关于queueInLoop调用时机
疑问
在看muduo源码时,始终有这个困惑:runInLoop和queueInLoop真的有必要分开吗?
首先 eventloop的loop中
1
2
3
4
5
6while(1)
{
poller wait
handleEvents
doPendingFunctors
}如下所示
runInLoop
- loop 所属 thread 内执行 runInLoop :
- 必然是在handleEvents中,调用了runInLoop,此时处于LoopThread内,于是在io thread内直接执行cb。
- 其他 thread 执行runInLoop :
- 进入queueInLoop,把cb加入到pendingFunctor中。为了让io loop尽快执行我们的cb,于是我们wakeupFd。
- loop 所属 thread 内执行 runInLoop :
queueInLoop
- loop 所属 thread 执行queueInLoop
- handleEvent中调用queueInLoop
- 加入pendingFunctor,但无需wakeup。因为IO thread已经从Poller中离开,handleEvents之后就会执行cb。
- doPendingFunctors
- 加入pendingFunctor,且需要wakeup。因为这个cb直到下次poller wait之后 才会被处理。(通过callingPendingFactors_判断是否需要wakeup)
- handleEvent中调用queueInLoop
- 其他thread 执行queueInLoop : cb放入队列,为了让io loop尽快执行我们的cb,于是我们wakeupFd。(这样下次IO thread运行到poller wait就会直接返回,如果不这样的话cb会被延迟处理)
- loop 所属 thread 执行queueInLoop
code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 让loop对象执行回调函数cb
void EventLoop::runInLoop(const Functor& cb)
{
// 如果用户在当前(EventLoop所属线程)IO线程调用这个函数,回调会同步进行
if(isInLoopThread())
{
cb();
}
// 如果不在 那么放入队列
else
{
queueInLoop(cb);
}
}
// 把cb放入队列 以待下次从poller wait中出来后执行cb
void EventLoop::queueInLoop(const Functor& cb)
{
// 给loop添加新回调
// 这个cb 会在loop的IO thread的epollwait之后 被调用
{
std::lock_guard<std::mutex> lock(mtx_);
pendingFunctors_.emplace_back(cb);
}
// 只有当前queueInLoop()函数是被 loop所属的IO thread handleEvents 中被调用,才无须wakeup()
if(!isInLoopThread() || !callingPendingFactors_)
{
wakeup();
}
}可见 也没什么区别,貌似全部都用runInLoop也未尝不可。
但是,在muduo中,起码在我所看到的源码中,只在writeCompleteCallback和highWaterCallback的调用时,使用了queueInLoop
1
2
3loop_->queueInLoop(
std::bind(highWaterMarkCallback_,shared_from_this(),oldlen + remaning)
);为什么要在这里使用?
解决
首先介绍highWaterMarkCallback和writeCompleteCallback使用姿势。这两个是由user设置的。user设置给TcpServer,TcpConnection从TcpServer中取用这两个函数
- 考虑一个代理服务器有C和S两个链接,S向C发送数据,经由代理服务器转发,现在S的数据发送的很快,但是C的接受速率却较慢,如果本代理服务器不加以限制,那S到来的数据迟早会撑爆这C连接的发送缓冲区,
- 解决的办法就是当C的发送缓冲中堆积数据达到了某个标志的时候,调用highWaterMarkCallback去让S的连接停止接受数据,等到C发送缓冲的数据被发送完了,调用writeCompleteCallback再开始接受S连接的数据。这样就确保了数据不会丢失,缓冲不会被撑爆。
那么为什么这两个回调要queueInLoop先放入队列再执行呢?原因如下
比如如果用户如果想在writeCompleteCallback中发送data,
如果是queueInLoop的话,那么
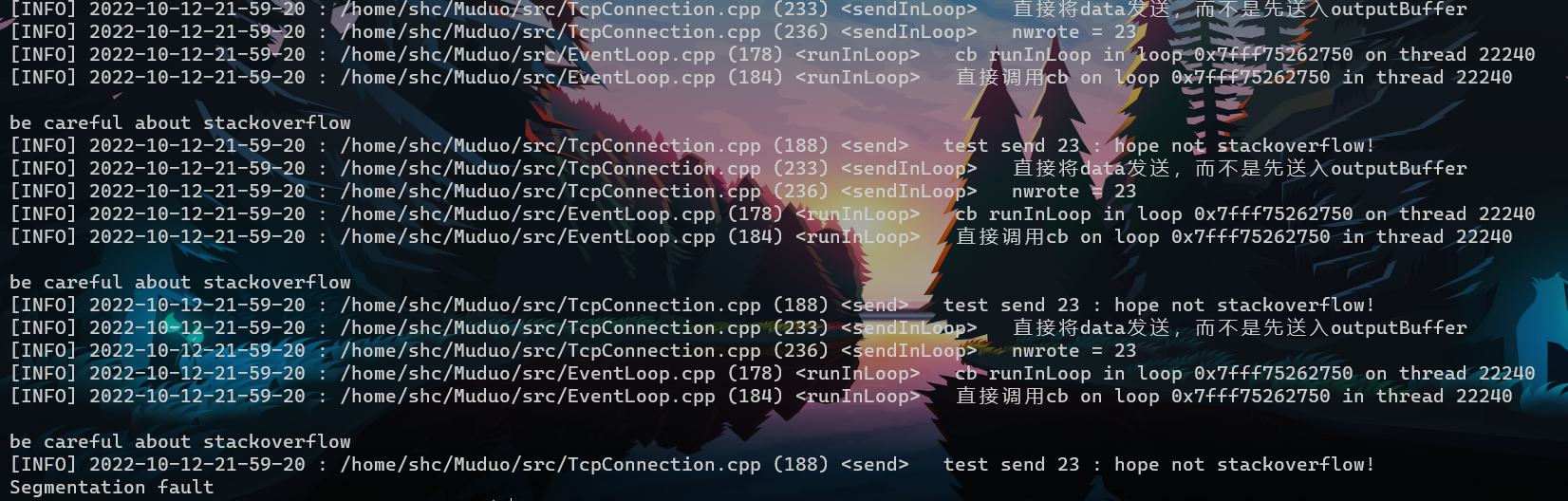
- queueInLoop加入cb到队列,会等下次从poll返回之后执行doPend的时候才执行。下一轮cb中send的才会调用,而后又会触发下一轮调用的cb。不会造成busy loop,也不会seg。
如果是runInLoop的话,会发生什么?
- 会不断调用send 和 callback 导致 seg。
- 原因如下:
- 在IO线程中调用runInLoop,这个cb会立刻执行
- writeCompleteCallback_会在TcpConnection::send() 发送干净数据之后,会调用writeCompleteCallback。而writeCompleteCallback中又一次调用TcpConnection::send(),将msg发送干净之后,又会触发callBack…
- 这样不断相互触发,导致seg。
- 错误使用write call back代码server
1
2
3
4
5
6
7void onWriteComplete(const TcpConnectionPtr &conn)
{
// as soon as send finished
printf("be careful about stackoverflow\n");
string msg("hope not stackoverflow!");
conn->send(msg);
}
client