线程调度流程 : user thread A -> kernel thread A -> scheduler thread -> kernel thread B -> user thread B
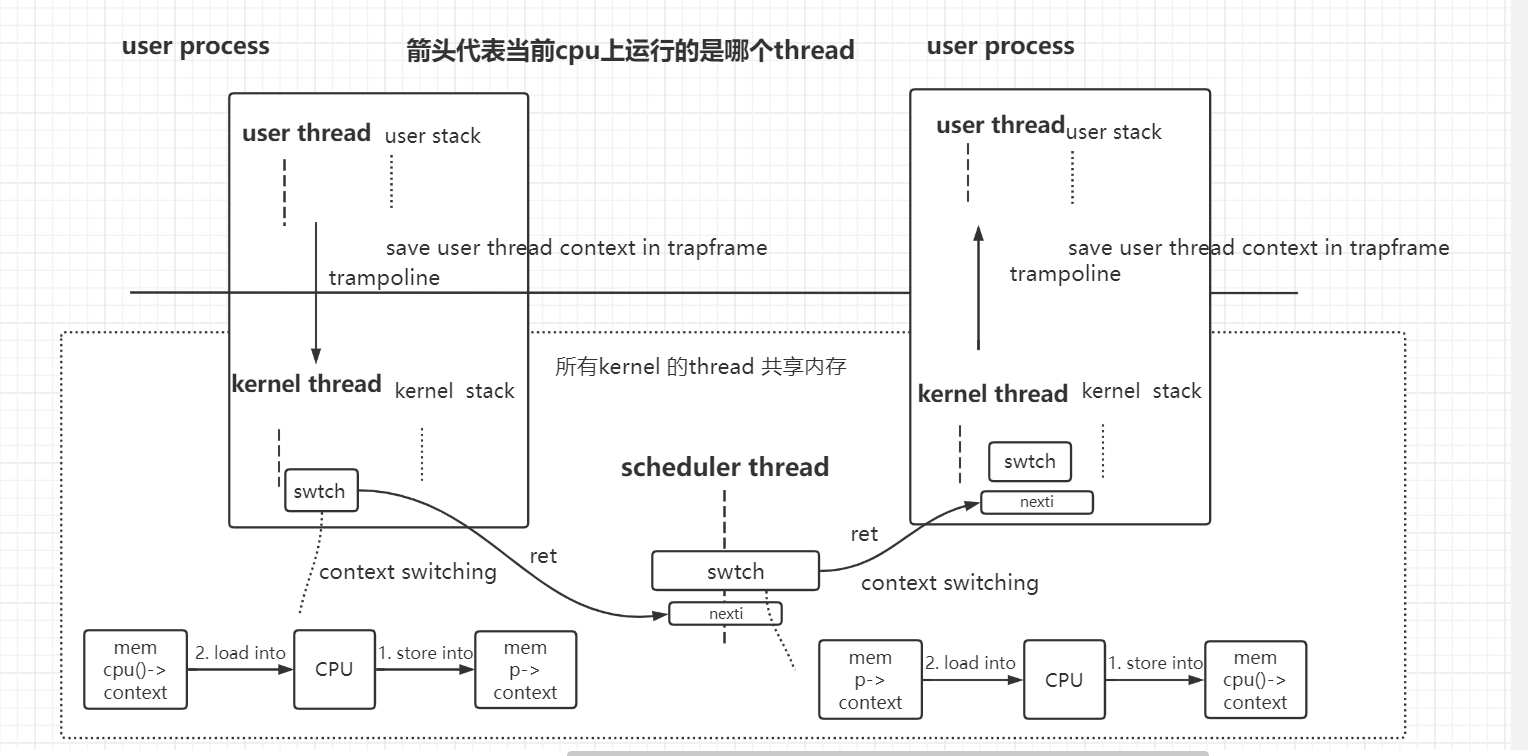
xv6和OS的线程调度策略 : pre-emptive scheduling(定时器中断) + voluntary scheduling(kernel thread主动swtch)
xv6的3个thread
- user process的user thread (上下文在trapframe)
- user process的kernel thread (上下文在trapframe和context)
- 每个cpu核 的 scheduler thread (上下文在cpu.context)
thread切换核心 : swtch
- 用于实现 kernel thread 和 scheduler thread的切换
- 切换return addr , kernel stack pointer , callee saved regs
thread
待完成问题
线程是什么?
- 从几个角度来说吧应该。
- 先列下来。
- 从构成的角度来说
- 。。。与progress对比一下。
- thread是process中的一条指令流,使用process的地址空间及其他context。每个thread都应当有自己的stack。thread之间应当是共享process的地址空间的。
- os应当支持一个用户进程的一个用户线程对应一个内核线程。xv6中内核线程和用户线程不是共享地址空间的。一个是user pagetable,一个是kernel pagetable。正常linux来说,也即在我们做完实验3page table之后的页表机制,user thread和kernel thread用的都是同一个pagetable。
- 感觉说的有待完善。。。。
- 从编程的角度来说
- 是os提供的一种执行多任务的抽象机制。
- 类似于event-driven progarmming中的reactor模型等。都是执行多个任务的逻辑流。
- 在所有的支持多任务的方法中,线程技术并不是非常有效的方法,但是线程通常是最方便,对程序员最友好的,并且可以用来支持大量不同任务的方法。
- 感觉可以再多说一点reactor模型相关的。。太累了。。改天复习reactor模型。
switch的ret什么时候执行?当再次切换回来的时候执行?
- 不对,是顺序执行的。只不过由于$ra被改变,ret的时候会ret到另一处对swtch的调用处
switch ret之前cpu使用的就变成了另一个线程的栈?可是pc也没有改变呀?如何做到的?
- pc不含有效信息,指示栈的就是$sp
xv6进程和线程的关系?
- process由2个thread组成
- user thread
- kernel thread
- 且存在限制,一个进程要么是其user thread 在运行,要么是在kernel thread运行(系统调用/响应中断),要么不运行。永远不会2个thread同时运行。
- process由2个thread组成
所以说kernel的那个proc结构体 实际上是kenrel thread的结构体是吗?
- 不只是。proc是整个process的结构体。
- 其中记录了
- process本身的状态信息,如pid , state , parent process , name等
- 和process中的user thread的所用的user pagetable , user的heap大小 , user的trapframe等
- 以及process中的kernel thread 的context等。(用于kernel thread 在swtch保存前一刻kernel thread的状态)
- 所以,通过mycpu(),我们可以获得当前正在运行的线程所属的process。不过从逻辑上来讲,我们也就不应当在scheduler thread中调用mycpu()。因为scheduler不属于任何process。是单独的一个线程。
说说kernel thread到底是个啥
- 感觉就是进入kernel的C code之后,调用kernel的C code,所形成的函数栈帧。
intena记录在acquire之前的中断状态
一个进程让出之后,会不会又运行这个进程?
struct proc proc[NPROC = 64];
- 至多有64个process,故至多有64个user thread 和64个kernel thread(64个kstack) + 每个cpu核上一个scheduler thread+带的kstack。
xv6里一个进程的用户线程和内核线程也不是共享地址空间的啊。页表都不一样。为啥教授还说是一个进程里的用户线程和内核线程?
- 在xv6中,这两个线程比较特殊,确实不是共享地址空间。
- 但是对于主流的linux系统,其pagetable的机制就和我们在page table实验所完成的一样。user thread 和 kernel thread使用的是同一个page table。
切换地址空间了是不是就是代表一定切换进程了?那么从user到kernel是否应当叫做切换了进程?用户进程切换到内核进程。
- 不应当。都是一个进程里的。原因见上。
linux进程的线程的pagetable是不是分开的?是么?不是吧?
- 我觉得一个进程的多个线程共用同一个的pagetable。没验证。。。改天验证。。。太累了。。。仅仅是觉得。。。。
thread 概述
线程的作用 / 为什么计算机需要多线程?
- 首先,我们可能会要求计算机分时复用的执行任务,而不是在一段时间里只执行一个任务
- 其次,多线程可以让程序的结构变得简单。
- 最后,使用多线程可以利用多核cpu以获得更快的速度。
- 常见的做法是将程序进程拆分,分给多个线程运行,运行在不同的cpu核上。
- 线程可以认为是一种在有多个任务时,用于简化编程的一种抽象机制。
- 感觉也是一种event-driven programming 编程模型。
- event-driven programming或者state machine,这些是在一台计算机上不使用线程但又能运行多个任务的技术。
- 在所有的支持多任务的方法中,线程技术并不是非常有效的方法,但是线程通常是最方便,对程序员最友好的,并且可以用来支持大量不同任务的方法。
- 所以那些事务驱动模型,如单线程的reactor 实际上不也是个并发的程序?也是个执行多任务的编程方法。只不过不是os自己提供的抽象出来的线程,而是用户自己通过代码实现的。
线程的状态
- 程序计数器PC: 当前线程执行的指令位置
- 保存变量的寄存器reg。
- 程序栈stack: 每个线程都有自己的stack,stack记录了函数调用过程,并反应了当前线程的执行点。
- 变量
- 堆
- ….
如何管理多个线程运行?两种策略结合
- 利用多核cpu,每个cpu上运行一个thread
- 一个cpu在多个thread之间来回切换。
xv6的thread是否共享内存
- 内核线程 kernel thread
- 所有kernel thread共享内核内存。
- 每一个用户进程都有个kernel thread执行来自用户线程的syscall
- 用户线程 user thread
- 用户线程之间没有共享内存。
- 每个用户进程都有独立的地址空间,并且包含了一个user thread,user thread控制了user process code的执行。
- 内核线程 kernel thread
Linux中
- 实现了一个用户进程中包含多个线程(xv6没有实现,xv6中一个进程只有一个用户线程)
- 一个进程的多个线程共享地址空间。
thread切换流程
- 流程图镇楼
- 当进入kernel的C code之后,运行的就是process 的 kernel thread了。
如何实现thread切换?:scheduler调度器
如何保存线程状态并恢复?:那些是需要保存的、保存在哪里
如何处理计算密集型线程?:对于长时间的计算任务,线程不会自愿的让出cpu给其他线程运行,所以需要一种机制,能夺走计算密集型线程对cpu的控制,之后再运行。
下面是如何处理计算密集型任务。
定时器机制
机制:利用定时器中断
- 内核利用定时器中断将对cpu的控制从计算密集型线程的手中夺走
- 每个cpu核上,都存在一个硬件设备,会定时产生中断。xv6与其他os一样,将这个中断传输到了kernel中。中断打断并处理如下
流程概述 pre-emptive / voluntary scheduling
pre-emptive scheduling 抢占式调度:
- 用户代码本身不想让出cpu,但是timer interrupt会导致cpu的控制权被拿走,yield给scheduler thread,
- 例如中断处理的流程。
- 相反的是voluntary scheduling 非抢占式调度
- 用户代码本身不想让出cpu,但是timer interrupt会导致cpu的控制权被拿走,yield给scheduler thread,
在xv6和其他os中,线程调度这样实现
- pre-emptive 和 voluntary的结合
- 定时器中断 会强制的将cpu控制权从user process(的user thread)传递到kernel (user process的kernel thread),之后kernel会代表user process 进行 voluntary scheduling。
- pre-emptive:中断的强制,哪怕这些用户进程一直占用cpu不愿让开,通过中断,kernel也可以从user process夺得cpu控制权。
- voluntary:kernel如何代表user process使用voluntary scheduling ?
- kernel thread内核线程 的 timer interrupt handler 会将 cpu 让s(yield)给 scheduler thread调度器线程。通过swtch
- 这就是kernel 代表 user process 进行 voluntary的让出了cpu
- 如何yield:保存当前cpu上正在运行的内核线程。,将scheduler thread的上下文替换到当前cpu上.
- 然后scheduler thread 会选择一个runnable的kernel thread 并swtch到cpu上。
- 这也就是 kernel 代表 user process 进行 voluntary的 将 控制 传递给了 另一个 user process
- kernel thread内核线程 的 timer interrupt handler 会将 cpu 让s(yield)给 scheduler thread调度器线程。通过swtch
尽管我们这节课主要是基于定时器中断来讨论,但是实际上XV6切换线程的绝大部分场景都不是因为定时器中断,比如说一些系统调用在等待一些事件并决定让出CPU。exit系统调用会做各种操作然后调用yield函数来出让CPU,这里的出让并不依赖定时器中断
相关的进程状态
- RUNNING:线程正在当前cpu上运行
- PC和reg在cpu中,正在被使用
- RUNNABLE:线程还没有在某个cpu上运行,一旦有空闲的cpu就可以运行
- PC和reg被保存在内存中某处。
- SLEEPING:线程在等待一些IO事件,只会在IO事件发生了以后运行。
- 线程调度就是将当前的running process 变成 runnable process
- RUNNING:线程正在当前cpu上运行
一些需要注意的东西
xv6中总共有3种thread
- user process的user thread
- 在不运行时,其线程状态会保存在trapframe中
- 有自己的用户栈
- user process的kernel thread
- 在不运行时,其线程状态会保存在proc.context中
- 有自己的内核栈
- 每个cpu核 的 scheduler thread
- 在不运行时,其线程状态会保存在cpu.context中
- 每个scheduler thread都有自己独立的栈。scheduler thread的所有内容,都和user thread不一样。是在系统启动时设计好的。
- user process的user thread
进程 process
- process由2个thread组成
- user thread
- kernel thread
- 且存在限制,一个进程要么是其user thread 在运行,要么是在kernel thread运行(系统调用/响应中断),要么不运行。永远不会2个thread同时运行。
- process由2个thread组成
xv6并没有实现用户线程直接让出cpu,内核会在如下场景下让出cpu
- 定时器触发
- 内核总是会让当前进程yield出cpu,因为我们需要交织执行所有可执行的线程。
- 调用系统调用并等待I/O
- 如进程调用syscall read进入kernel,read会等待磁盘IO,此时read syscall code->sleep()->sched()->swtch()
- 定时器触发
所谓的context switching
- 一个 thread 切换到 另一个 thread
- 一个 user process 切换到 另一个 user process的完整过程。
- 用户空间和内核空间的切换
- 内核线程kernel thread和调度器线程scheduler thread的切换
小结
- 一个cpu核在同一时间只会做一件事情,也即只会运行一个线程,线程切换造成了多个线程同时运行在一个cpu核上的假象。
- user process的user thread
- user process的kernel thread
- cpu核 的 scheduler thread
- 一个thread不会同时运行在多个cpu核上
- 要么运行在一个cpu核上
- 要么状态被保存在context(kernel thread)/ trapframe(user thread)中,没有被运行
- 一个cpu核在同一时间只会做一件事情,也即只会运行一个线程,线程切换造成了多个线程同时运行在一个cpu核上的假象。
thread切换核心 : swtch
thread切换的核心
swtch
- void swtch(struct context *old, struct context *new);
- Save current registers in old. Load from new.
- 将当前cpu上的reg保存在old中,并将new加载到cpu的reg上
- 这也就是 实现了 所谓的 context switching的函数,用于在kernel thread 和 scheduler thread之间进行上下文切换。
- 调用情况如下:
- p->context 是 kernel thread的上下文。mycpu()->context 是该cpu核的scheduler thread 上下文。
- sched中:swtch(&p->context, &mycpu()->context);
cpu reg ----store into---> kernel thread.context (mem)scheduler context (mem) ----load into---> cpu reg
- scheduler:swtch(&c->context, &p->context);
cpu reg ----store into---> scheduler context (mem)kernel thread.context (mem) ----load into---> cpu reg
- 所谓的保存到mem和加载到reg的context是
- $ra : ret的返回地址
- $sp : thread对应的stack pointer
- s[1,11] : 被调用者保存的寄存器
- 并没有保存PC,因为PC并不是有效信息,随着code执行,PC会一直改变,没意义。我们关心的应当是swtch之后,thread应道跳到哪行code继续执行,以及其函数栈帧。那么,所要关注的寄存器就是ra和sp
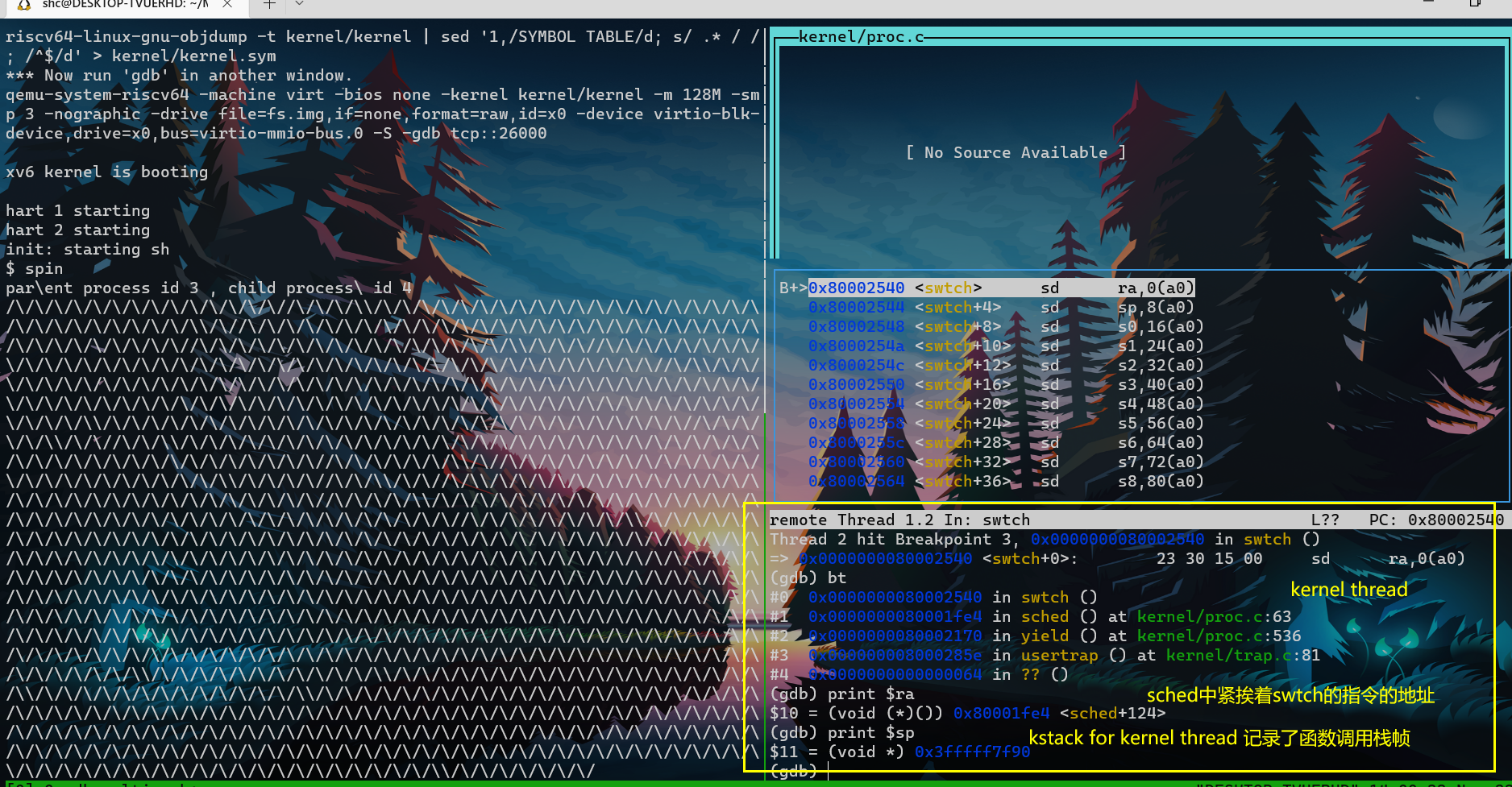
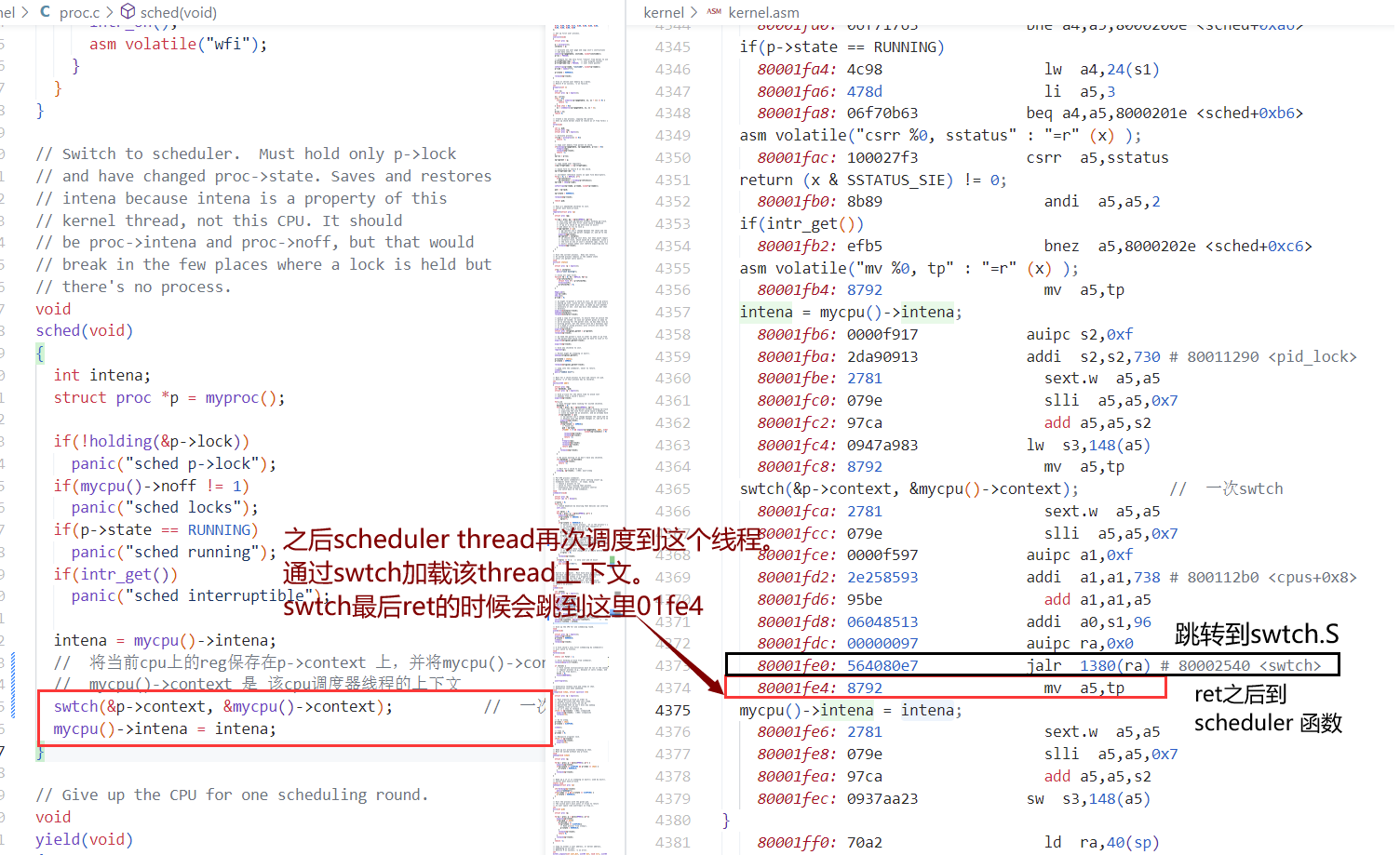
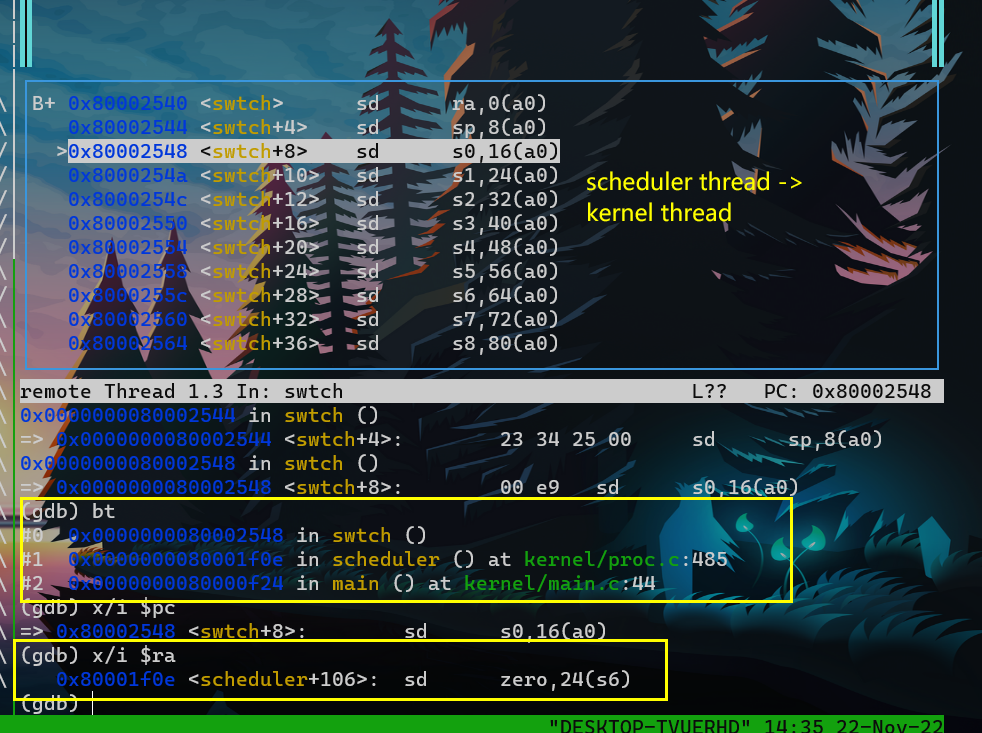
code如下:kernel thread -> scheduler thread
- kernel thread 由 usertrap -> yield -> sched -> swtch
- 在swtch中 保存kernel thread context 并加载 scheduler thread context
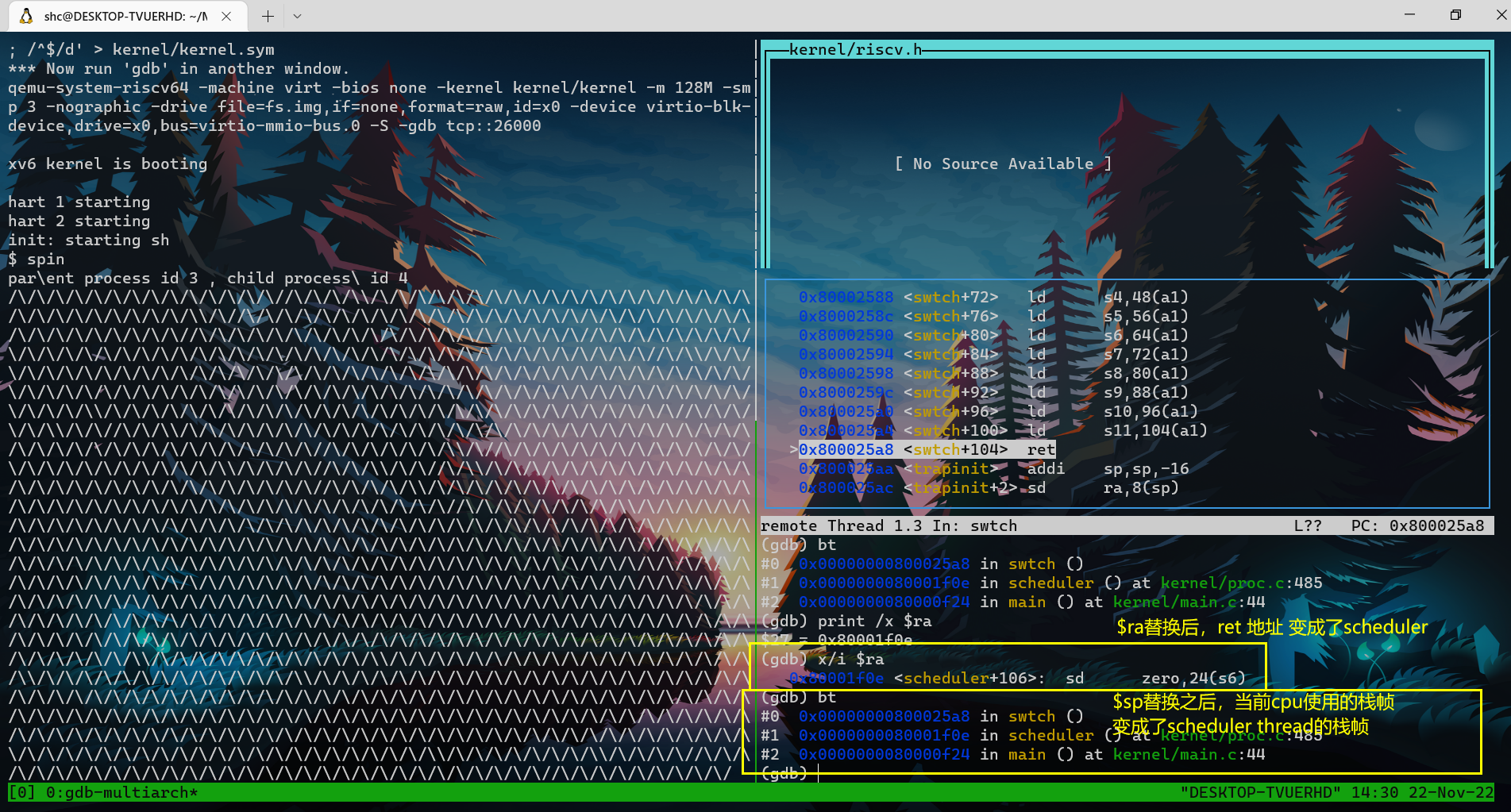
- 可以看到,在将scheduler的ra以及sp加载cpu reg之后,ret的返回地址以及函数调用栈帧bt都变成了scheduler thread的。
- swtch —ret–> scheduler thread
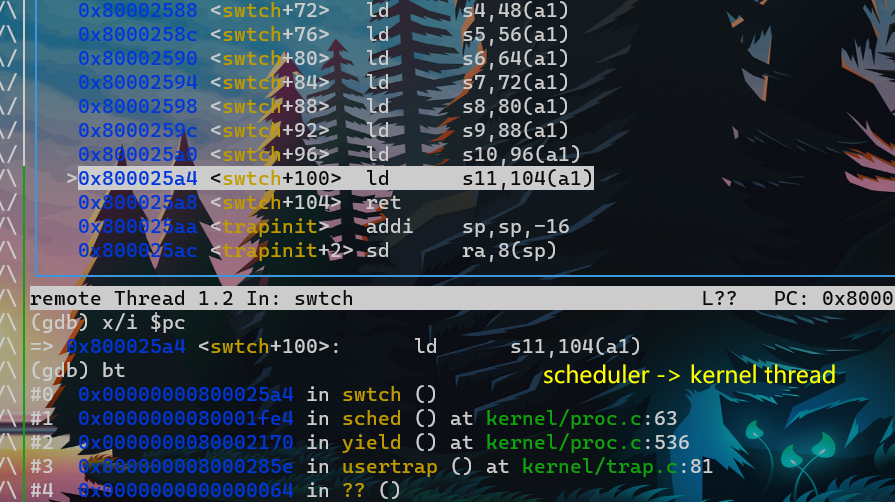
- 同理:scheduler thread -> kernel thread
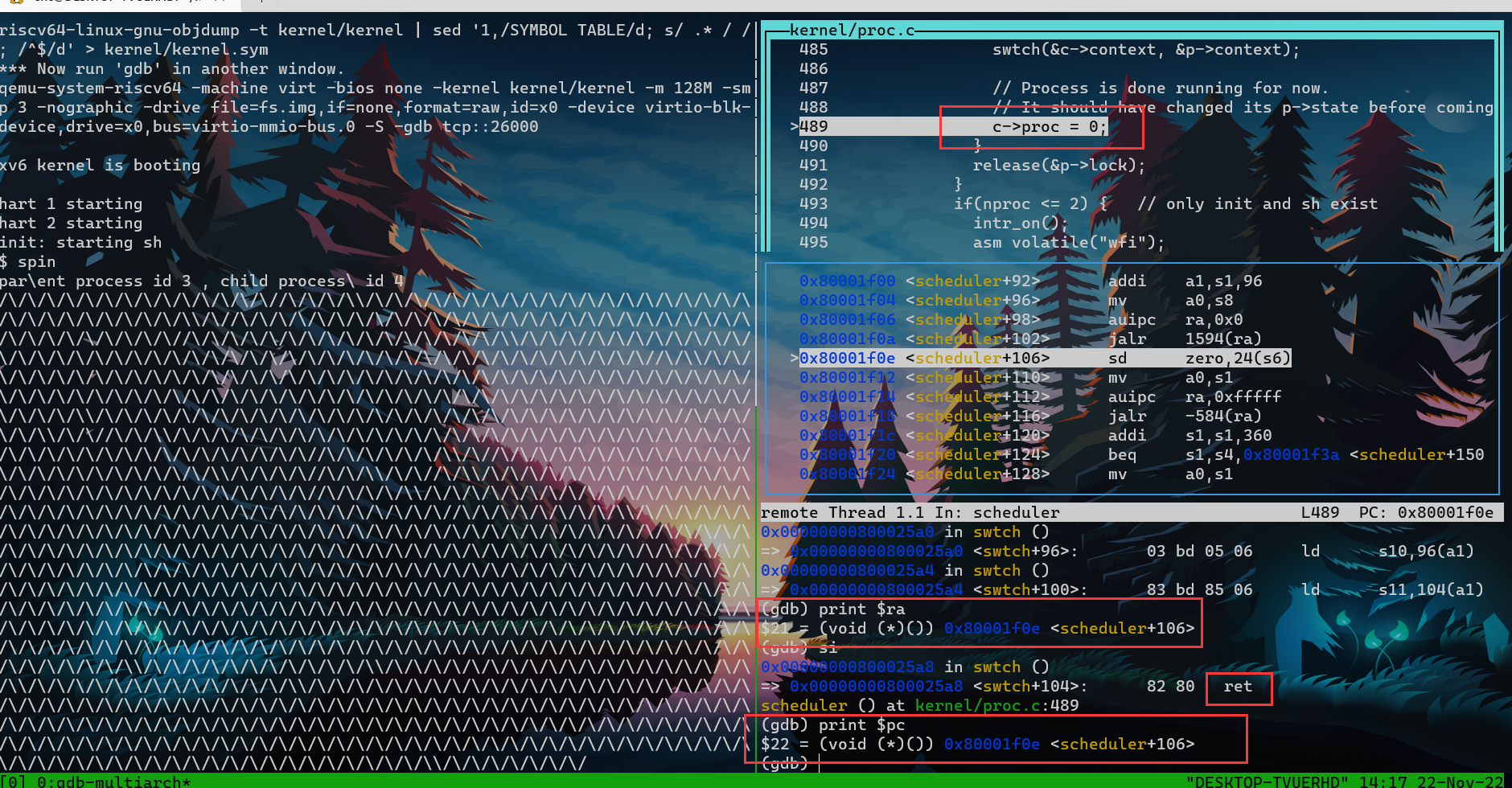
注意:scheduler thread 调用了swtch函数,但是我们从swtch函数返回时,实际上是返回到了对于switch的另一个调用处:kenrel thread 对swtch的调用处,而不是scheduler thread的调用。
- 通过改变ra来达成此种效果,也就达成了切换线程的效果。
- 也即,比如kernel thread a调用swtch,由于在swtch对ra以及其他context进行了替换,故这个swtch函数结束后,ret就跳转到了另一处代码。非本次swtch调用处,而是scheduler 对 swtch的调用处。
thread切换过程中,cpu上的reg是唯一不稳定的状态,需要保存并恢复,因为我们想在新的线程中也使用相同的一组寄存器;而所有其他在内存中的数据(如heap、stack)会保存在内存中不被改变,所以不用特意保存并恢复。
scheduler thread
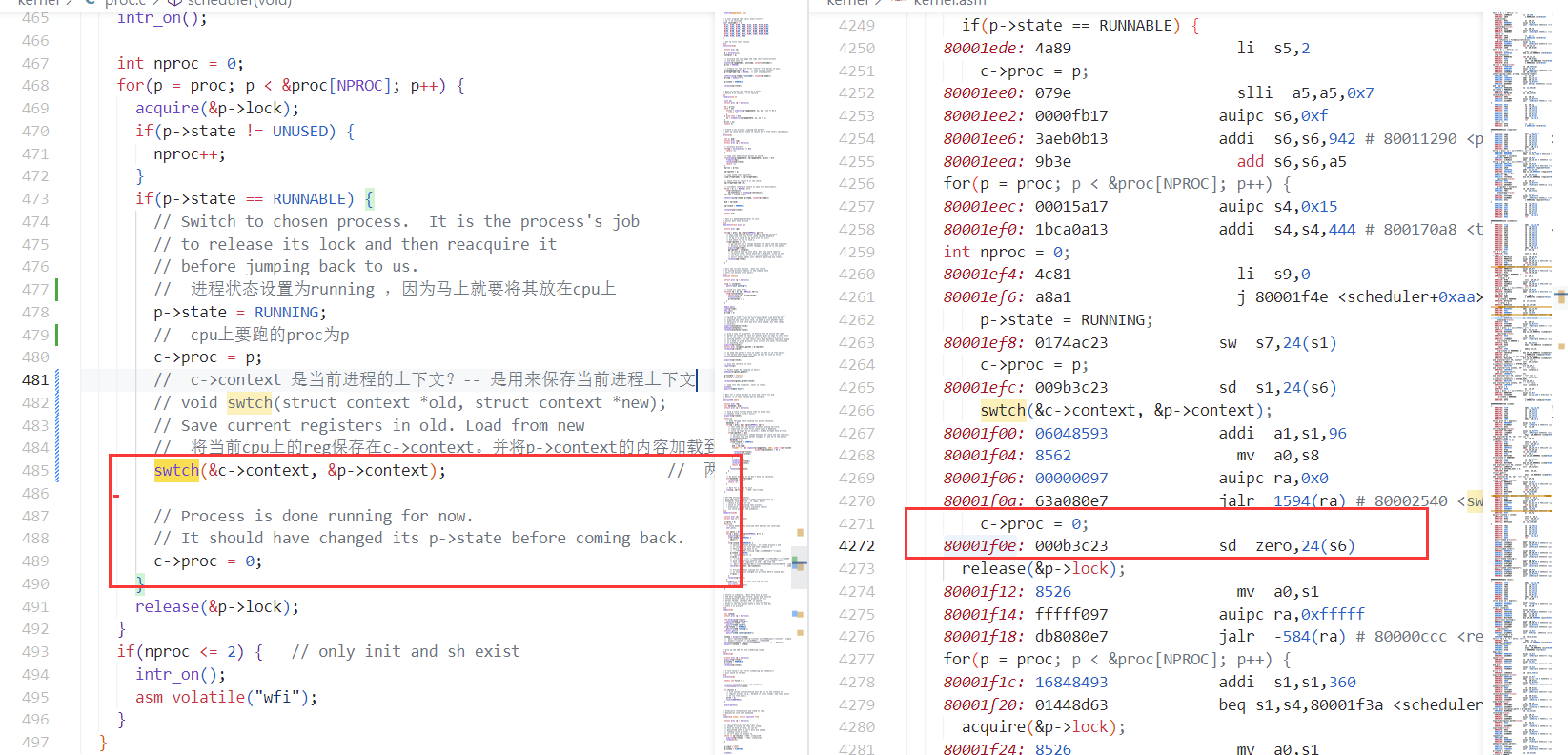
- 下面是scheduler函数
- 选择一个runnable的进程,将其context替换进cpu,然后运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;)
{
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
int nproc = 0;
for(p = proc; p < &proc[NPROC]; p++)
{
acquire(&p->lock);
if(p->state != UNUSED)
{
nproc++;
}
if(p->state == RUNNABLE)
{
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
// 令cpu运行kernel thread p
// 即将运行p,故先设置状态为RUNNING
p->state = RUNNING;
// 即将运行p,故先设置cpu上正在运行的proc为p
c->proc = p;
// context switching , 切换到kernel thread p。之后cpu run kernel thread
swtch(&c->context, &p->context);
// after a while
// 从swtch返回。
// kernel thread p 切换回 scheduler thread
// 此时cpu上没有任何正在运行的kernel thread 和 user thread。只有scheduler thread
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
if(nproc <= 2)
{ // only init and sh exist
intr_on();
asm volatile("wfi");
}
}
}
- 选择一个runnable的进程,将其context替换进cpu,然后运行。
关于lock
关于锁p->lock的使用
acquire(p->lock) release(p->lock)流程如下
- 从kernel thread -> scheduler
- kernel thread yield 上的锁 由 切换到 scheduler的swtch之后 释放
- 从scheduler -> kernel thread
- scheduler 上的锁 由 切换到 kernel thread的swtch之后 释放。
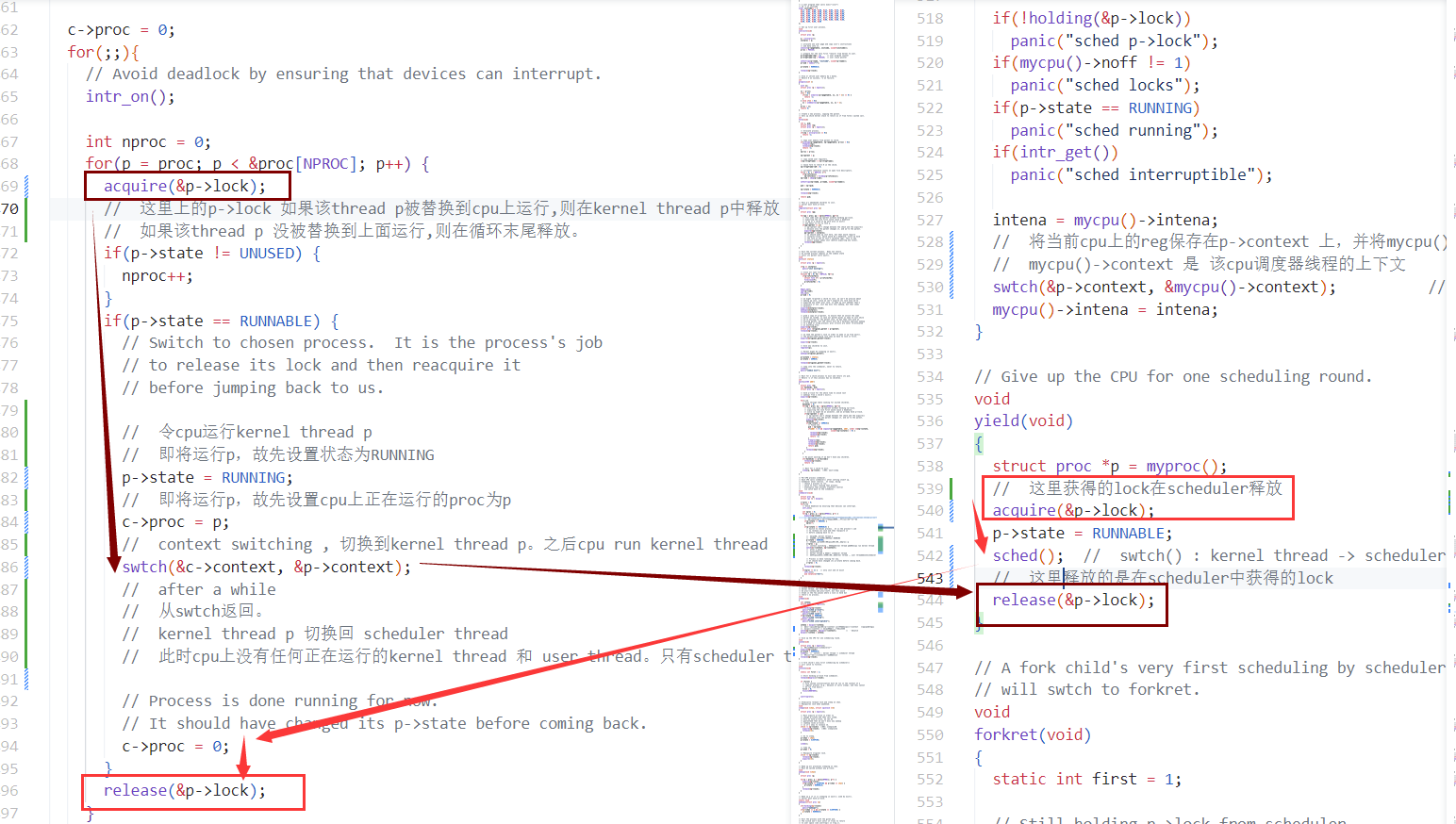
- 从kernel thread -> scheduler
p->lock作用
- 在以下两个场景中,都是为了线程切换的原子性。
- 防止在我们这个线程切换还没完成的时候,另一个cpu核上的scheduler thread看到并使用该线程。
- 线程切换步骤概述:设置p->state,保存当前thread context,替换成要切换的thread的context
- 1. kernel thread -> schedulers
- p->state = RUNNABLE;
- swtch(&p->context, &mycpu()->context);
- 2.1 将当前kernel thread的context保存($ra,$sp,regs)
- 2.2 cpu上的reg替换成scheduler thread的context。
- 2. scheduler -> kernel thread
- p->state = RUNNING
- swtch(&c->context, &p->context);
- 2.1 将当前scheduler thread的context保存($ra,$sp,regs)
- 2.2 cpu上的reg替换成kernel thread的context。
- 在以下两个场景中,都是为了线程切换的原子性。
对每个proc的第一次swtch
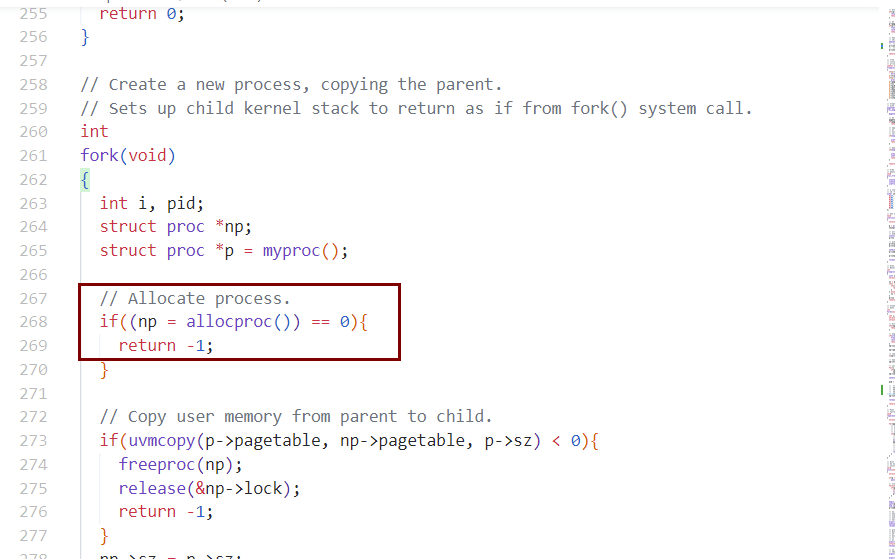
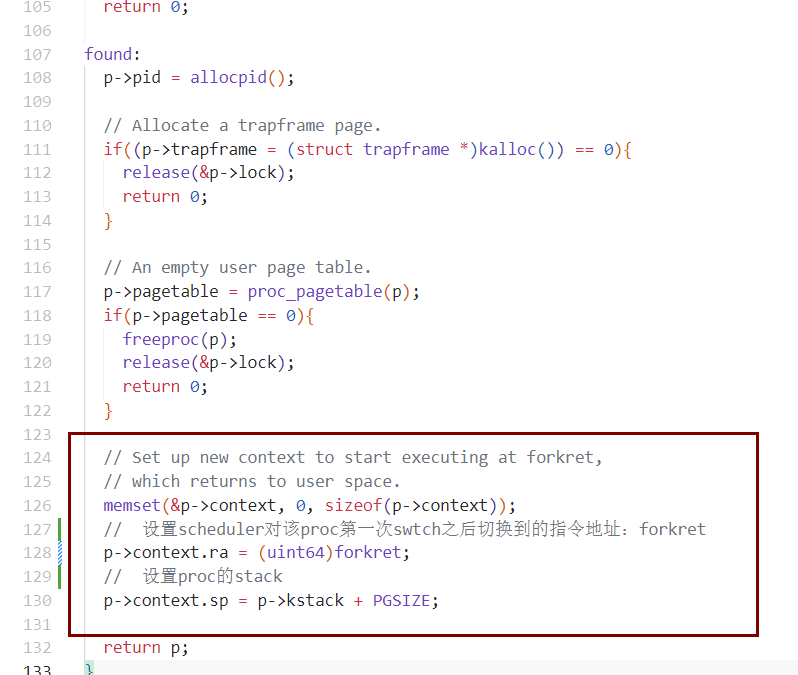
allocproc中为什么要设置context?为了scheduler对被分配的proc的第一次swtch。
- 刚变成runnable的proc还没有被放在cpu上运行。其变成running需要由scheduler thread调度。scheduler通过swtch将runnable thread.context替换到cpu上。
- 一般情况下,runnable thread.context 是该thread对应的proc的kernel thread在sched的时候,通过swtch将自身context保存起来,以待下次scheduler调度到该thread时替换进来。
- 可是,对于该proc第一次由runnable变成running,被scheduler调度,其context则不是由上次swtch保存好的,而是由allocproc中,对$ra和$sp进行的初始化。ra初始化成forkret->usertrapret。$sp自然就是本kernel thread的ktsack。
allocproc 会被 启动时的userinit和系统调用fork调用
fork调用allocproc
allocproc
一个process刚被fork出来的时候,一直处于内核态kernel thread ,且没有被运行。直到scheduler之后,才会swtch到该process。由于一开始刚fork出来时设置的ra为forkret,因此回swtch到process的forkret,然后usertrapret 经由trampoline到process的user thread,开始运行。
Linux 如何区分进程和线程
- process 和 thread在 linux kernel中都是通过task_struct表述,那么linux kernel如何区分一个task_struct 代表的是process还是thread ?
- 通过比较tgid和pid。相等,则为进程;不等,则为线程。

- tgid : thread group ID
- 任何一个process,如果只有一个main thread,那么,tgid = pid(即为process A.pid)。
- 但是,如果一个process A创建了其他线程a1。那么thread a1有自己的pid,而thread a1.tgid = main thread.pid(即为process A.pid)。
- 一个thread group中的所有thread使用和该thread group leader相同的PID,并被存放在tgid成员中。
- 只有leader的pid设置为=tgid。
- getpid()系统调用返回的是当前thread的tgid值而不是pid值。