Linux 内存系统
memory map 内存映射
Linux 内存系统
Linux 地址翻译
结构

L1-d-TBL 和 L1-i-TLB 这些SRAM中缓存的PTE,是为了防止TLB中找不到相应PTE地址翻译过程 注意到是四级页表层次结构

- 加速技巧
由图易知:x64 是 48位虚拟地址 ,52位物理地址
PTE格式
- level 1-3
- 每个PTE引用一个4KB的子页表(下一级的page table)
- 组成:page table physical base addr(下一级页表的基地址) + permission bits

- level 4
- 每个PTE引用一个4KB的虚拟内存(实际上存的是DRAM的物理地址)
- 组成:page physical base addr + permission bits
- 所存的 page physical base address 就是 PPN
- 这个PPN是一个DRAM的页面基地址(physical page 的 base addr),这个页面,cached了一个虚拟内存(位于disk)里的VM的内容。
- 所以称,每个PTE引用了一个4KB的虚拟内存。(是指其指向的DRAM的地址的内容是cached的磁盘虚拟内存上的内容)

- PTE的三个权限位
- R/W:页的内容只读/读写
- U/S:是否可以用户模式访问(保护kernal的代码和数据不被用户程序访问)
- XD:禁止从本页取指令(通过限制只能执行只读代码段,防御缓冲区溢出攻击)
- A:引用位(reference bit),用于实现页面替换算法
- D:修改位/脏位(dirty bit)
- level 1-3
MMU如何通过四级页表将VA翻译成PA

Linux 虚拟内存系统
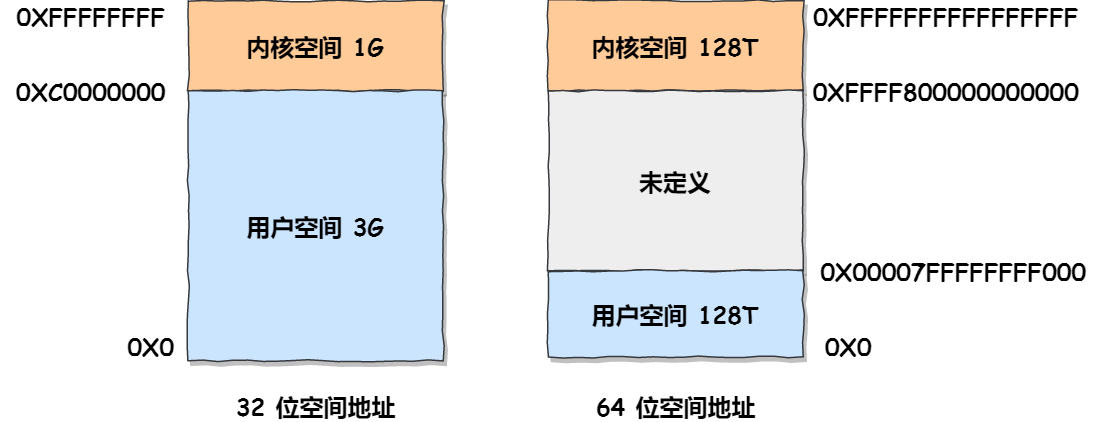
Virtual Address Space 虚拟地址空间
Virtual Address Space of a Linux Process 一个Linux进程的虚拟地址空间(我觉得不应当叫虚拟内存,你看英文就不这么叫。或者应该叫进程的虚拟内存也不错。)

- 每个进程共享内核代码和数据结构(Kernel code and data),所以内核虚拟地址空间的这个区域被map映射到所有进程共享的物理页面PP
- 内核虚拟地址空间的其他区域包含每个进程都不相同的数据,
- page table页表,kernal stack内核在上下文执行代码时使用的栈,task and mm structs 记录虚拟地址空间当前组织的各种数据结构。
32位和64位的地址空间
Linux Organizes VM as Collection of “Areas”
- Linux 以 区域(也叫做段) 的形式 来管理 虚拟内存(已分配的虚拟地址空间),并把虚拟内存(已分配的虚拟地址空间)作为 区域 的集合
- 一个区域(area)就是已经存在着的(已分配的)((我认为)但是不一定已经要加载入DRAM中的)的虚拟内存的连续片(chunk),这些页以某种方式相关联。
- 如,.text段,.data段,.bss段,堆,共享库段,以及用户栈都是不同的area区域。
- 每个存在的虚拟页面都保存在某个区域中,而不属于某个区域的虚拟页是不存在的,并且不能被进程引用。
- area的概念很重要,因为它允许虚拟地址空间有间隙。内核不用记录那些不存在的虚拟页,而这样的页也不占用内存、磁盘或者内核本身的任何额外资源。
kernel通过task_struct中的mm_struct来组织进程的虚拟内存。

- task_struct:kernal为os的每个progess维护一个单独的任务结构,其中元素包含内核运行该进程所需的所有信息
- 一直说的PCB、PCB。所谓的PCB,就是这个task_struct
- mm_struct:描述当前虚拟内存状态
- pgd:level 1 page table地址
- vm_area_struct 区域结构
- vm_strart:区域的起始处
- vm_end:区域的结束处
- vm_prot:区域内所有页的读写权限
- vm_flags:这个区域内的页面,是与其他进程共享还是私有
- vm_next:指向链表中下一个区域的结构
- 当内核运行某进程时,就将其pgd放在CR3。
- task_struct:kernal为os的每个progess维护一个单独的任务结构,其中元素包含内核运行该进程所需的所有信息
以上这些所谓的组织虚拟内存,这些都是软件上的,逻辑上的,都是虚拟的,都是Virtual Address Space中的,并没有涉及到MMU将VA翻译成PA的过程,还没走到那里。
vm_area_struct的区域创建了,就代表这那部分虚拟地址空间(虚拟内存)应该有东西,但是实际上那部分东西究竟有没有载入dram,并不知道。
- 如果没有,那么会触发page fault中断,将disk上的相应内容cache入dram
- 如果有,那么就引用就行了。
- ps:mm_struct的具体成员


- 所谓的一直说的进程控制块PCB Progess Control Block,在Linux下的实现就是task_struct结构体
Linux Page Fault Handling Linux缺页异常处理
缺页分三类
- Segmentation fault 段错误 : 访问一个不存在的页面
- Protection exception 保护异常 : 违反许可,写一个只读的页面
- Normal page fault 正常缺页 : 可以访问该虚拟页面,但是虚拟页面所映射的虚拟内存,还没有加载到DRAM中,需要加载进来。
MMU翻译某个虚拟地址A时,触发了缺页异常。于是控制转移到kernel的page fault handler。之后
1. 虚拟地址A是合法的吗?
- 也即,A在某个vm_area_struct定义的区域内吗?
- handler遍历链表,搜索所有start和end。若不合法(也即不在),那么触发一个Segmentation fault段错误。
- 这种情况就是连malloc还没malloc,连虚拟页面都没有.
2. 试图进行的内存访问是否合法?
- 也即,进程是否有读、写或者执行这个区域内页面的权限。
- 如 用户模式的进程试图从内核虚拟内存中读取字造成的缺页;又如,对只读页面进行写操作的存储指令造成的缺页。
- 那么,触发一个 Protection exception 保护异常
3. 此时,内核知道了这个缺页是由于对合法的虚拟地址进行合法的操作造成的
- 那么,选择一个牺牲页,如果修改过,就交换出去,换入新的页面并更新页表。handler返回时,cpu重新执行引起缺页的指令。该指令再次将A发送到MMU。这次MMU能正常的翻译而不缺页。
Memory mapping 内存映射
- Memory mapping : VM areas initialized by associating them with disk objects.Linux将虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容.这个过程,被称作内存映射.
映射对象
- 虚拟内存区域可以映射到的两种类型的对象
- Regular file on disk Linux文件系统中的普通文件
- 一个区域可以映射到一个普通磁盘文件的连续部分(e.g., an executable object file)
- Initial page bytes come from a section of a file(文件区被分为页大小的片,每一片包含一个虚拟页面的初始内容)
- 因为按需页面调度,所以这些虚拟页面没有实际交换进入DRAM,直到CPU第一次引用到页面(即发射一个虚拟地址,落在地址空间这个页面的范围之内).如果区域比文件区要大,那么就用0填充这个区域的余下部分.
- Anonymous file (e.g., nothing) 匿名文件
- 匿名文件由内核创建,包含的全是二进制0
- 当cpu引用匿名文件时,调度页面时,用二进制0覆盖victim,并更新页表 ,标记为常驻内存
- 页面调度时,disk和dram没有任何数据传送.
- Once the page is wriken to (dirtied), it is like any other page
- Regular file on disk Linux文件系统中的普通文件
Swap File 交换文件
- Dirty pages are copied back and forth between memory and a special swap file.
- dirty page : 一个被初始化过的虚拟页面
- swap file 交换文件 也叫做 swap space 交换空间 或者 swap area 交换区域
- 任何时刻,swap file 限制着当前运行得进程能够分配的虚拟页面的总数
- 我认为 我感觉 这个swap file 就是磁盘上的那片虚拟内存吧
Sharing Revisited: Shared Objects 共享对象
COW实现?
共享对象 应该就是 共享库(shared library)的实现原理吧
内存映射提供了一种清晰的机制,用来控制多个进程如何共享对象.
一个对象可以被映射到虚拟内存的一个区域,要么作为共享对象,要么作为私有对象.
- 作为共享对象 : 一个进程对这个区域的任何写操作 , 也会反映到这个共享对象映射到的其他进程 . 并且,也会反映在磁盘上的原始对象上.
- 一个映射到共享对象的虚拟内存区域称为共享区域
- 作为私有对象 : 对四有对象映射到的区域作出的改变,对其他进程是不可见的,也不会反映在磁盘上的对象中 .
- 一个映射到私有对象的虚拟内存区域称为私有区域

- 一个映射到私有对象的虚拟内存区域称为私有区域
- 即使对象被映射到了多个共享区域,物理内存也只需要存放共享对象的一个副本.
- 作为共享对象 : 一个进程对这个区域的任何写操作 , 也会反映到这个共享对象映射到的其他进程 . 并且,也会反映在磁盘上的原始对象上.
COW 写时复制 copy on write:延迟私有对象中的副本直到最后可能的时刻,充分利用DRAM
- 映射private object的进程,其相应私有区域的PTE标记为read only
- 且,其相应的area区域结构被标记为私有的写时复制

- Instruction writing to private page triggers , 触发异常
- handler会在DRAM种创建这个私有对象的页面的一个新副本,更新页表条目指向这个新的副本,然后恢复这个页面的可写权限.
- 控制返回到触发异常的指令,重新执行.

Fork
fork实现? 共享了什么? 什么不共享?
VM虚拟内存 and memory mapping内存映射 explain how fork provides private address space for each process.
fork被当前progess调用时
- To create virtual address for new new process
- Create exact copies of current mm_struct, vm_area_struct区域结构, and page tables页表
- Flag each page in both processes as read-only — 每个页面的都标记位为只读(因为要实现COW)
- Flag each vm_area_struct in both processes as private COW — 两个进程中的每个区域结构都标记位私有的写时复制
- On return, each process has exact copy of virtual memory (和刚调用fork时存在的虚拟内存相同的副本)
- Subsequent writes create new pages using COW mechanism
- 因此,也就为每个进程保持了私有地址空间的抽象概念
- To create virtual address for new new process
execve


加载器如何工作?
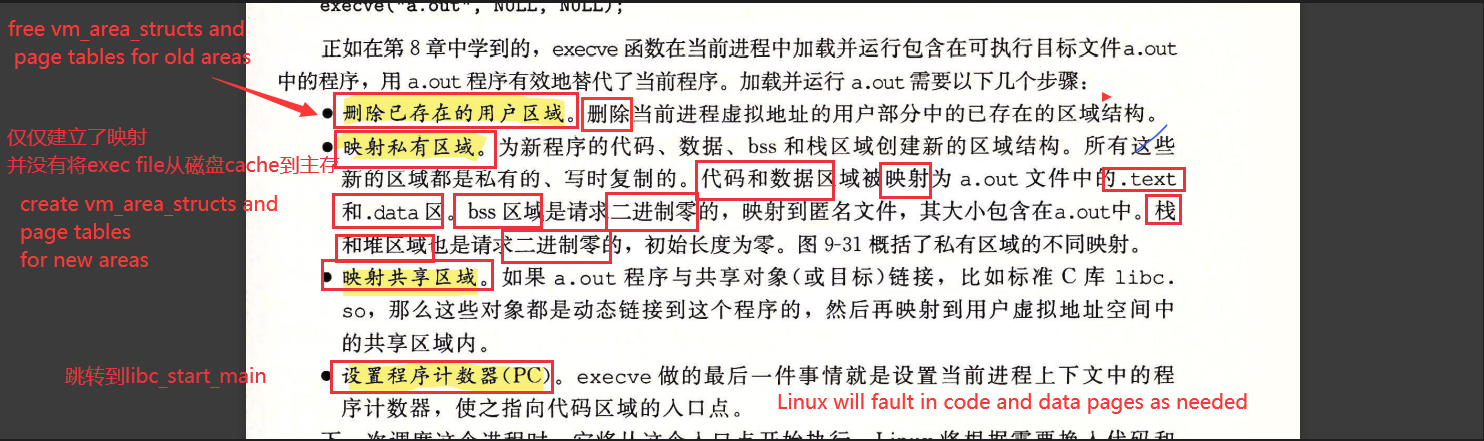
execve("a.out",NULL,NULL)在当前进程中加载并运行包含在可执行文件a.out中的程序。将executable file a加载进内存。步骤如下
删除已经存在的用户区域;
映射私有区域;
映射共享区域;
设置PC
main开始执行时的用户栈结构
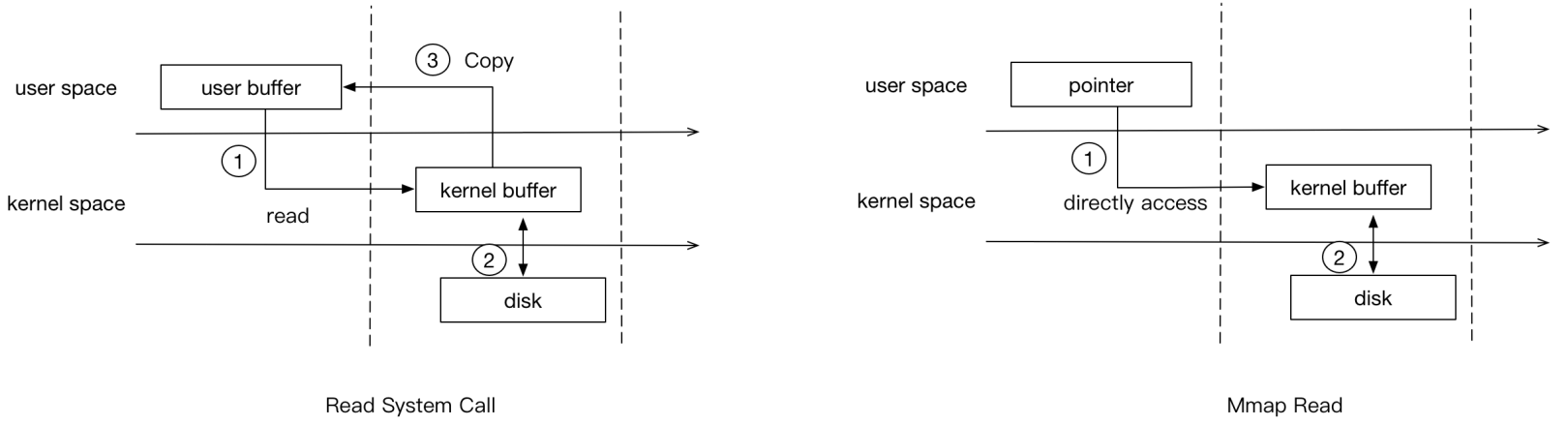
User-Level Memory Mapping : mmap 用户级内存映射
read: disk —data—> kernal —data—> user
mmap:disk —data—> kernal —映射到user的虚拟地址空间
mmap不必从内核缓冲区拷贝到用户缓冲区,减少了一次数据拷贝,但是上下文切换次数没减少.(os的内核和用户空间不需要进行任何数据拷贝)
mmap要求创建一个新的虚拟内存区域,最好是从start开始的一个区域,并将fd指定的对象的一个连续的片(chunk)映射到这个新的区域.
1
2
void *mmap(void *start,size_t length,int prot,int flags,int fd,off_t offset);Map len bytes startng at offset offset of the file specified by file description fd, preferably at address start
start : NULL
length : 连续的对象片的大小字节
offset : 从文件开始处偏移量为offset字节的地方开始
prot : 新映射的虚拟内存区域的访问权限位
- PROT_EXEC : 这个区域内的页面可以由被CPU执行的指令组成
- PROT_READ : 这个区域内的页面可读
- PROT_WRITE : 这个区域内的页面可写
- PROT_NONE : 这个区域内的页面不能被访问
flag : 被映射对象类型的位
- MAP_ANON : 被映射对象是一个匿名对象
- MAP_PRIVATE : 被映射对象是一个私有的,写时复制的对象
- MAP_SHARED : 共享对象
return: Return a pointer to start of mapped area (may not be start)

munmap : 删除虚拟内存的区域
- 删除从虚拟地址start开始,由接下来len字节组成的区域area
- 也即,删掉了这个vm_area_struct结构
1
2
3int munmap(void *start,size_t len);
success : return 0
error : return -1
我认为:malloc在分配内存的时候,就是创建了几块虚拟页面组成的区域vm_area_struct,并且改变虚拟页面相应PTE,使其指向磁盘上的相应字节。还并没有建设从va到dram中pa的映射,也没有把dram中的physical memory分配给该进程 / 该进程的的user pgtbl 也不知道需要从va到pa建立映射
- 我认为:mmap在映射内存时,就是将虚拟地址空间里的页面和磁盘上的文件的字节关联了起来,之后在第一次引用这些虚拟内存页面时,发现dram中并没有缓存disk上的这些字节,因此再将disk中的字节换入dram中,改变PTE使其指向dram中的相应physical page
- 如何将虚拟内存页面和磁盘上的文件的字节关联起来?
- 创建了几块虚拟页面组成的区vm_area_struct,并改变了pagetabel上virtual page相应的PTE,使其指向磁盘上相应的文件。
Summary

一开始只是建立了映射,进程逻辑上的虚拟地址空间里的虚拟页 映射到了 磁盘上的字节(虚拟内存)
(也可称之为进程1的虚拟内存映射到了磁盘上),然后,由于按需页面调度,在第一次引用这个虚拟页的时候,磁盘上的字节会被cached到DRAM中,之后,这个虚拟页的VA所对应的PTE的PA,就是DRAM保存相应内容的PP地址。之后就这么通过VA直接找PA存的内容就行。
虚拟内存系统 页面调入调出作用
就是 告诉cpu每个进程 你在你所想象的虚拟地址空间里拿什么地址的内容都行 我都有
实际上 有大部分地址的内容都没有在内存中,还在磁盘里躺着
但是,当引用到了这部分内容时,VM系统会将磁盘里的相应内容,调度入DRAM
再将这部分内容返回给cpu(由于局部性,不会不断地换入换出,还挺高效)
这样,从cpu/用户的角度来看,我想要什么地址的内容,就能拿到什么地址的内容
尽管,我所引用的地址,是虚拟的,但我不在乎,我甚至不用知道。
因为VM系统(MMU地址翻译)会将我所发射的VA转化成PA,并为我取得相应内容。
至于从哪里取得,disk还是dram,用户/cpu不在乎。我能拿到data就可以。
虚拟内存是一块字节序列?字节存储在磁盘上?
对 是在磁盘上
虚拟内存三大元件:
物理内存(DRAM)
页表 (DRAM)
虚拟内存(磁盘)
所谓虚拟内存无非就是一种缓存机制嘛。通过页表 检查我们所需的虚拟内存的相应页面所对应的磁盘内容,是否已经被缓存入物理内存中。
虚拟地址空间可以说就是页表吧
【潜水】grey 20:24:02
百度面试就让写多线程
【潜水】grey 20:24:04
打印
【潜水】grey 20:24:08
都忘光了
【潜水】grey 20:24:24
还问问完cpp11 thread 再问pthread



》 TODO
https://www.bilibili.com/video/BV1iW411d7hd?p=17&vd_source=7cf747b91a297d9a0c8581a26188dd95&t=1962.6

……..:
感觉就是 听感觉没啥,一个新系统让你实际 一脸懵, 我就感觉细节还是很重要的,像之前看的一个时间轮实现定时器和堆实现定时器 ,为什么时间轮可以在海量并发下实现定时 而堆排序却不行
……..:
看到明白了 时间轮时间复杂度数据量增加也是O(1)级别 堆而言的时间复杂度O(logn) 数据量越多 并发越差 此时设计在优化
不到叫啥名:
请问下xdm 6824需要学什么前置的课程吗
……..:
还有就是那个 跳表结构为什么支持高并发 但是我一直不明白 他是如何控制锁粒度去实现的
MORE
- task_struct结构体
- linux-5.6.18\include\linux\sched.h
1
2
3struct task_struct {
...
}
- linux-5.6.18\include\linux\sched.h