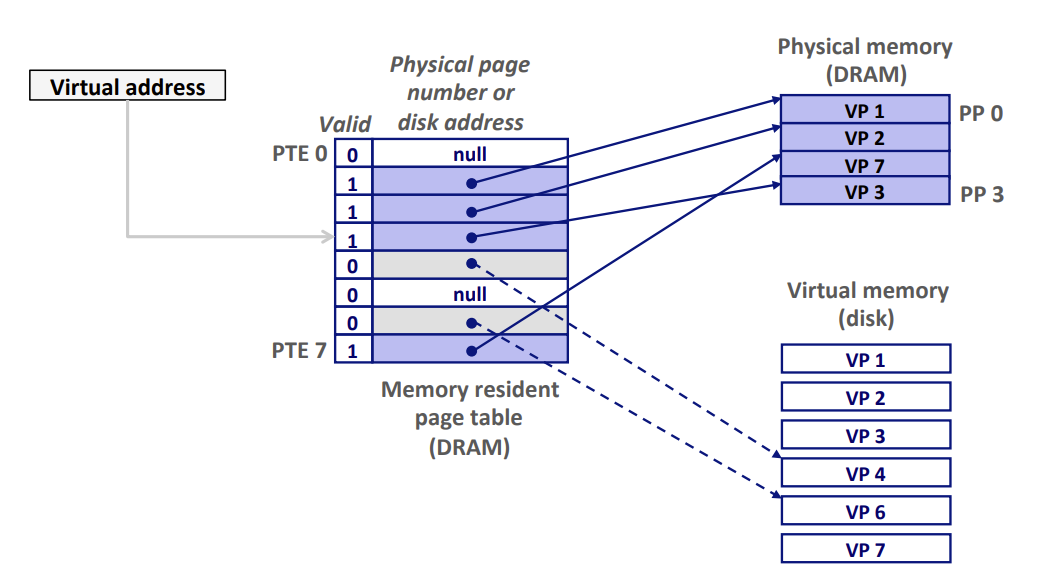
- Page Fault Handler return to I_cur , 造成Page Fault的指令重新执行,此时Page Hit,该指令将正常的从内存读取字,而不会再产生Page Fault。
- 该指令将VA重新发送给硬件,但是VP3已经缓存在DRAM中,故Page Hit。
- 该指令将VA重新发送给硬件,但是VP3已经缓存在DRAM中,故Page Hit。
VM系统使用了和SRAM缓存不同的术语
- VM中 块 被称为 页
- VM中 磁盘和内存之间传送页的行为称为交换(swapping)或者页面调度(paging)
- 页从磁盘换入(或者页面调入)DRAM和从DRAM换出(或者页面调出)磁盘
- demand paging 按需页面调度:waiting until the miss to copy the page from disk to DRAM
MMU如何工作具体看下面
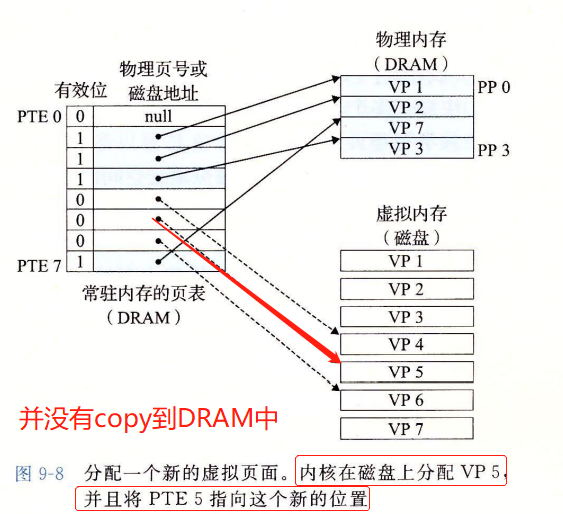
Allocating Pages 分配页面
- 当os分配了一个新的虚拟内存页,对页表有何影响?
- 只影响了PTE和disk,并不改变DRAM的PP
- 如下调用malloc的结果,
- Allocating a new page (VP 5) of virtual memory.
- 在磁盘上创建空间
- 更新PTE5,指向这个新创建的页面。
Locality 局部性 makes VM work
- Virtual memory seems terribly inefficient, but it works because of locality
- 尽管整个运行过程中程序引用的不同页面总数可能超出DRAM总的大小,但是Locality保证了任意时刻,程序趋向于在一个较小的活动页面(active page)几何上工作,这个集合称为工作集(working set)或者常驻集合(resident set)
- Programs with bigger temporal locality will have smaller working sets
- If (working set size < main memory size)
- Good performance for one process aier compulsory misses
- 在初始开销,也就是将工作集页面调度到内存中之后,接下来对这个working set的引用将集中命中,而不会产生额外磁盘IO
- If ( SUM(working set sizes) > main memory size )
- Thrashing 抖动: Performance meltdown where pages are swapped (copied) in and out continuously
VM as a Tool for Memory Management 虚拟内存作为内存管理的工具
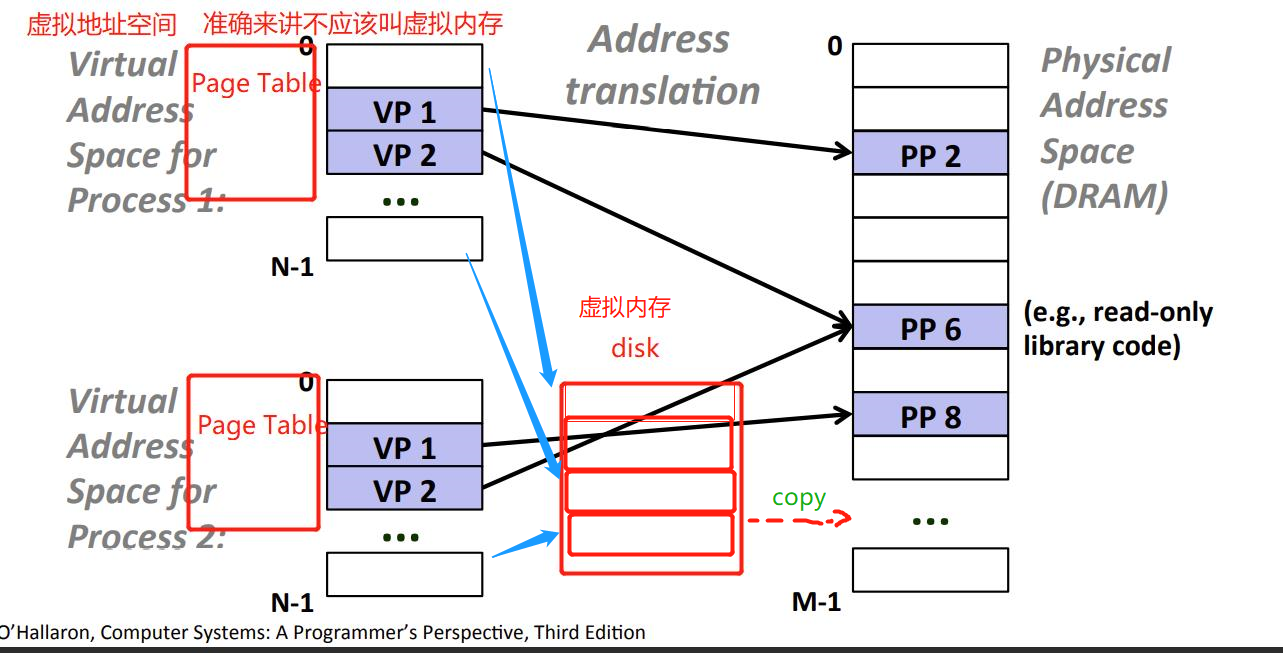
Page Table – Virtual Address Space
- 如何为每个进程维护一个虚拟地址空间?
- os为每个进程提供了一个独立的页表page table,页表page table维护了虚拟地址空间virtual address space。
- 每个进程的虚拟地址空间实际上就是kernel的page table。(虚拟地址 -翻译-> 相应PTE –> 相应DRAM / 触发page fault )
- 如下图 progess i的page table将i的虚拟地址空间里的VP1(逻辑上的,不存在的一个VP)映射到DRAM中的PP2,VP2->PP7 ; progess j 的page table 将 VP1 -> PP7 , VP2->PP10。
Advantages
- 简化链接
- 简化加载
程序员可以认为每个进程有一个非常相似的虚拟地址空间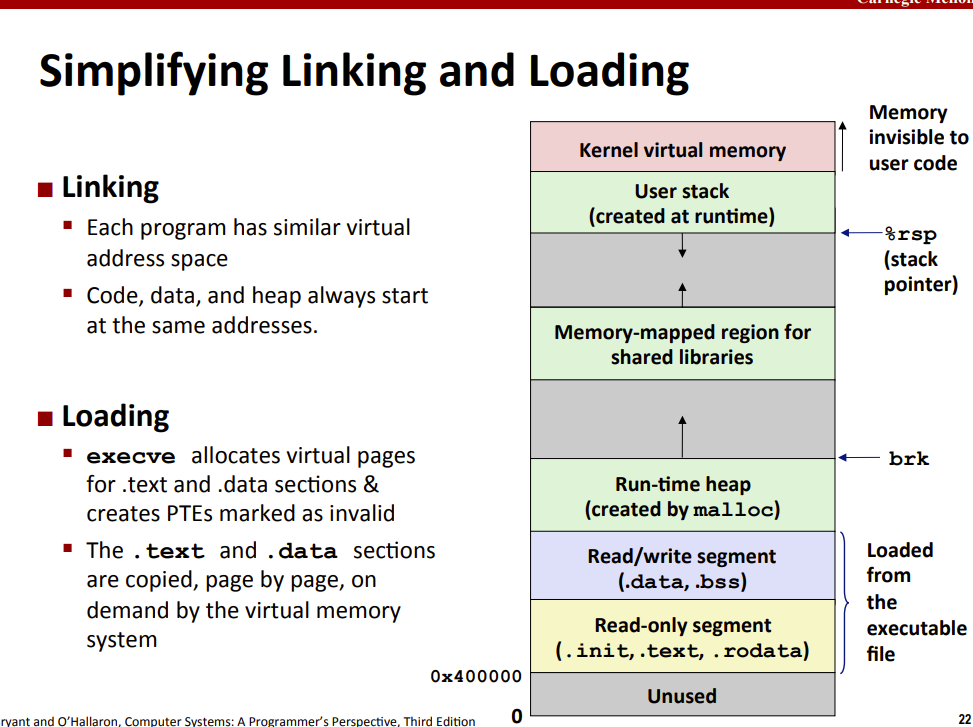
- 简化共享
- 如何让多个进程共享代码、数据?
- 让不同进程的page table的PTE指向同一个PP(共享库的实现方式)
- 每个进程都必须调用相同的kernel代码,每个C程序都会调用C标准库,通过上述方式,可以使得多个进程共享这部分代码的副本,而不是在每个进程中都包括单独的kernel和C库的副本,
- mmap
- 如何让多个进程共享代码、数据?
- 简化内存分配
- K个连续的虚拟内存页面,可以映射到DRAM中任意位置的k个物理页面。(可以随机分散在DRAM中)
虚拟内存 != 虚拟地址空间
- 虚拟地址空间 和 虚拟内存不是一回事! 反正我这么认为
- 虚拟地址空间:cpu(通过地址总线32位能力)寻址虚拟出来的一个范围。
- 而虚拟内存:实实在在的硬盘的空间。所以,虚拟内存分割成的的虚拟页也都是实实在在的磁盘空间。,而虚拟地址空间划分的虚拟页,是想象出来的,逻辑上的,(实际上不存在这个VP表,而是一个页表,)这个虚拟页要去指向一个DRAM中的PP,DRAM中的PP,保存的是从磁盘缓存来的实际虚拟内存的VP页。
- cpu认为他有4G内存空间是因为CPU的地址总线有32位,最大的寻址能力就为4G
- 而DRAM实际上没这么大,所以它想出办法,将硬盘的一部分拿过来,当作主存,骗cpu;并给这块骗人的地方,起名字叫 虚拟内存。(如何用虚拟内存骗人的?DRAM是虚拟内存的缓存,如果DRAM中有cpu要引用的页,那么直接从DRAM里拿,如果没有,那么根据替换算法,选择DRAM中的牺牲页,将要引用的磁盘里的虚拟页替换进来。
VM as a tool for memory protection 虚拟内存作为内存保护的工具
os需要有手段来控制对内存系统的访问,如
- 不允许用户进程修改rodata段
- 不允许它读或修改任何kernel中的代码和数据结构
- 不允许它读或者写其他progess的私有内存
- 不允许他修改任何与其他进程共享的虚拟页面(指向同一PP的VP),除非所有的共享者都显式地允许他这么做。
CPU每生成一个VP,MMU都会读一个PTE,因此在PTE上加permission bits
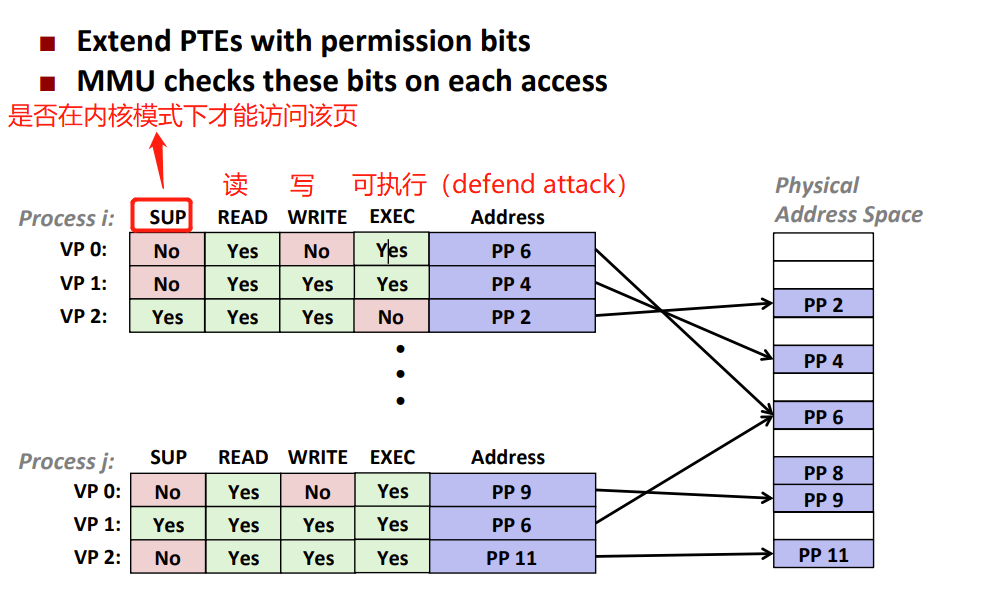
segmentation fault
- 如果有指令违反了这些条件,就会触发异常:一般保护故障
- Linux shell一般报告为 段错误(segmentation fault)
VM Effect Summary
Programmer’s view of virtual memory
- Each process has its own private linear address space
- Cannot be corrupted by other processes
System view of virtual memory
- Uses memory efficiently by caching virtual memory pages (from disk to DRAM)
- Efficient only because of locality
- Simplifies memory management and programming
- Simplifies protection by providing a convenient interpositioning point
to check permissions
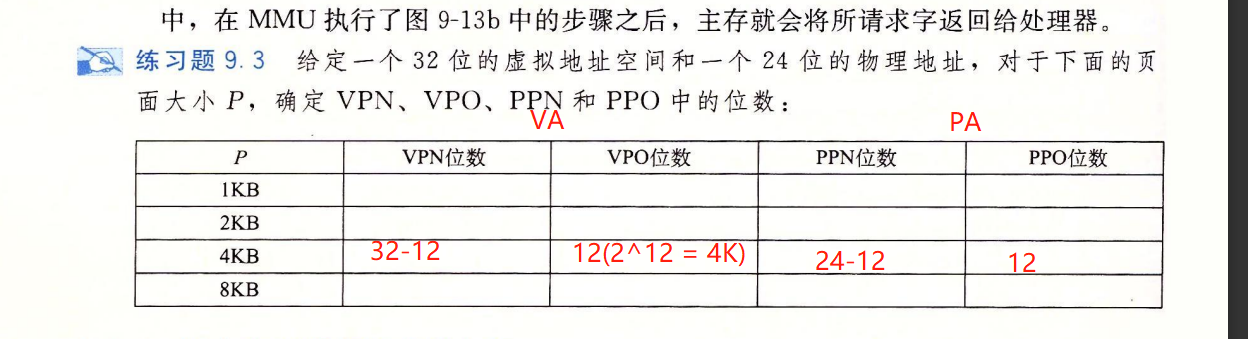
VM地址翻译 Address translation
- MMU地址翻译大体分为两步
- 将VA翻译为PA(涉及TLB)
- 将PA送至缓存
概念 & 公式
- Virtual Address Space VAS 虚拟地址空间
- V = {0, 1, …, N–1}
- Physical Address Space PAS 物理地址空间
- P = {0, 1, …, M–1}

- 地址翻译:一个N元素的VAS中的元素 和一个 M元素的PAS中元素之间的映射

- For virtual address a:
- MAP(a) = a’ if data at virtual address a is at physical address a’ in P
- MAP(a) = ∅ if data at virtual address a is not in physical memory
- Either invalid or stored on disk
- For virtual address a:
MMU工作 & Page Table细节
Virtual address 如何定位到 PTE && Page Table里的PTE如何对应到相应物理地址?
- 通过MMU。
MMU是个硬件,其中没有page table,page table是存储在dram中的!
MMU功能:
- 根据VA计算PTEA :PTEA = register + VPN,CPU —VA—> MMU —PTEA—> DRAM
- 根据PTE计算PA :PA = PPN + PPO,MMU <–PTE– DRAM , MMU –PA–> DRAM
- TLB :PTE缓存,根据VA快速获取PTE。
- 根据VA(VPN)查看是否缓存了VA对应的PTE,如果是,那么直接返回缓存的PTE,不必到dram中的pagetbale查询。不是,则去查询pagetable
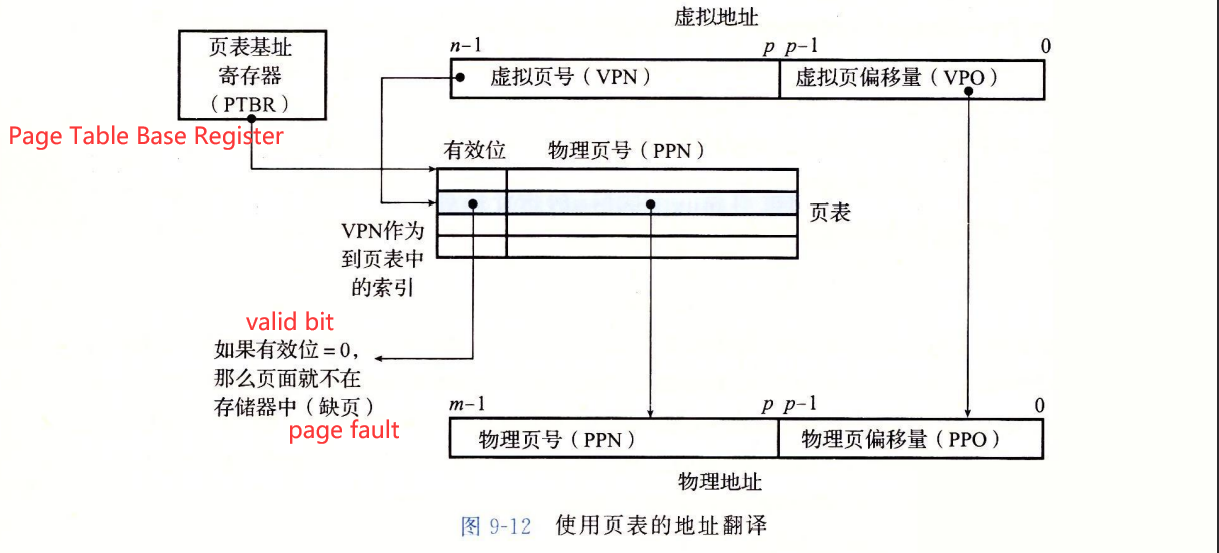
- n位的virtual address:
- p位VPO 虚拟页面偏移(virtual page offset)+ 一个 n-p位的VPN 虚拟页号(virtual page number)
- VPN就是讲缓存的时候讲的tag标记
- VPO就是讲缓存的时候讲的offset块偏移
- 没有组索引,是因为因为代价很大,采用了全相联。
- p位VPO 虚拟页面偏移(virtual page offset)+ 一个 n-p位的VPN 虚拟页号(virtual page number)
- m位的physical address
- PPN(physical page number)物理页号 + PPO(physical page offset)物理页偏移量
- MMU —-VPN和PTBR—->计算出PTEA —> 确定PTE —-> 取出PPN —–> +VA里的VPO —-> 得到相应物理地址(因为VP和PP都是P字节的,所以PPO=VPO)
- n位的virtual address:
PTEA : VPN虚拟页号 + PTBR页表基地址
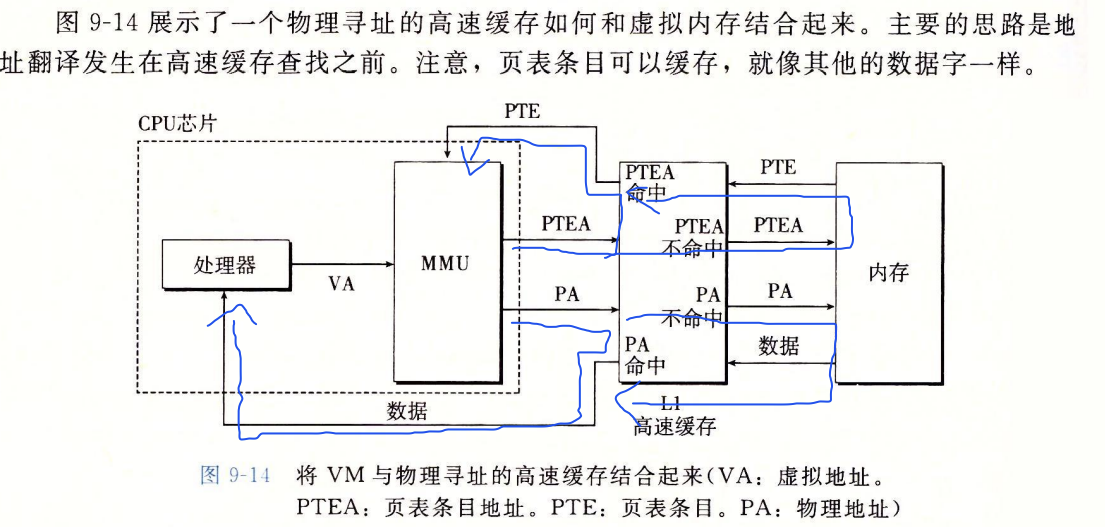
Page Hit 页命中
- 完全由硬件处理
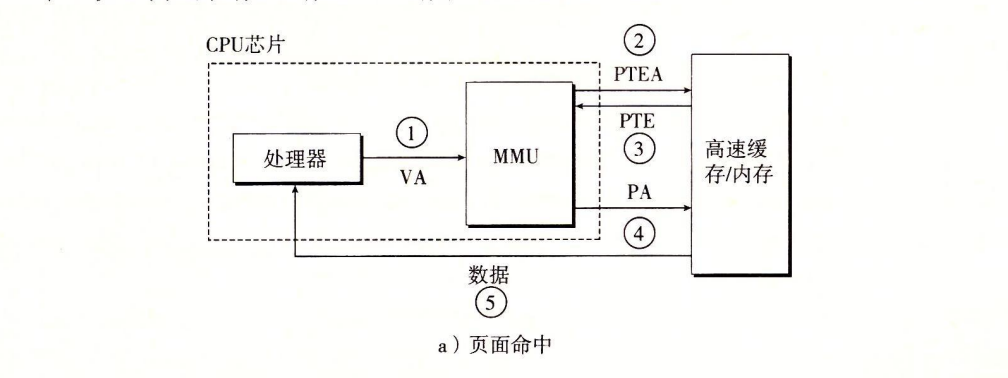
- cpu生成virtual address,并把它传送给MMU
- MMU生成PTE Address,并向高速缓存SRAM/主存DRAM请求得到它
- 高速缓存/主存向MMU返回PTE
- MMU构造physical address,并将其传送给高速缓存SRAM/主存DRAM
- 高速缓存SRAM/主存DRAM讲所请求的data返回给cpu
1
2
3
4
5- 1. cpu ---VA---> MMU
- 2. MMU ---PTEA---> SRAM/DRAM
- 3. MMU <---PTE--- SRAM/DRAM
- 4. MMU ---PA----> SRAM/DRAM
- 5. CPU <---data--- SRAM/DRAM
- 高速缓存SRAM/主存DRAM讲所请求的data返回给cpu
Page Fault 缺页
由硬件和os kernel协作完成
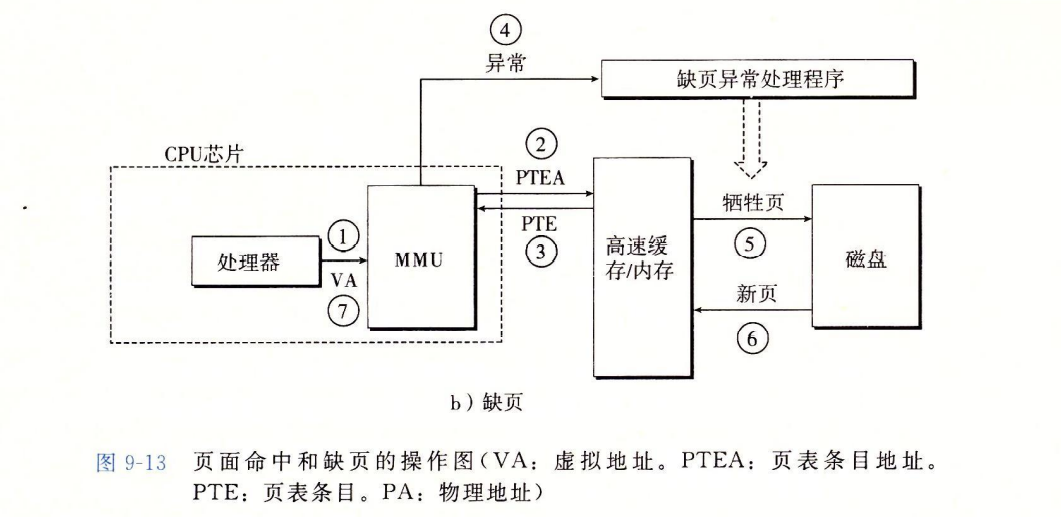
- cpu —VA—> MMU
- MMU —PTEA—> SRAM/DRAM
- MMU <—PTE— SRAM/DRAM
- PTE的有效位为0,因此MMU触发了一次page fault exception,传递cpu中的控制到kernel中的page fault handler
- page fault handler选出了dram中的牺牲页,如果该victim has been modified,则把它换出到磁盘disk
- page fault handler 调入新的页面到DRAM(将DRAM中的VP拷贝到DRAM中的PP),并更新page table中的PTE
- return to I_cur,再次执行导致page fault的指令。cpu将VA重新发送给MMU,因为VP已经被缓存在DRAM中,故命中。重复Page Hit行为
VA的VPN,VPO;PA的PPN,PPO计算
- 2^VPO = size of P / 2^PPO = sizeof P
高速缓存 + VM
翻译后备缓冲器 TLB(为了更快得到PTE,进而更快得到PA)
Translation Lookaside Buffer TLB:MMU中包括的一个关于PTE的小缓存
- CPU生成VA之后要查询PTE
- 从DRAM中查询:几十—几百时钟周期
- 从SRAM中查询:几个时钟周期
- 优化:增加这个TLB
- CPU生成VA之后要查询PTE
MMU中的通过VA中的VPN来寻找缓存在TLB中的相应PTE
- 划分成t位组索引TLBI,和剩余的位作为行标记TLBT(如果TLB有T=2^t个组,那么TLB索引(TLBI)则由VPN的低t位组成)
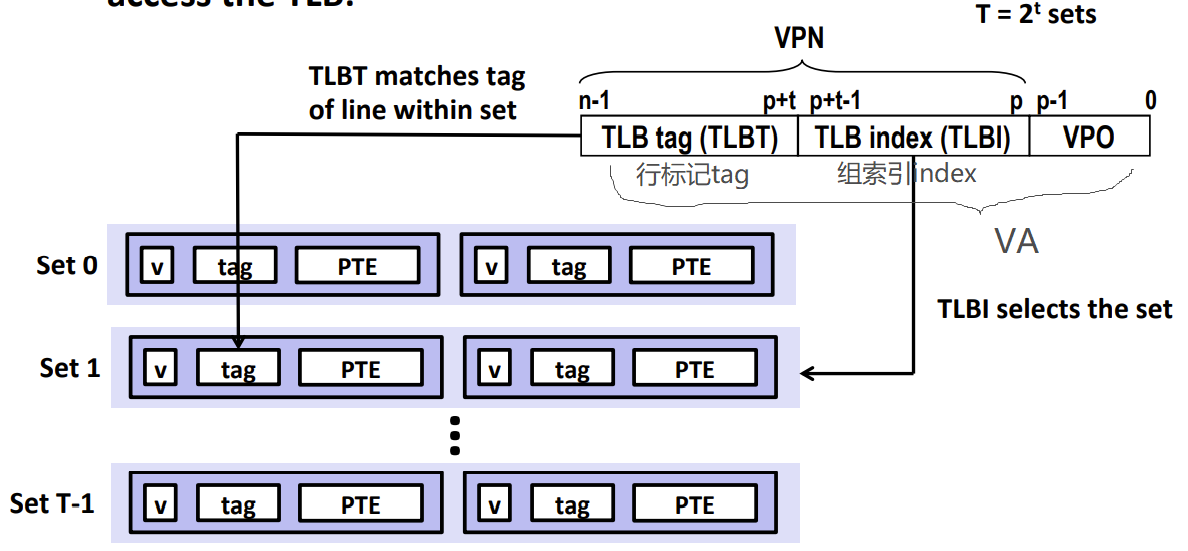
- 划分成t位组索引TLBI,和剩余的位作为行标记TLBT(如果TLB有T=2^t个组,那么TLB索引(TLBI)则由VPN的低t位组成)
TLB HIT TLB命中
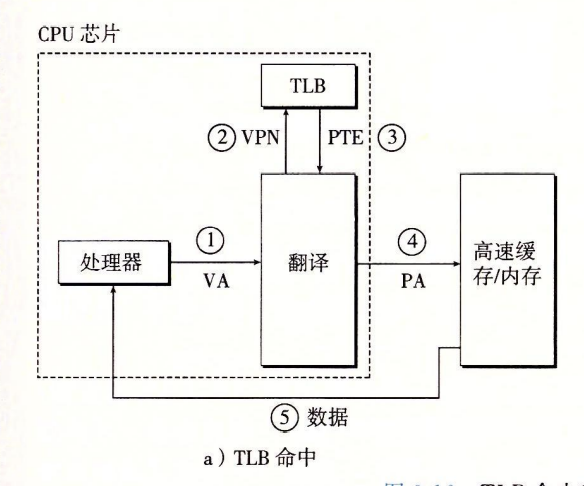
- 因为所有地址翻译步骤均由硬件完成,因此快。(减少了一次访存SRAM/DRAM)
- CPU —产生VA—> MMU
- MMU —- VPN —-> TLB
- TLB —- PTE —-> MMU
- MMU —- PA —-> SRAM/DRAM (MMU根据PTE翻译出PA)
- SRAM/DRAM — data —> CPU
TLB MISS TLB不命中
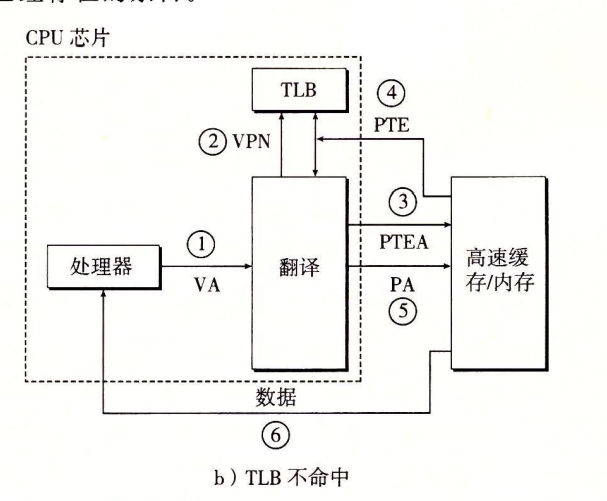
- CPU —产生VA—> MMU
- MMU —- VPN —-> TLB
- MMU —- PTEA —-> SRAM/DRAM (MMU根据VA翻译出PTEA)
- TLB没命中,MMU就会利用VA中的VPN和PTBR寄存器中的page table基地址,计算出PTE的地址(PTEA)
- SRAM/DRAM —- PTE —-> TLB && MMU
- MMU —- PA —–> SRAM/DRAM (MMU根据PTE翻译出PA)
- SRAM/DRAM —- data —> CPU
Multi-Level Page Tables 多级页表
- Suppose:
- 4KB (212) page size, 48-bit address space, 8-byte PTE
- Problem:
- Would need a 512 GB page table 常驻内存!
- 2^48 * 2^-12 * 2^3 = 2^39 bytes
- Solution:Multi-level Page Tables 多级页表
2-level page table 二级页表
例子:32bit,4bytes per table,VM4GB
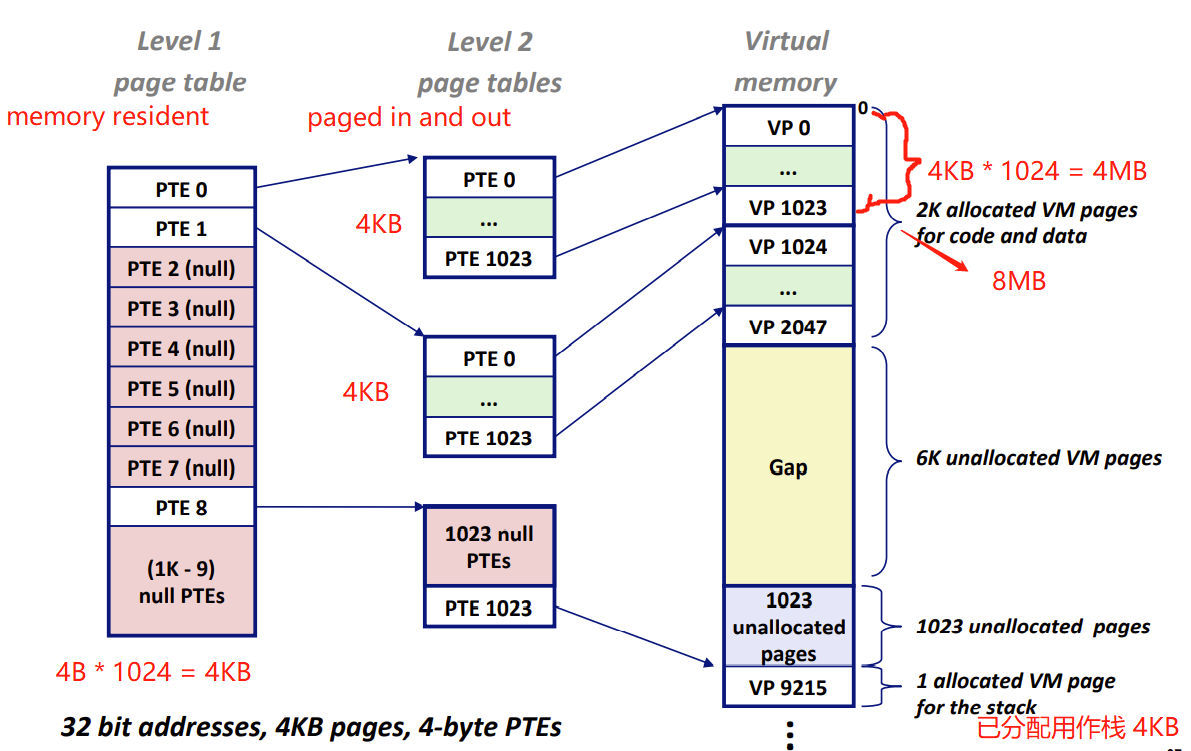
一级页表 level 1 page table
- 每个PTE指向一个level2的page table页表
- 常驻内存 (memory resident)
- 例子中每个level1的PTE最终map到一个4MB的虚拟内存VM
二级页表 level 2 page table
- 每个PTE指向一个4KB的VP虚拟内存页面
- 在需要时创建、页面调入或调出
- 例子中每个level2 page table最终map到一个4MB的虚拟内存VM
如何节约内存?
- 如果一级页表中的一个PTE为空,那么相应的二级页表则不会存在。
- 这是一种巨大的潜在节约,因为对于一个典型的程序,4GB的虚拟地址空间的大部分都是未分配的
- 只有一级页表才需要总是在主存中(memory resident);虚拟内存系统可以在需要时创建、页面调入或调出二级页表。减少主存压力
- 只有最常用的二级页表才需要缓存在主存中。
- 如果一级页表中的一个PTE为空,那么相应的二级页表则不会存在。
K-level Page Table k级页表
k级页表层次结构的地址翻译
page table register 中存储的是page table的PA物理地址。因为第一个page table是在dram中的。使用物理地址,我们可以直接找到在dram中找到page table。如果是虚拟地址的话,则会出现递归查询。(因为那样就要先把VA翻译成PA,而这个过程就是我们正在执行的过程。出现递归查询了。)

第k级页表中的每个PTE
- 要么包含某个物理页面的PPN,这个PPN是一个DRAM的页面基地址(physical page 的 base addr),这个页面,cached了一个虚拟内存里的VM的内容。
- 要么包含一个磁盘块地址
- NULL?
为了构造物理地址PA = PPN+PPO
- MMU必须访问k个PTE来确定PPN
- PPO = VPO
访问k个PTE,看起来很慢,实际上通过TLB将不同层次的table缓存起来,并不比单级页表慢很多。
Address translation 例子
CPU —> VA —VPN(TLBT,TLBI)—> TLB
- TLB命中
- 获取PTE —-> PNN —(+VPO)–> PA(CT,CI,CO) —-> 防蚊SRAM
- SRAM Hit ,return data to cpu
- SRAM Miss , 根据PA访问DRAM , return data to cpu
- 获取PTE —-> PNN —(+VPO)–> PA(CT,CI,CO) —-> 防蚊SRAM
- TLB不命中
- 访问SRAM/DRAM的Page Table中的PTE
- PTE valid bit = 1,取出PPN
- —(+VPO)–> 组成PA(CT,CI,CO) —-> 访问SRAM
- SRAM Hit ,return data to cpu
- SRAM Miss , 根据PA访问DRAM , return data to cpu
- —(+VPO)–> 组成PA(CT,CI,CO) —-> 访问SRAM
- PTE valid bit = 0,缺页 Page Fault
- kernal调入合适的页面(复制磁盘的VP到DRAM得PP,更新PTE)
- 重新运行造成page fault的指令
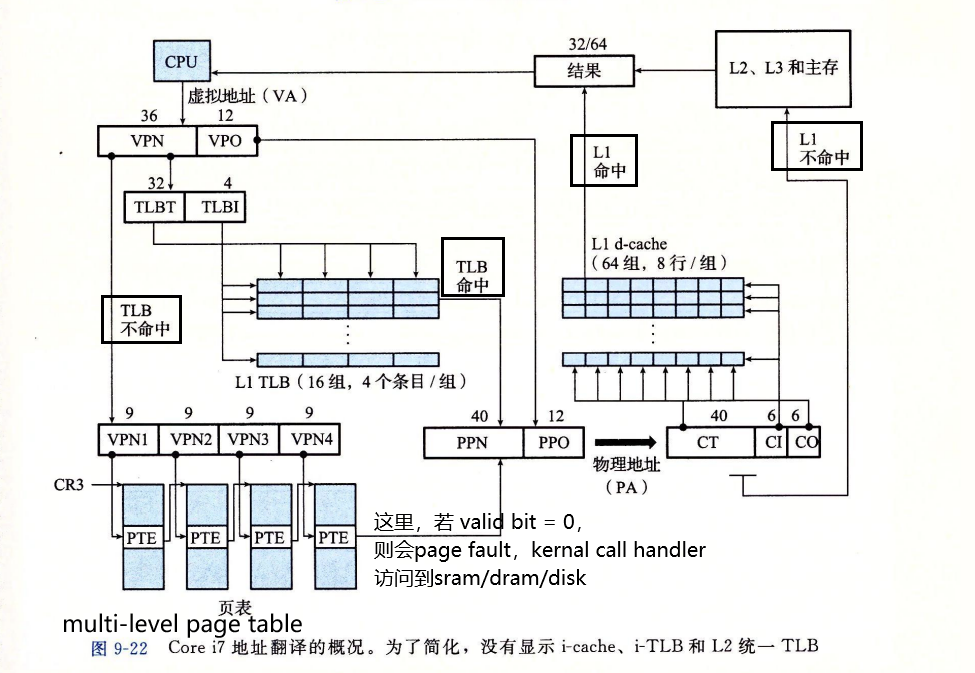
- PTE valid bit = 1,取出PPN
- 访问SRAM/DRAM的Page Table中的PTE
- TLB命中
例子


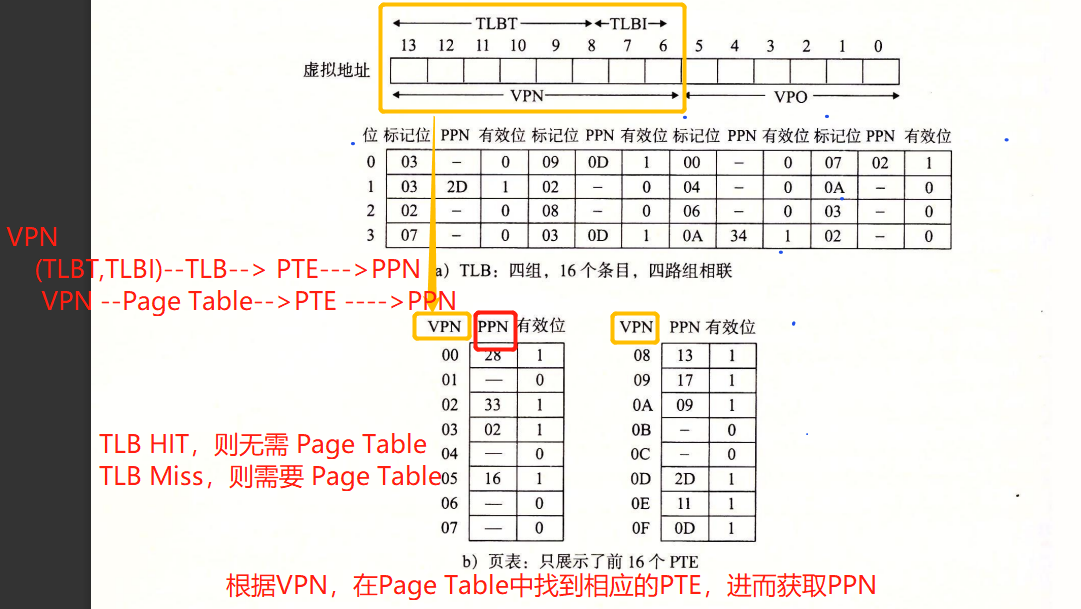
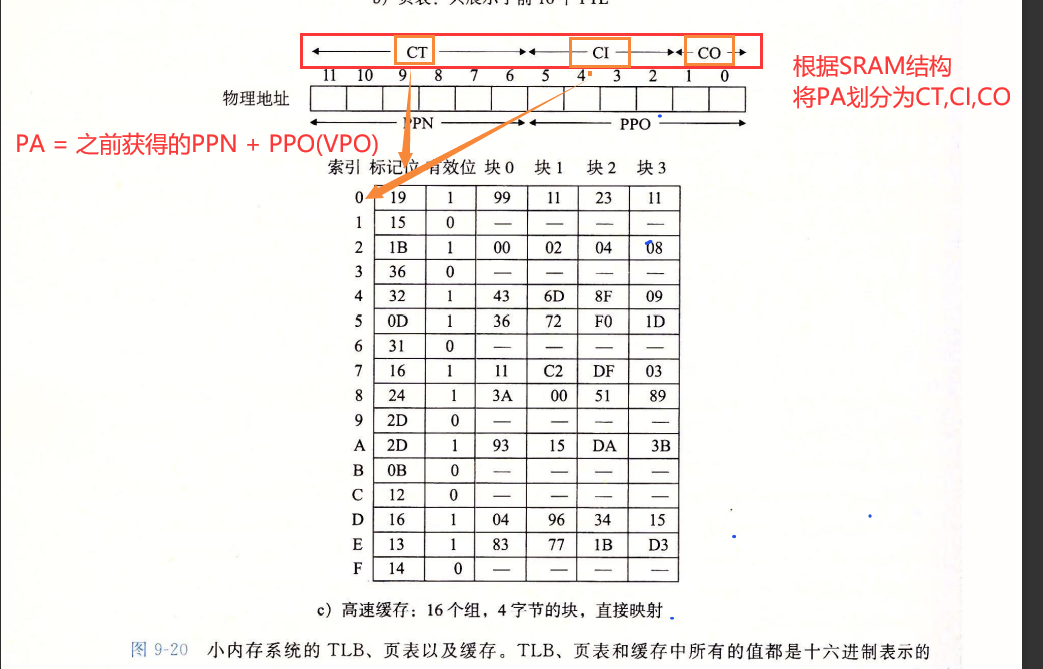
cpu执行一条读地址0x03d4处的字节的加载指令时
- VA
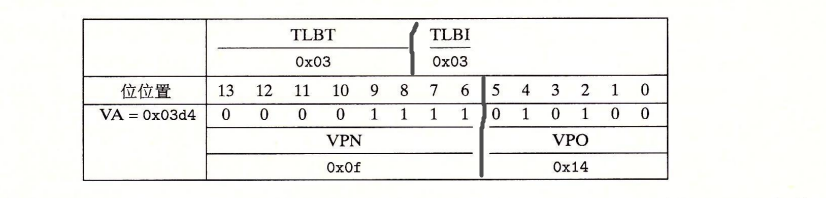
- MMU —VPN 0x0f(TLBT=0x03,TLBI=0x03)—> TLB HIT,PPN = 0x0D
- PA = PPN 0x0D + VPO 0x14 = 0x354
- PA
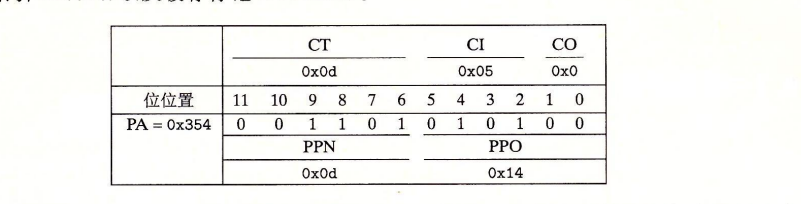
- 访问SRAM,CI=0x05,CT=0x0d,CO=0x0. SRAM HIT。return 0x36 to CPU
- VA