地址映射关系 即 va -> pa 的 映射
在做本实验之前,xv6的虚拟内存机制如下
- 对于kernel , 内核只有一张全局的kernel pagetable. 所有kernel thread 共用这一张pagetable. 通过MMU使用.
- 对于user , 每个user process的user thread 有一张user pagetable. user通过MMU使用.
- 但对于user传入kernel的va,kernel该如何使用user pgtbl来进行寻址呢 ? kernel 通过软件模拟(walkaddr)来查询user pgtbl 来进行user va的寻址.
- 很显然,效率很低 不如硬件. 现代操作系统采用的也并非是这种机制.
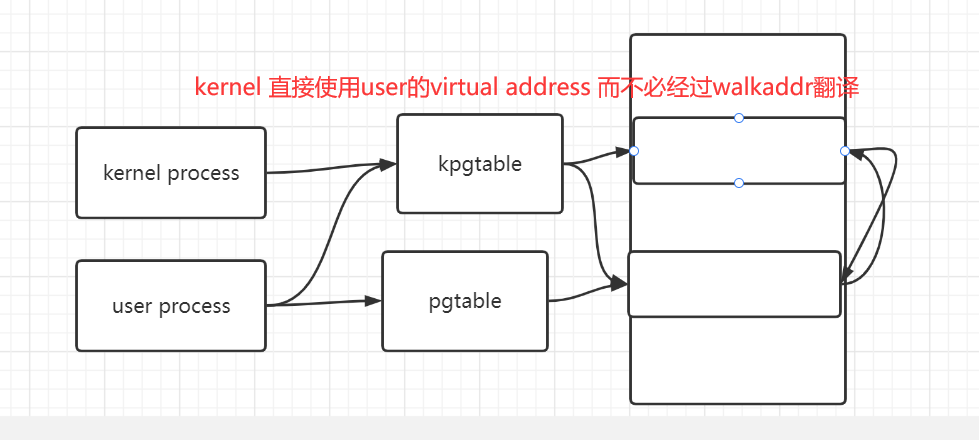
本实验 : 那么 为了让kernel可以直接通过硬件MMU来使用user pagetable. 我们实现如下措施
- (以下就是所谓的将内核页表和用户页表合并)
- 为每一个process的kernel thread 都 分配一个 pagetable.
- 且在这个kernel thread pgtable
- 不但维护了kernel 的地址空间映射
- 2. 还要 维护user thread的user pgtable的地址空间的映射(va->pa)
- 对于1. 我们应当 为 每个kernel thread pgtbl建立和 全局 kenrel pgtbl 基本一样的地址映射关系 (kvminitproc)
- 对于2. 我们应当 将user thread pgtbl 的维护的地址映射关系 拷贝到 kernel thread pgtbl 的 [0,0XC00..00-1]处
- 并在 user thread pgtbl 的地址映射关系发生改变时(pte的增加/删除/修改),即时拷贝到kernel thread pgtbl上
- 合并之后,kernel 使用 user va的方式 就是 直接通过MMU在kernel thread pgtbl的user部分进行查询. 而不用通过walkaddr,提高效率
- (以下就是所谓的将内核页表和用户页表合并)
下图就是一个合并user部分后的kernel thread pgtbl
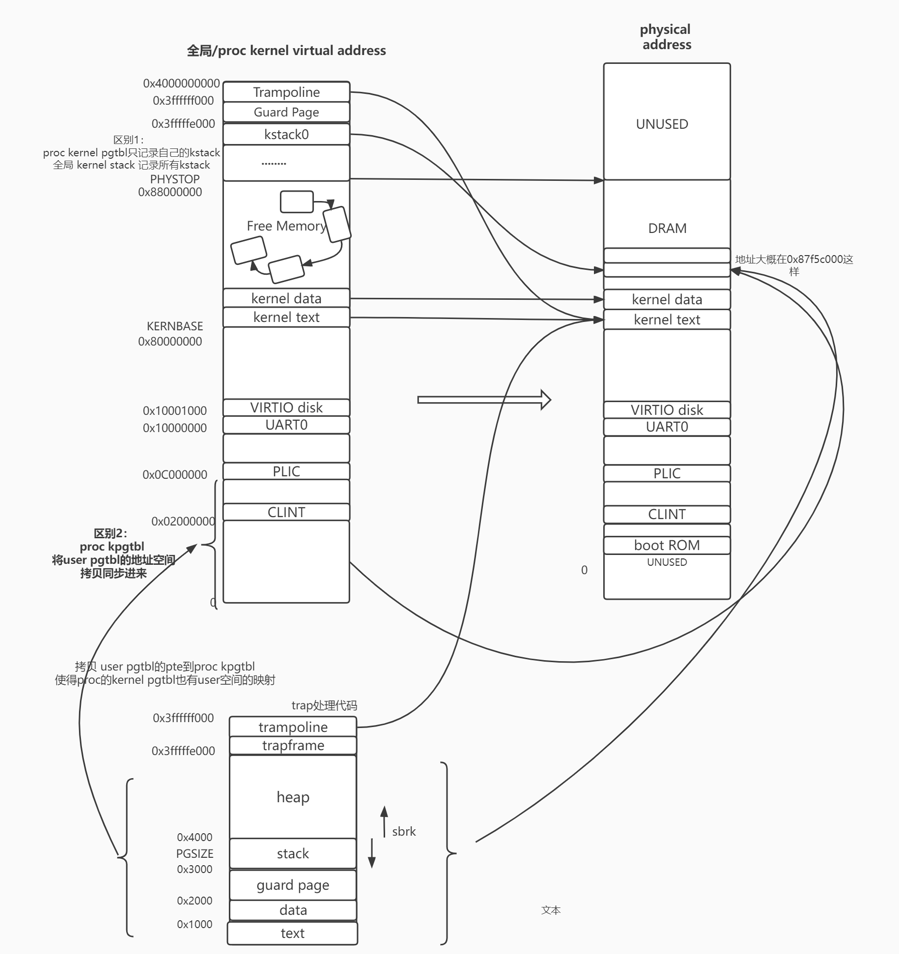
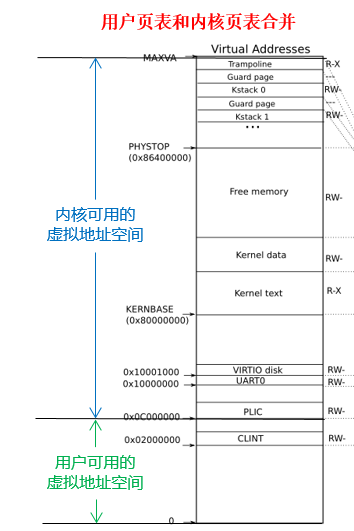
本实验后,xv6的虚拟内存机制如下
- 3个pgtbtl
- 全局 kernel pgtbl (kernel的scheduler thread用)
- user thread pgtbl (user thread用)
- kernel thread pgtbl(包含user部分) (kernel 用)
- 主流的OS也是用这种方法.
- 3个pgtbtl
关于 vm.c 注释见文
关于虚拟内存是否连续见文末
part 1
- 简单递归
- 对于PTE,当PTE_V=1时,代表着该PTE有效。
- 对于非叶子pte,代表整个pte指向下一级pgtbl,且可以被使用。
- 对于叶子pte,也即其所指向的physical page 有效的physical page,所谓有效,也即该pagetable建立了从virtual address 到这个 physical page的映射,也即这个physical page 归本pgtbl所有。
- 当PTE = 0时,意味着本PTE第一次被使用,故其也没有指向下一级页表或是物理页。
- 核心code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void vmprint(pagetable_t pagetable,int depth)
{
if(depth > 2) return ;
// pagetable = 512 ptes = 512 uint64 = 512 * 8 bytes = 4096 bytes
for(int i=0;i<512;++i)
{
pte_t pte = pagetable[i];
if(pte & PTE_V)
{
uint64 next = PTE2PA(pte); // nextlevel_pagetable_or_mem_pa
printf("%d: pte %p pa %p\n",i,(void*)pte,next);
vmprint((pagetable_t)next,depth+1);
}
}
return ;
}
- 核心code
part2 :独立内核页表
独立内核页表
- 我们需要 将共享内核页表改成独立内核页表 ,使得每个进程拥有自己独立的内核页表。
在这一部分,仅仅是让每个process有自己的kernel pagetable,但实际上,在这里,对于该proc的kernel page table,使用的方法都是和之前全局的kernel pagetable一样的。
proc.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack // kernel stack 不是直接映射
uint64 kstack_pa; // kernel stack的physical address
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
pagetable_t kpagetable; // kernel page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
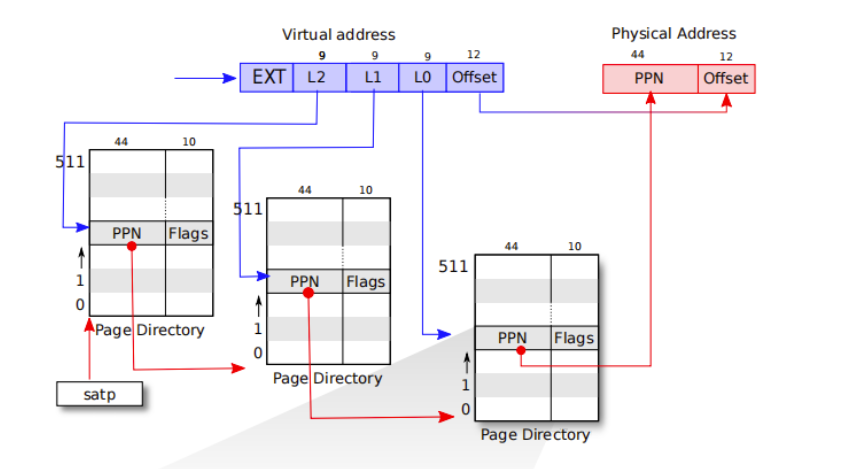
RISCV PGTABLE结构
三级页表
PTE结构
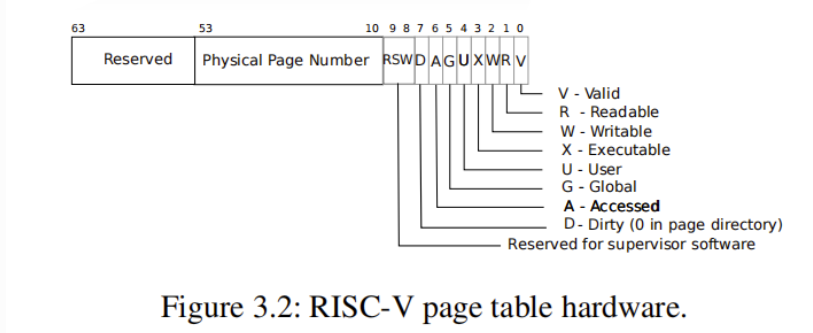
- PTE分为两部分:物理地址页帧号和标志位。具体的结构如上图。
- 保留位:第54-63位,共10位。
- PPN: 物理页帧号,第10-53位,共44位。
- Flags:标志位,第0-9位,共10位。其中第8-9位为保留位,暂不使用。
- 第0位 Valid:该页表项有效。对于叶子页表来说,这个位置为1说明虚拟地址有映射到物理地址,否则说明没有该映射。对于次页表来说,为1说明有对应的叶子页表,对于根页表说明有对应次页表。
- 第1-3位 Readable/ Writable/ Executable: 该页表项是可读/写/执行(作为代码运行)的。通常我们只需要关心叶子页表项的这三个位,因为这代表对应的物理页帧的标志,而不是页表的标志。对于根页表和次页表的目录项,这三个位往往置为0。
- 第4位 User: 该页表项指向的物理页能在用户态访问。内核页表中的代码和数据我们不会将其给用户使用,所以会置0,但是用户页表的代码和数据应该要置1。同样,对于内核页表中的页表项,如果该位置1,则计算机的硬件不会允许内核访问对应地址,但可以通过其他的手段访问,后文会介绍。
- 其他位,查阅riscv-privileged.pdf 4.3~4.4
关键问题
问题:proc的kernel pagetable都需要映射什么?
- 在本部分,与全局kernel pagetable的不同之处在于
- 只需要映射自己proc的kernel stack
- 不需要映射CLINT
- 实际上,在下一部分完成后,proc kernel pagetable的PLIC之下,还需映射到proc user pgtbl维护的地址空间(即user虚拟地址指向的物理地址)
- 详情见下一部分。
- 本部分只是负责建立一个不完全proc的kernel pgtbl,并替代全局kernel pgtbl,并不改变其他机制。
- 在本部分,与全局kernel pagetable的不同之处在于
一个进程到底是什么?
- 感觉就是一堆上下文和代码。。
为什么要保留初始内核页表?
- 保留原有的全局 kernel pagetable
- 因为cpu上不是一直都在执行用户进程。当执行用户进程之前,需要切换成user的kpgtbl;执行结束后,需要切成全局的kpgtbl。因为user的kpgtbl此时可能已经在freeproc函数中被释放,如果继续使用user的kpgtbl,会crash。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
// 切换进程的同时 切换成proc的kernel pgtbl
kvminithartproc(p->kpagetable);
// 运行p进程
swtch(&c->context, &p->context);
// 没有user进程运行时 即 运行scheduler时 换回全局kernel pgtbl
kvminithart();
// Process is done running for now.
// It should have changed its p->state before coming back.
// cpu dosen't run any user process now
c->proc = 0;
}
release(&p->lock);
}
流程
Step 1 :proc中新添 pagetable_t kernel_pagetable 以及kstack_pa
- 属于proc的kernel pagetable
- kernel stack的物理地址
Step 2 :实现 pagetable_t kvminitproc()。
- 模仿kvminit,创建进程的内核页表,并建立除了CLINT之外的映射。
Step 3 :修改procinit。
- procinit():系统引导时(见kernel/main.c的main函数),用于给proc分配kernel stack的physical page 并在全局kernel pgtbl建立映射。
- 记录下kernel stack的physical address。为了之后allocproc分配进程创建proc kernel pagetable时,在proc kpgtbl中建立kernel stack的映射。
Step 4 :修改allocproc。
- allocproc何时被调用?
- 在系统启动时被第一个process 和 fork 调用
- allocproc功能
- 在进程表proc数组中查找UNSUEDPCB,
- 如果找到,
- 创建用户页表初始化在内核中运行所需的状态trapframe,user pagetable , kpgtable , 处于forkret的上下文等,并保持p->lock返回。
- 如果没有PCB,或者内存分配失败
- return 0
- 如果找到,
- 在进程表proc数组中查找UNSUEDPCB,
- 创建proc的kpgtbl,并在其中建立该proc的kstack的映射。
- 只是把本proc的kstack在全局的kernel pgtbl的映射又在proc的kernel pgtbl上又做了一次。virtual address 和 kernel address 都是一样的
- 之前记录kstack_pa就是为了在这里建立映射。
- 虚拟地址也是之前创建kstack时记录下的p->kstack
1
2
3
4
5p->kpagetable = kvminitproc();
// 映射kstack
kvmmapproc(p->kpagetable,p->kstack,p->kstack_pa,PGSIZE,PTE_R | PTE_W);
// 此时user pgtbl 除了trapframe和trampoline之外还没有section 无需同步 user kernel pgtbl
// 也即0xC000000之下 user pgtbl没有建立va-pa
- allocproc何时被调用?
Step 5 :scheduler 切换进程的同时切换pagetable。没有用户进程的时候切回全局kernel pgtbl
1
2
3
4
5kvminithartproc(p->kpagetable);
// 运行p进程
swtch(&c->context, &p->context);
// 没有user进程运行时 即 运行scheduler时 换回全局kernel pgtbl
kvminithart();Step 6 :进程结束时,释放proc的kpgtbl,但不释放其映射的物理内存。因为内核的代码和数据都是唯一的。只是有很多人指向而已.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 释放以pgtbl为根节点的所有pgtbl,并将pgtbl的所有pte清0,但不释放映射到的物理内存
void freepgtblonly(pagetable_t pgtbl)
{
for(int i=0;i<512;++i)
{
pte_t pte = pgtbl[i];
// 前两级的pte
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0)
{
uint64 child = PTE2PA(pte);
freepgtblonly((pagetable_t)child); // 释放下一级pte
}
// 对于叶子pte 不必操作
}
// 释放整个pgtbl自身
kfree((void*)pgtbl);
}一遍过 yes!
part 3 :简化软件模拟地址翻译
思路
进程user态的虚拟地址 即 proc的user pgtbl维护的虚拟地址
进程内核(kernel) 态的虚拟地址 即 proc的kernel pgtbl维护的虚拟地址
全局的kernel pgtbl 即 全局的kernel pgtbl
- 在做part3之前,proc在内核态如何使用user态传递到kenerl的user virtual address – 通过walkaddr?
- kernel从user态的va读取数据:copyin ; 写入数据到user的va:copyout
- 比如在copyin的时候,如果拿到了user态的虚拟地址,如果按照之前的流程的话,需要通过copyin函数,copyin函数通过walkaddr软件模拟翻译获得user va对应的pa,再读取pa的内容,将其复制进kernel_dst对应的pa的physical memory。
- 软件模拟翻译 :
- 通过walkaddr去user pgtbl查找user va对应的pa的过程。效率低。不如MMU查找快。
- kernel_dst如何得到pa?
- 经硬件MMU查询翻译得到。不是在软件层面实现的。
- 当cpu发出这条kernel_dst后,会经MMU查询全局的kernel pagetable 翻译成pa。
- 大概意思如下
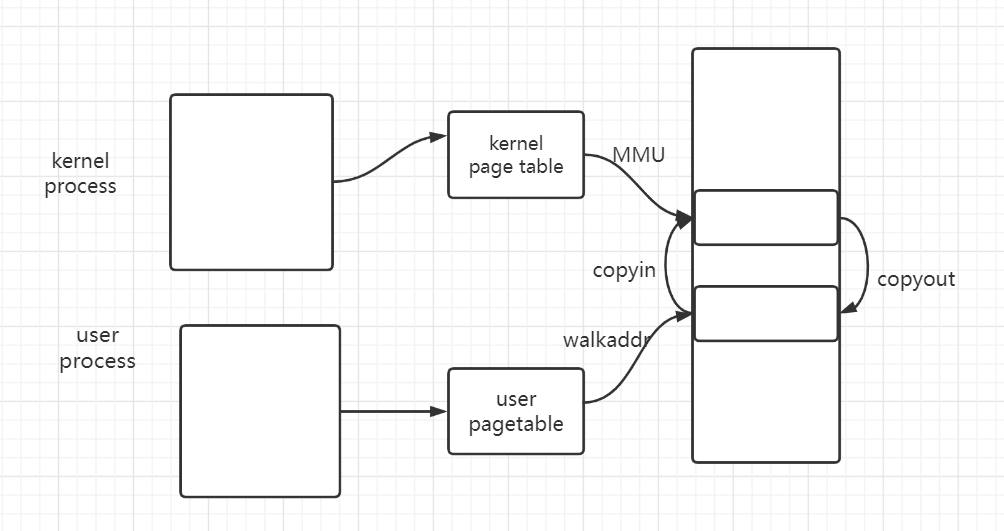
- 即便在做完part2之后,上述情况也并无差别,只是将MMU查询使用的全局的kernel pagetable替换成了proc的kernel pagetable。proc的kpgtbl和全局的kpgtbl的区别只是CLINT,不影响上述行为。
- 做完part3,如何使用user的传入kernel的va? – 直接使用
- 手段:将proc的user pgtbl所维护的从va到pa的映射,拷贝到kernel pgtbl的中。
- 这样我们在kernel的时候,比如在copyin的时候,拿到user传来的user va,我们不必去walkaddr去查询user va对应的pa,而是直接使用就好。将va到pa的翻译交给MMU。这样,user的va 直接使用,kernel的va 本就直接使用,省去了walkaddr的过程,全权交给硬件实现物理地址的翻译,提高效率。
- 因为此时cpu的$satp 是 proc的kernel pagetable。而我们又将整个user pgtbl维持的va到pa的映射关系,原封不动的搬到了proc 的 kernel pgtbl。
- 因此MMU可以使用user的va在kernel的pgtbl中找到对应的pte,得到对应的pa。
- copyin_new核心code如下
1
2
3
4
5
6
7
8
9
10
11
12// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
int
copyin_new(pagetable_t user_pagetable, char *kernel_dst, uint64 user_srcva, uint64 len)
{
struct proc *p = myproc();
// 直接使用user的srcva 而不必先去walkaddr得到pa!
memmove((void *) kernel_dst, (void *)user_srcva, len);
stats.ncopyin++; // XXX lock
return 0;
} 
实现
part3实现思路:
- 让proc的kpgtbl也维护一套user态的地址空间(拷贝并同步user pgtbl)
- 拷贝:开始,将proc的user pgtbl所维护的从va到pa的映射,拷贝到kernel pgtbl的中
- 同步:user pgtbl发生改变的时候,将 变化的pte拷贝到user pgtbl中。所谓改变,即新增pte 、删除pte、改变pte的时候。
- 具体什么函数会令user pgtbl改变?
- uvmalloc –> mappages —> walk(1)
- uvmdealloc –> uvmunmap –> kfree(pa) *pte = 0
- 但是 如果是对那块已经建立的physical memory填充字节或者读取写入之类的云云(比如copyin copyout),就不必同步kernel pgtbl,因为映射关系没变,pte自然也没有变化
- 具体什么函数会令user pgtbl改变?
step
- step1 : 将user pgtbl的pte复制到kernel中并同步变化.
- 用户页表是从虚拟地址0开始,用多少就建多少,但最高地址不能超过内核的起始地址,这样用户程序可用的虚拟地址空间就为0x0 - 0xC000000。
- 也即,在user pgtbl变化的时候,将变化同步到kpgtbl中
- 故在growproc fork userinit exec中 调用u2kvmcopymappingonly。
- 例如fork中
1
2
3
4
5if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0 || u2kvmcopymappingonly(np->kpagetable,np->pagetable,0,p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
- 例如fork中
- 还有在user pgtbl清空pte时 也要同步到kpgtbl中,也即uvmdalloc和kvmdeallocpgtblonly要配套使用。代码见growproc以及exec。
- step2 : copyin 替换为 copin_new
- step1 : 将user pgtbl的pte复制到kernel中并同步变化.
3个pgtbl
全局的kernel pgtbl
- 仅包含内核的代码和数据的虚实地址映射,用户程序的代码和数据不包含在内。
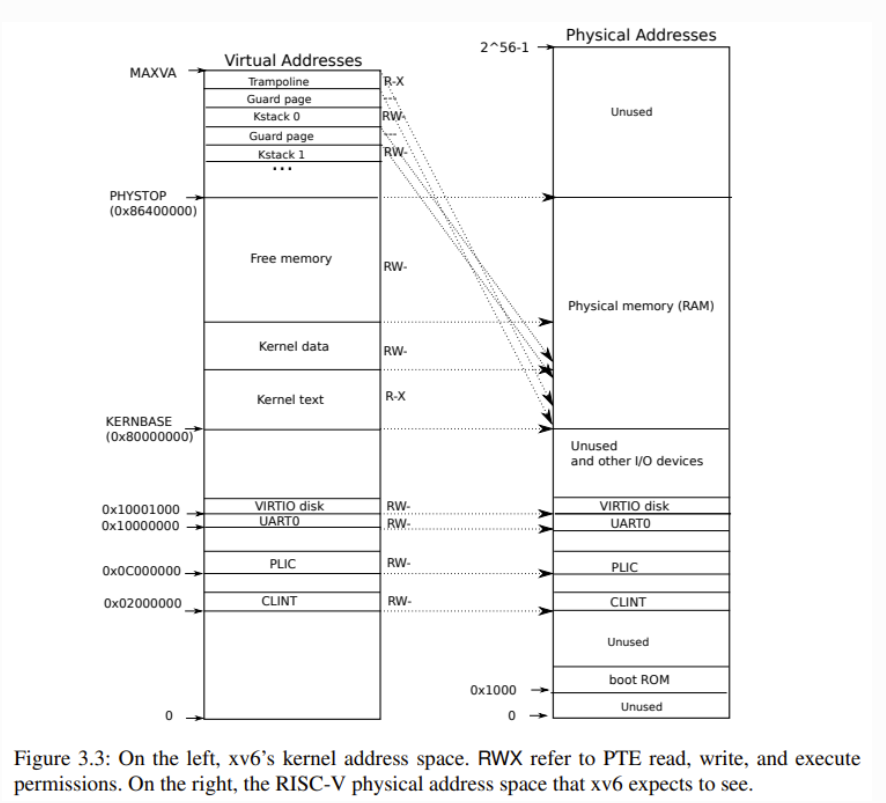
- xv6内核的大部分虚实地址映射是恒等映射,虚拟地址和物理地址是一模一样的。对于既要读写虚拟页又要通过PTE管理物理页的xv6内核来说,这样的直接映射降低了复杂性。
- 从图中,我们可以看到,有两处虚拟地址不是直接映射的:
- trampoline 页:它是用户态-内核态跳板,既被映射到内核虚拟空间的顶端,页被映射到用户空间的同样位置。
- kernel stack:每个进程都有自己的内核栈,它被映射到高位,这样在它下面可以保留一个未映射的守护页。
proc 的 user pagetable
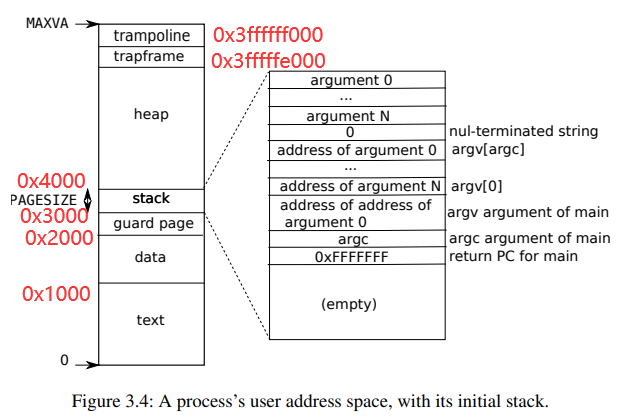
- 上图是xv6的用户程序虚拟地址空间分布。其代码实现在kernel/exec.c中,exec使用proc_pagetable分配了TRAMPOLINE和TRAPFRAME的页表映射,然后用uvmalloc来为每个ELF段分配内存及页表映射,并用loadseg把每个ELF段载入内存。
- trampoline :用户态-内核态跳板。
- trapframe:用来存放每个进程的用户寄存器的内存空间。如果你想查看xv6在trapframe page中存放了什么,详见proc.h的trapframe结构体。
- heap :堆。程序初始化时堆没有分配任何空间。用户程序可以通过sbrk系统调用调整堆分配的空间,这会把新内存映射到页表中,也可以从页表中移除映射,释放内存。
- stack:用户栈。xv6的用户栈只分配了一个页(PAGESIZE),放置在比堆更低的位置。通常操作系统会把用户栈放置在比堆更高的位置,这也是xv6和常见的操作系统做法不一样的地方。
- guard page:守护页,用来保护Stack。如果stack耗尽了,它会溢出到Guard page,但是因为Guard page的PTE中Valid标志位未设置,会导致立即触发page fault,这样的结果好过内存越界之后造成的数据混乱。
- data:用户程序的数据段。
- text:用户程序的代码段。
proc的kernel pgtbl
- 与全局kernel最重要的不同在于 只维护了自己kernel stack的地址映射,以及多维护了用户态的地址空间。
vm.c
工具函数
pte_t * walk(pagetable_t pagetable, uint64 va, int alloc)
- 遍历前两级页表,找到第三级页表,返回va对应的第三级页表的叶子PTE , 这个PTE有可能全0
- alloc == 1
- 创建遍历过程中需要遍历到的但不存在的pagetable,最后返回va对应的第三级页表的叶子PTE.如果这个pte原本是不存在的话,那么实际上返回的pte是0
- success : return pte的地址
- fail : return 0 创建失败
- alloc == 0
- 不必创建遍历过程中需要遍历到的但不存在的pagetable,如果遍历到的pte还不存在或者需要遍历的页表不存在,那么直接返回0即可。
- success : return pte的地址
- fail : return 0 所需遍历的页表不存在
- 只有当遍历到的三级页表在遍历前就全部存在,且第三级页表中的va对应的pte也之前就建立了对物理页的映射,才会得到返回有效的指向物理页的pte。
- 目前来看只有通过walk接口,才能创建三级页表。
uint64 walkaddr(pagetable_t pagetable, uint64 va)
- 根据va 去 pagetable里面查找相应的PTE , 进而得到pa。并不新增pte。也不会改变已有pte。对于pgtbl建立的映射关系没有影响。
- success : 如果查到的PTE无效 / 无权限,返回0
- fail : 如果查到的PTE有效,返回pa
- 返回的pa也只是physical page的起始addr,因为舍弃了va的低12位。
int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
- 在pagetable上(所代表的三级页表),建立从va到pa的映射。一个page一个page的建立映射,perm是指定的权限位。mappages结束后,维护va->pa的所需的页表以及pte都已经创建和初始化好。
- 建立的映射关系:[va,va+size-1] -> [pa,pa+size-1]。 使用的虚拟地址是连续的,传入的物理内存也是连续的
- 建立映射:*pte = PA2PTE(pa) | perm | PTE_V
- success : return 0;
- fail : return -1;
- 由于walk函数在创建pagetable自身的时候失败。
- mappages 不会kalloc要映射到的物理页,要映射到的物理页时调用mappages之前就准备好的。是传入的pa;但是mappages可能会kalloc所需的pagetables。
- 在pagetable上(所代表的三级页表),建立从va到pa的映射。一个page一个page的建立映射,perm是指定的权限位。mappages结束后,维护va->pa的所需的页表以及pte都已经创建和初始化好。
int test_pagetable()
- 检验当前使用的pagetable是全局的kernel pagetable 还是其他pagetable
- 通过$satp比较
- 检验当前使用的pagetable是全局的kernel pagetable 还是其他pagetable
void freepgtblonly(pagetable_t pgtbl)
- 释放以pgtbl为根节点的所有pgtbl,并将pgtbl的所有pte清0,但不释放映射到的物理内存
void freewalk(pagetable_t pagetable)
- 释放所有存在的pagetable,并且检测叶子page table上面的叶子 PTE 是否已经没有对dram的映射,如果害有对dram的映射,那么panic
- 在此之前应当先销毁整个pgtbl所建立的映射关系。(如调用 uvmunmap使得pte清0,释放映射的物理内存)
- 释放所有存在的pagetable,并且检测叶子page table上面的叶子 PTE 是否已经没有对dram的映射,如果害有对dram的映射,那么panic
关于全局 kernel pgtbl
关于全局 kernel pagetable的
void kvminit()
- 建立好direct-map kernel_pagetable 但并没有启动pgtbl
- 建立了KERNBASE之下 IO设备的映射以及kernel data . kernel text 以及trampoline的映射
void kvminithart()
- 设置cpu当前使用页表为kernel_pagetable
kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)
- 在kernel_pagetable上,建立从va到pa映射,大小为sz。建立失败则panic
uint64 kvmpa(uint64 va)
- 在kernel pagetable中 查找va对应的pa
- success : return pa (PPN + offset)
- fail : panic
- 一般在va对应的物理页并不存在或者没有建立映射时(即根据va查询到的pte所指向的物理页无效 PTE_V = 0)
- 仅仅对kernel stack的va的对应的pa进行查询时有效。因为kernel pagetable只有kernel stack不是直接映射。(其实还有trampoline,不过那是pc指向的地址了)
kernel 和 user 交互
kernel 和 user之间的数据交互 通过kernel 和user的pgtbl 以下是做lab之前
int copyout(pagetable_t user_pagetable, uint64 user_dstva, char *kernel_src, uint64 len)
- 从kernel pagetable维护的src 的内容拷贝 len bytes 到 user pagetable维护的dst
- success : return 0
- fail : return -1
- 核心代码如下,去掉了一些页对齐的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
// 从kernel pagetable维护的src 的内容拷贝 len bytes 到 user pagetable维护的dst
// success : return 0
// fail : return -1
copyout(pagetable_t user_pagetable, uint64 user_dstva, char *kernel_src, uint64 len)
{
// src是全局 kpgtbl维护的虚拟地址,其和物理地址是恒等映射的关系。因此使用src实际上就是在使用物理地址
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
// 查找user pgtbl 将va映射到的pa
pa0 = walkaddr(pagetable, va0);
// 将pa src的内容复制到pa处
memmove(pa0, src, n);
// continue
}
return 0;
}
int copyin(pagetable_t user_pagetable, char *kernel_dst, uint64 user_srcva, uint64 len)
- 从user pagetable维护的srcva 的内容拷贝 len bytes 到 kernel pagetable维护的dst
- success : return 0
- fail : return -1 . 查询srcva对应pa失败
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
int
copyin(pagetable_t user_pagetable, char *kernel_dst, uint64 user_srcva, uint64 len)
{
while(len > 0){
// 页对齐
va0 = PGROUNDDOWN(srcva);
// user的va翻译成了物理地址pa
pa0 = walkaddr(pagetable, va0);
// 这里可以成功运行 也不过是因为kernel_pagetable 在这个部分对 dram是恒等映射
// 因为cpu还是会将pa当作kernel pagetable的va来进行翻译。翻译成pa。
// 将user pgtbl维护的映射到pa0的内容 拷贝到kernel pgtbl维护的dst指向的地址的物理内存
memmove(dst, pa0 , n);
// continue
}
}
int copyinstr(pagetable_t user_pagetable, char *kernel_dst, uint64 user_srcva, uint64 max)
- 将user pagetable维护的srcva的地址的内容,拷贝kernel pagetable维护的dst。直到遇到’\0’
完成part3之后
- int copyin(pagetable_t user_pagetable, char *kernel_dst, uint64 user_srcva, uint64 len)
- 从proc user pagetable维护的srcva 的内容拷贝 len bytes 到 proc kernel pagetable维护的dst
- 此时proc的kpgtbl 也维护了srcva的虚拟地址,故不必去walkaddr,而是直接使用srcva
- success : return 0
- fail : return -1 .
1
2
3
4
5
6
7
8
9
10
11
12// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
int
copyin_new(pagetable_t user_pagetable, char *kernel_dst, uint64 user_srcva, uint64 len)
{
struct proc *p = myproc();
// 直接使用user的srcva 而不必先去walkaddr得到pa!
memmove((void *) kernel_dst, (void *)user_srcva, len);
stats.ncopyin++; // XXX lock
return 0;
}
(part 3)proc的kernel pagetable
part 3 : proc的kernel pagetable
- pagetable_t kvminitproc()
- 建立proc的kpgtable。仿照kvminit。不同之处在于没有映射CLINT。防止合并user页表时发生重合。
- void kvmmapproc(pagetable_t proc_kernel_pagetable, uint64 va, uint64 pa, uint64 sz, int perm)
- 在proc_kernel_pagetable上,建立从va到pa映射,大小为sz。仅仅建立映射,而不负责kalloc映射到的physical page。失败则panic
- void kvminithartproc(pagetable_t kpgtbl)
- 设置当前cpu使用页表为proc的kpgtbl
- int u2kvmcopymappingonly(pagetable_t kpgtbl,pagetable_t pgtbl,uint64 start,uint64 end)
- 将user pgtbl 的pte拷贝给user kernel pagetable [start,end)范围最大为[0,PLIC)。仅仅拷贝映射关系而已。而不拷贝映射的物理内存。
- 当user的pgtbl 有任何改动(增添或删除)的时候 将改动的pte拷贝给kernel pgtbl
- 将user pgtbl 的pte拷贝给user kernel pagetable [start,end)范围最大为[0,PLIC)。仅仅拷贝映射关系而已。而不拷贝映射的物理内存。
- uint64 kvmdeallocpgtblonly(pagetable_t kpgtbl, uint64 oldsz, uint64 newsz)
- 解除proc 的 kernel pgtbl 的va从 [newsz,oldsz) 到pa的映射(即将相应pte清0),但不释放physical memory
- [newsz , oldsz) 应当包含于 [0,PLIC)
- 解除proc 的 kernel pgtbl 的va从 [newsz,oldsz) 到pa的映射(即将相应pte清0),但不释放physical memory
关于proc的user pagetable
关于proc user pagetable
pagetable_t uvmcreate()
- 创建一个PGSIZE大小的empty的user的pagetable(通过kalloc)
- success :return pagetable
- fail :return 0
void uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
- 解除va到pa的映射(pa由pagetable查找)(即使得va对应的pte清0)
- 并释放pa对应的物理页(if dofree = 1)。
- 总共解除对npages个物理页的映射
- fail : panic。查询pte失败 | te指向的物理页无效 | 查询到的pte不是个叶子 ?
void uvminit(pagetable_t pagetable, uchar *src, uint sz)
- 在(user的)pagetable上,从虚拟地址的0开始,建立从 virtual [0,PGSIZE-1) 到 physical [mem,mem+PGSIZE-1) 的映射
- 只是为了第一个进程,第一个进程需要运行initcode的text。src这段内存中装的是initcode的代码
uint64 uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
- 为user pagetable 建立从virtual addr oldsz到virtual addr newsz的虚拟地址空间。为其申请物理内存并建立映射。
- 传入的oldsz 和 newsz 都是pgtbl的虚拟地址
- success : return newsz
- 返回pagetable维护的最大的虚拟地址
- fail : return 0; 当
- kalloc申请物理内存失败 / 建立mappages映射失败
uint64 uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
- pagetable维护的虚拟地址空间,从oldsz减到newsz。解除va到pa的映射 并释放physical page
- 传入的oldsz和newsz都是pagetable上的虚拟地址
- return pgtbl当前维护的最大vaddr
- pagetable维护的虚拟地址空间,从oldsz减到newsz。解除va到pa的映射 并释放physical page
void uvmfree(pagetable_t pagetable, uint64 sz)
- 释放user page table 所建立的 虚拟地址 到 物理地址的映射,并释放其所映射的物理内存
- uvmunmap
- 释放user page table 自身
- freewalk(pagetable);
- 释放user page table 所建立的 虚拟地址 到 物理地址的映射,并释放其所映射的物理内存
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
- 所谓uvmcopy 就是将old pgtbl所建立的映射关系以及物理内存 拷贝给 new pgtbl
- 本函数令 new pgtbl 也像old pgtbl 一样,建立从[0,sz-1]到physical memory的映射.
- 传入的old pgtbl 所维护的映射是从[0,sz-1]到physical memory的映射
- 将old(parent) page table 所维护的va到pa的映射中physical memory的内容拷贝给new pagetable 所建立的va所对应的physical memory.
- success : return 0
- fail : return -1
- 调用场合:Given a parent process’s page table, copy its memory into a child’s page table.
- 所谓uvmcopy 就是将old pgtbl所建立的映射关系以及物理内存 拷贝给 new pgtbl
void uvmclear(pagetable_t pagetable, uint64 va)
- 将va在user pagetable对应的PTE标记为user无权限
琐碎问题
- 刚切换回scheduler的时候就需要换回全局 kernel pgtbl吗?. 是的
- user pagetable 一定都在0xC00000之下吗? 怎么确定的 ? 我们实现时人为控制的.
- scheduler:怎么switch之后 直接就运行了另一个进程呢?:通过swtch.S . 见后面的thread实验
- uvmcopy 是不是只拷贝了text到heap的这段连续的。trapframe和trampoline不管。:对的
- 胡咧咧几句
- 可以看到,相较于Linux,即便我们完成了本实验,xv6实现的虚拟内存还是较为简易的。
- Linux里面process的virtual address不见得都是连续的. 一段段连续的va的起始地址记录于task_struct中的vm_area_struct中.
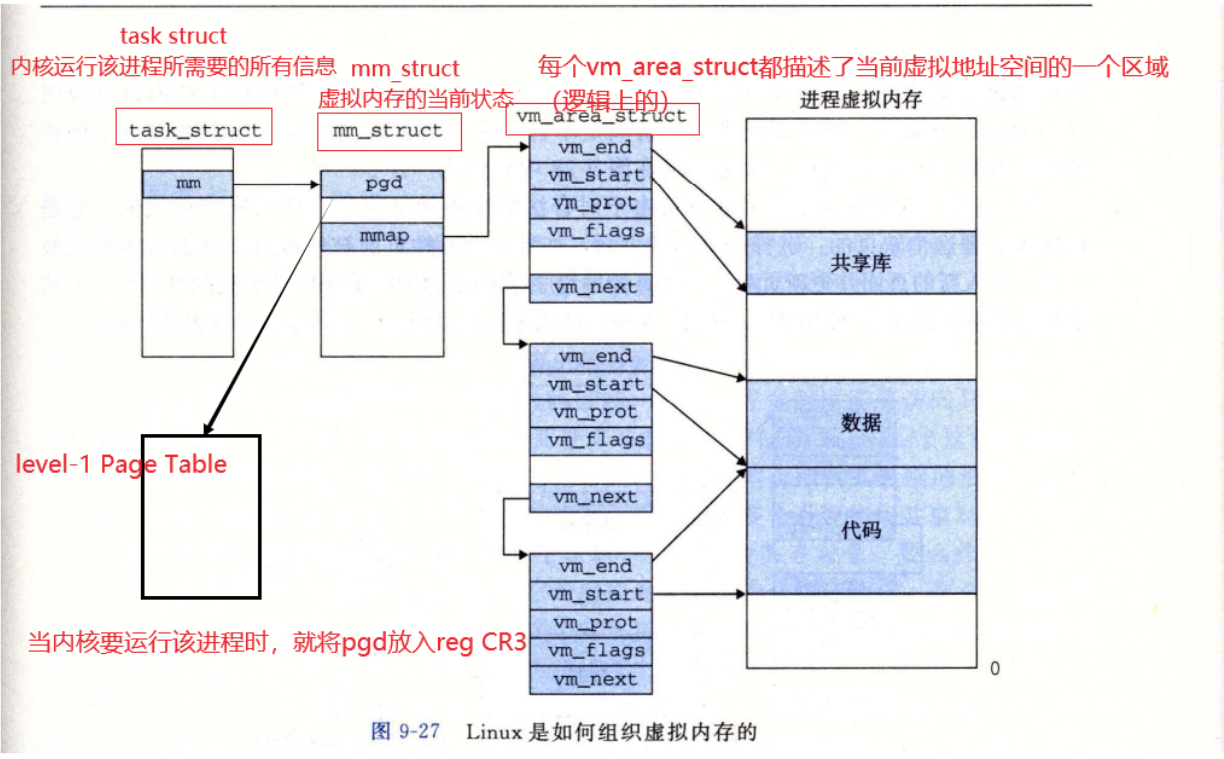
- 但是在xv6中,user process的virtual address是连续的. 除了顶部的trampoline和trapframe,就是下部的heap stack等. 换句话说,va只分成了两段(见下面的exec.c可以证明)
- 顶部的 trampoline , trapframe
- 下部的 heap , stack , guard page , data , text
- 当然heap段一开始是空的,并没有va对应的pte记录在pgtable中. 需要uvmalloc
- stack , guard page , data , text 一开始就有pte在pgtable中. 见exec()
- 那么,对于user传入kernel的va
- linux 显然会先从vm_area_struct中,寻找,看该va是否属于某一区域. 不属于,则是非法va. 若属于,再看该va对应的pte的权限是否合法.
- xv6 则简化很多,由于va连续,则kernel只需要检查va是否 < sz && > 0即可. 不属于,则非法va. 属于,则再看该va对应的pte的权限是否合法.
- 见copy on write实验
- Linux里面process的virtual address不见得都是连续的. 一段段连续的va的起始地址记录于task_struct中的vm_area_struct中.
- 可以看到,相较于Linux,即便我们完成了本实验,xv6实现的虚拟内存还是较为简易的。
- 由exec.c可以看出 xv6的user processtext datat stack heap 的 va是连续的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49int
exec(char *path, char **argv)
{
struct proc *p = myproc();
// create a user pagetable
// 0. 创建 pagetable
// 1. 建立 trampoline 和 trapframe 的映射
pagetable = proc_pagetable(p);
// 2. Load program into memory.
// 建立了 data 段 和 text 段 的 va到pa(申请了phymem)
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz);
loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz);
}
// Allocate two pages at the next page boundary.
// Use the second as the user stack.
// 3. 建立了 stack 段 和 guard page段 的 va到pa的映射 (申请了phymem)
sz = uvmalloc(pagetable, sz, sz + 2*PGSIZE);
uvmclear(pagetable, sz-2*PGSIZE);
sp = sz;
stackbase = sp - PGSIZE;
// int main(int argc,char *argv[])
// 将 argv压入 stack
// Push argument strings, prepare rest of stack in ustack.
for(argc) {
sp -= strlen(argv[argc]) + 1;
sp -= sp % 16; // riscv sp must be 16-byte aligned
}
// 记住main一开始的栈指针
p->trapframe->a1 = sp;
// 4. 解除kpgtbl的user部分的旧映射
kvmdeallocpgtblonly(p->kpagetable,p->sz,0);
// 5. 将新的user pgtbl 同步到 kernel pgtbl上
if(u2kvmcopymappingonly(p->kpagetable,pagetable,0,sz)<0)
goto bad;
// Commit to the user image.
p->pagetable = pagetable;
p->sz = sz;
p->trapframe->sp = sp; // initial stack pointer
// 6. 释放旧的user pgtbl
proc_freepagetable(oldpagetable, oldsz);
return argc; // this ends up in a0, the first argument to main(argc, argv)
}