- part1 : 协程
- thread_yield -> thread_schduler
- thread_yield -> thread_schduler
- cond_broadcast 唤醒后 没拿到lock的thread还需要再次被cond_broadcast吗 ?
- 不需要
- 因为cond将一系列等待该cond的thread(BCD thread)串在了一起,当Athread broadcast广播唤醒该cond时,这一系列thread(BCDthread)都不再受阻于该cond约束。
- 之后谁拿到锁谁往下走就行了,与cond无关
part1
- 这个part实现的就是所谓的协程
- 这里的uthread完全都是在用户态的。
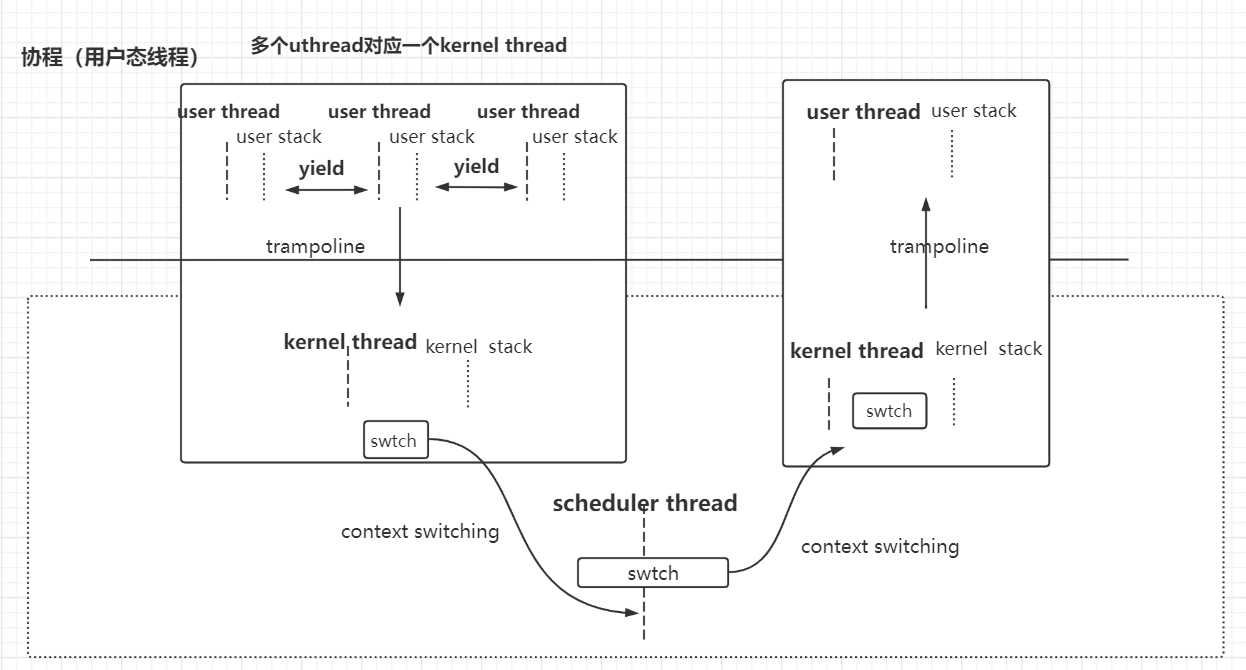
- 也即是一个进程中 多个user thread 对应 一个 kernel thread
- 正常的线程,如pthread,都是一个user thread对应一个kernel thread。kernel scheduler thread 可以对pthread之间执行切换,而无需user thread自己控制切换。
- 多个user thread 运行在 一个cpu core上
- 没有定时器中断来陷入kernel强制执行uthread之间的调度。
- 因为kernel scheduler thread 只能看见 kernel thread。只能对kernel thread进行调度。
- 而这里是一个process里面,多个user thread 对应 一个 kernel thread。因此无法对user thread 进行调度。
- 需要user thread本身在合适的时候yield让出cpu,并切换到其他user thread上。
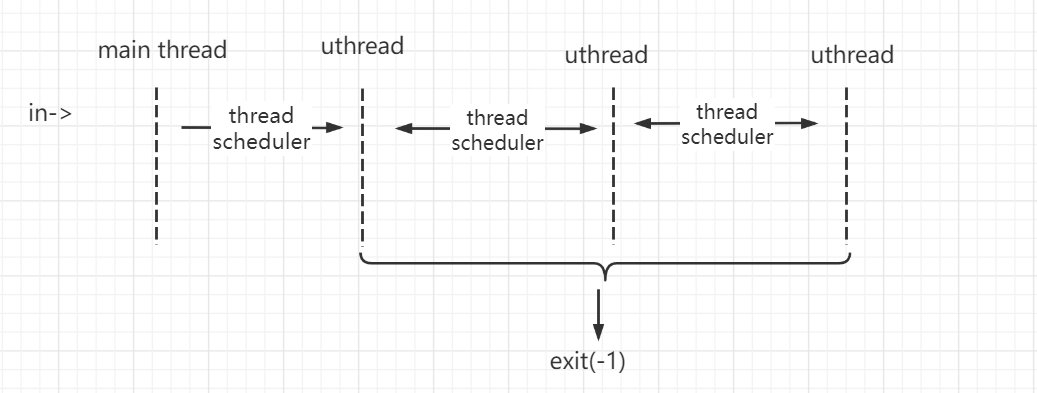
写在前面:咱一开始想的不对,一开始以为这里要实现的uthread的切换机制和每个cpu核上的kthread的切换机制差不多,也是有一个scheduler thread。以为这里的main thread 实际上就是 scheduler thread。scheduler一直运行在我们main thread的stack上。。uthread切换到shcheduler thread 再切换到另一个uthread。不过看着看着就发现不是。因为每个uthread都直接调用了thread_scheduler。并且这scheduler也不是个死循环啊。就是一个普通函数。找到runnale uthread就跳出,并swtch到那个uthread。
每个uthread都可以自己发出yield出cpu,切换到其他runnable uthread的动作。也即。每个uthread都可以调用thread_scheduler函数。
大致逻辑如图,可以看到并没有像kernel thread切换时需要有一个shceduler thread作为中转。而是一个uthread直接scheduler并swtch到别的uthread。
问题
- thread_switch needs to save/restore only the callee-save registers . Why?
- 因为我们是通过thread_swtich以函数调用的形式切换线程,抛去线程相关的寄存器ra、sp需要被保存,剩下的需要保存的,就是可能被 [被调用过程改变的寄存器],也即 被调用者保存的寄存器.
- 因为我们将线程切换包装成了函数调用的形式,正常C code中 A调用B(A函数B函数都是用C代码写的),那么编译器编译之后,会生成如下汇编代码:A调用B之前会自动的保存调用者保存的寄存器,进入B之后,B会自动的保存被调用者保存的寄存器。那么在本节中,B就是swtch函数,可是由于该函数是汇编编写,无需如Ccode一样编译成汇编,也就不会生成:进入B之后,自动的保存被调用者保存的寄存器 的 汇编代码。故这个swtch函数中,保存被调用者保存的寄存器的函数是由我们用汇编编写的。故swtch函数中需要保存 reg sa , sp 以及 被调用者保存寄存器
- 而相比之下 trampoline中 就不只是保存 被调用者保存的寄存器;因为user thread 切换成 kernel thread 并不是 C code中调用的函数调用,也即这个上下文切换并不是以函数调用的形式,程序在运行时可能随时会通过trampoline(如定时器中断)进入内核(如在正在执行密集计算指令的时候),并不是C代码通过函数调用进行的切换,属于是在某函数运行的中间突然触发切换,本身该函数的C代码编译后也并没有对这种情况进行处理,故我们在trampoline需要保存大量寄存器,既有caller 也有 callee(被调用者保存)。
引申:内核调度器无论是通过时钟中断进入(usertrap),还是线程自己主动放弃 CPU(sleep、exit),最终都会调用到 yield 进一步调用 swtch。 由于上下文切换永远都发生在函数调用的边界(swtch 调用的边界),恢复执行相当于是 swtch 的返回过程,会从堆栈中恢复 caller-saved 的寄存器, 所以用于保存上下文的 context 结构体只需保存 callee-saved 寄存器,以及 返回地址 ra、栈指针 sp 即可。恢复后执行到哪里是通过 ra 寄存器来决定的(swtch 末尾的 ret 转跳到 ra)
而 trapframe 则不同,一个中断可能在任何地方发生,不仅仅是函数调用边界,也有可能在函数执行中途,所以恢复的时候需要靠 pc 寄存器来定位。 并且由于切换位置不一定是函数调用边界,所以几乎所有的寄存器都要保存(无论 caller-saved 还是 callee-saved),才能保证正确的恢复执行。 这也是内核代码中 struct trapframe 中保存的寄存器比 struct context 多得多的原因。
另外一个,无论是程序主动 sleep,还是时钟中断,都是通过 trampoline 跳转到内核态 usertrap(保存 trapframe),然后再到达 swtch 保存上下文的。 恢复上下文都是恢复到 swtch 返回前(依然是内核态),然后返回跳转回 usertrap,再继续运行直到 usertrapret 跳转到 trampoline 读取 trapframe,并返回用户态。 也就是上下文恢复并不是直接恢复到用户态,而是恢复到内核态 swtch 刚执行完的状态。负责恢复用户态执行流的其实是 trampoline 以及 trapframe。
来自
uthread程序执行流程:
- main thread : thread_init -> thread_createabc -> thread_scheduler -> thread a/b/c
- thread a/b/c: running func -> yield -> running func
- end: scheduler -> no runnable process -> exit(-1)
This sets a breakpoint at line 60 of uthread.c. The breakpoint may (or may not) be triggered before you even run uthread. How could that happen?
因为gdb的实现依赖于监视pc寄存器,我们在b some_func的时候实际上是记录的某个地址。如果uthread内的指令地址与内核的指令地址有重复,那么当内核运行到这个地址的时候就会触发本应该在uthread内的断点。此外,很容易验证不同的用户态程序也会干扰。比如在uthread内部的0x3b之类的地址打下个断点,再运行ls或者其他用户态程序,如果在0x3b地址的指令是合法的,那么也会触发本应该在uthread程序内部的断点。
实现
我所做的工作:
thread_create:找到free的thread,为其分配task:func ,并初始化好线程任务地址(ra)以及ustack(sp),使其变成runnable。
- t->ucontext.ra = (uint64)func;:为了scheduler第一次调度到该uthread时知道跳转到哪里。— 跳转到thread 的 task func开始执行。
- 这里类似于allocproc。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
memset(&t->ucontext,0,sizeof(t->ucontext));
// 初始化scheduler func第一次调度到该uthread时的需要跳转到的地址
// 也即,记录了该uthread的任务函数的地址
t->ucontext.ra = (uint64)func;
// 设置ustack
t->ucontext.sp = (uint64) t->stack + STACK_SIZE;
}
thread_schedule:找到runnable的uthread,通过swtch进行uthread切换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35void
thread_schedule(void)
{
struct thread *t, *next_thread;
/* Find another runnable thread. */
next_thread = 0;
t = current_thread + 1;
for(int i = 0; i < MAX_THREAD; i++){
if(t >= all_thread + MAX_THREAD)
t = all_thread;
if(t->state == RUNNABLE) {
next_thread = t;
break;
}
t = t + 1;
}
// 整个process 最后会从这里退出
if (next_thread == 0) {
printf("thread_schedule: no runnable threads\n");
exit(-1);
}
if (current_thread != next_thread) { /* switch threads? */
next_thread->state = RUNNING;
t = current_thread;
// 要切换到的uthread
current_thread = next_thread;
/* YOUR CODE HERE
*/
thread_switch((uint64)&t->ucontext,(uint64)¤t_thread->ucontext);
// 之后从别的uthread切换回来时,回回到本uthread的这里,继续向下执行,离开shceduled函数
} else
next_thread = 0;
}thread_switch : 和kernel的swtch一样。
- 记录当前执行到的指令地址,也即本uthread的thread_swtch的下一条,以及本uthread的stack,以及callee save regs,以便之后切换回本uthread;
- 将runnable process的context替换进cpu.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42.text
# 将当前cpu上的reg保存在old 上,并将new 加载到cpu的reg上
/*
* save the old thread's registers,
* restore the new thread's registers.
*/
.globl thread_switch
thread_switch:
/* YOUR CODE HERE */
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0) # 被调用者保存的寄存器
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1) # 被调用者保存的寄存器
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */
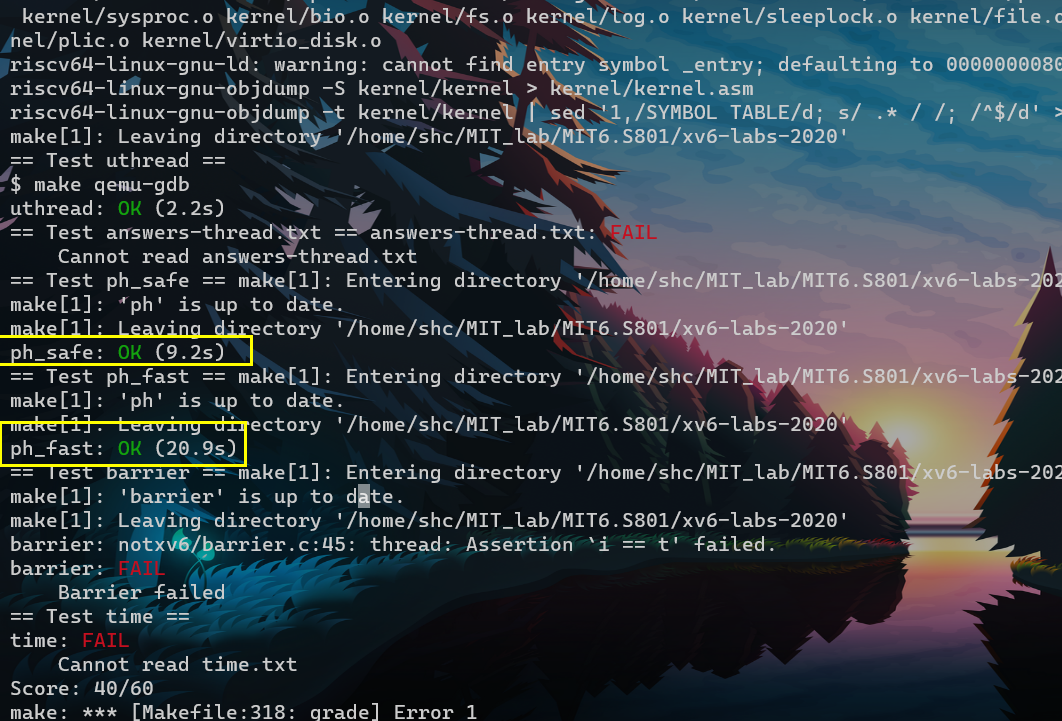
一遍过,一点儿bug没有。
part2
这难度应该标成easy
把ph.c读一边就好了。
This assignment uses the UNIX pthread threading library. You can find information about it from the manual page, with man pthreads
lock API
1
2
3
4pthread_mutex_t lock; // declare a lock
pthread_mutex_init(&lock, NULL); // initialize the lock
pthread_mutex_lock(&lock); // acquire lock
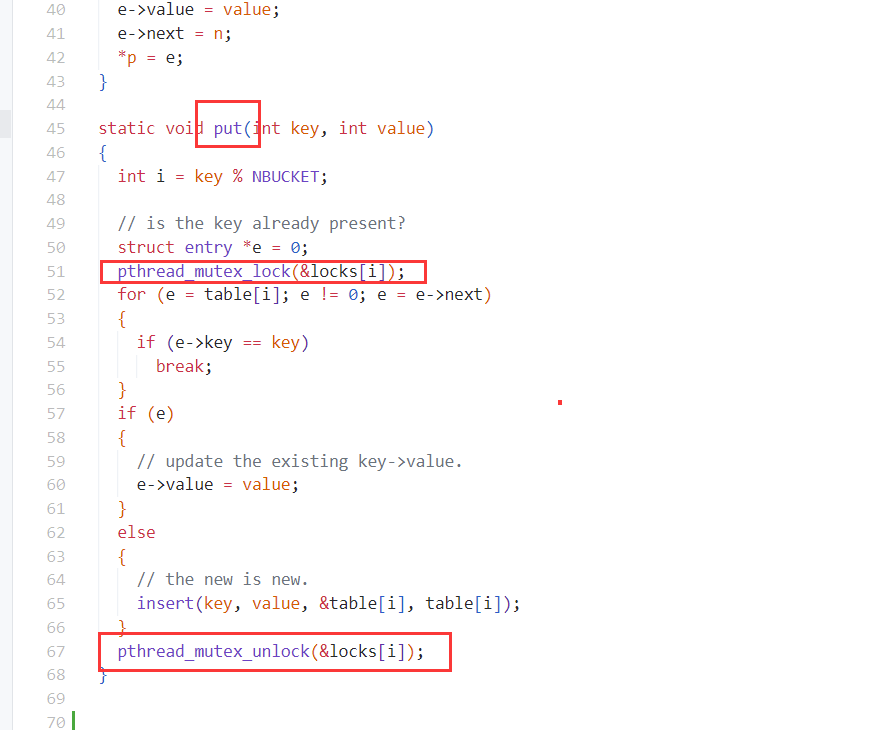
pthread_mutex_unlock(&lock); // release lockph.c : 我们尝试通过多线程对hash table k-v的插入操作进行加速,且不发生data race。
主要的两个thread函数
- put_thread
- 如何进行加速:每个thread平摊 NKEYS 100000 / threads 个 put key。(应当可以整除,不整除的话 会漏掉余下的key没put)
- 对于multi-thread多线程,在这里会发生data race。因为会改变hash table。
- get_thread
- get_thread func 用于 验证在multi-thread在put时 是否发生了 data race
- multi-thread在运行get_thread时不会发生data race,因为get_thread只读,不会改变hashtable。
- put_thread
策略:1个hash bucket 1个lock
- 由于hash table采用的是挂链法。故我们为每个hash bucket分配1个lock即可。当改变(写)这个bucket对应的list的时候,用lock进行保护。over。
- 结果
- put速度随着线程数增大和提高。基本上是2倍了。
- read速度没变化,因为每个thread做的read都是一样的,read也不需要加速,也不需要上锁保护。
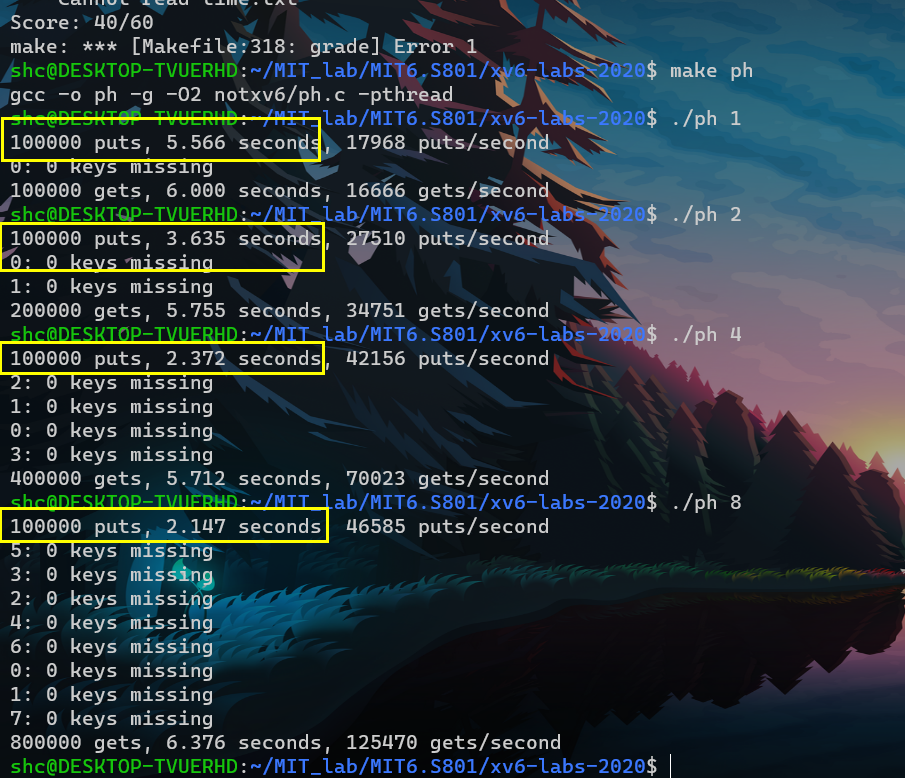
- 注:
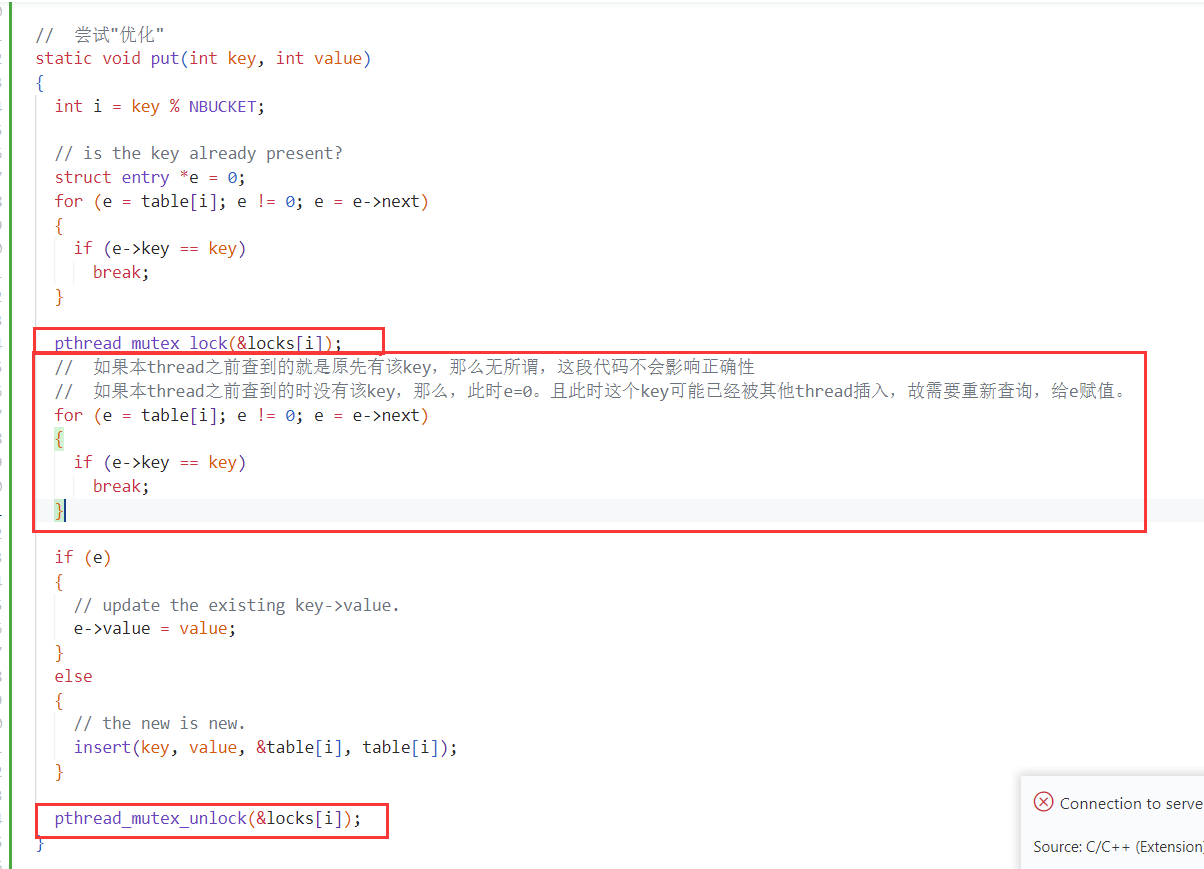
- 尝试着再减小锁的粒度。感觉貌似效果不大,甚至是负优化?
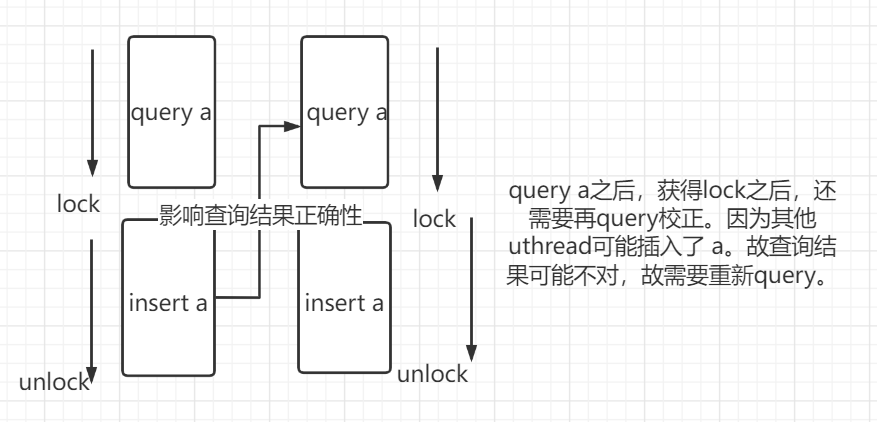
- query a之后,获得lock之后,还需要再query校正。因为其他uthread可能插入了 a。故查询结果可能不对,故需要重新query。
- 感觉是因为bucket的链表太长了。毕竟只有5个bucket。而keys总共有10000个。可以看到single thread的时候 就比之前single thread慢不少。

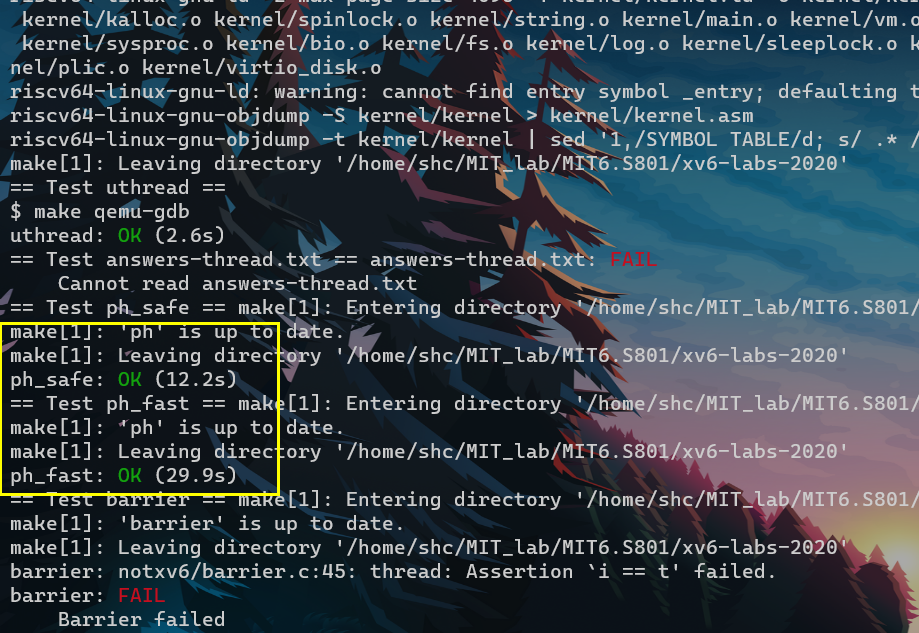
- 尝试着再减小锁的粒度。感觉貌似效果不大,甚至是负优化?
有时间还是看看linux的futex锁。。。
part3
- API
1
2pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond - pthread_cond_wait(&cond,&lock);
- (1) 释放绑定在当前线程上的lock锁
- (2) 阻塞等待cond变量符合条件。(即等待另一个线程的pthread_cond_signal(&cond))
- (3) 前两个步骤结束后,给当前线程上lock锁,结束阻塞。如果没有得到锁,会阻塞等待。
- 拿到锁之后,然后才从block变成runnable状态,受cpu调度,继续执行
- 为什么pthread_wait()要对互斥锁先解锁再上锁?因为阻塞期间拿不到资源,所以要解锁。(上个锁也没用,锁啥阿)而被唤醒后(可以)要使用共享数据,所以要解锁。
未解决问题
- 疑问
- 关于pthread_cond_broadcast的。假设一个A线程和BCD线程。BCD线程都等待在同一个mutex的cond上,易知当A线程调用pthread_cond_broadcast时,BCD中只有一个B线程拿到锁并成功的被唤醒。那么我的疑问在于,剩余的没拿到锁的CD线程呢?
- 对于这些没拿到锁的CD线程,是否需要有再一次的pthread_cond_broadcast来唤醒?
- 也即,B线程在结束时需要再次调用pthread_cond_broadcast以唤醒剩余的CD线程?
- 还是说,B线程不必再次调用pthread_cond_broadcast,只需要释放mutex即可,最开始A调用pthread_cond_broadcast会负责继续唤醒刚才没获得锁的剩余的CD线程。
已解决
- 12说法都不对
- 结论:
- B线程不必再次调用pthread_cond_broadcast,只需要释放mutex即可,剩余的CD线程拿到锁之后就继续向下走。
- 首先明确wait(cond)流程:1. 释放锁、2. 等待cond唤醒、3. 竞争锁。
- 因为cond将一系列等待该cond的thread(BCD thread)串在了一起,当Athread broadcast广播唤醒该cond时,这一系列thread(BCDthread)都不再受阻于该cond约束。
- cond唤醒后,BCDthread处于第3阶段。谁竞争到lock谁就继续向下走。比如说Bthread竞争到了lock,那么B会继续向下走,CD线程由于没有拿到lock而阻塞等待,当B释放lock之后,剩下的thread(CD thread)谁竞争到锁谁就继续向下走,与cond无关,不需要再度唤醒cond。
- 虽然CD thread还阻塞在wait语句上,但已经不是因为cond了,与cond无关,而是因为卡在了第3步,没有竞争到锁,因而陷入阻塞。
- cond:需要别人唤醒。lock:自驱。
问题
其实就是hint2,第一次读的时候还没太明白说得是啥
- You have to handle the case in which one thread races around the loop before the others have exited the barrier. In particular, you are re-using the bstate.nthread variable from one round to the next. Make sure that a thread that leaves the barrier and races around the loop doesn’t increase bstate.nthread while a previous round is still using it.
逻辑错误:对于 本轮的 thread还没有全部离开barrier,下一轮的thread就进入barrier,使得将下一轮的thread的数量 计数在 本轮的 nthread中,造成错误。
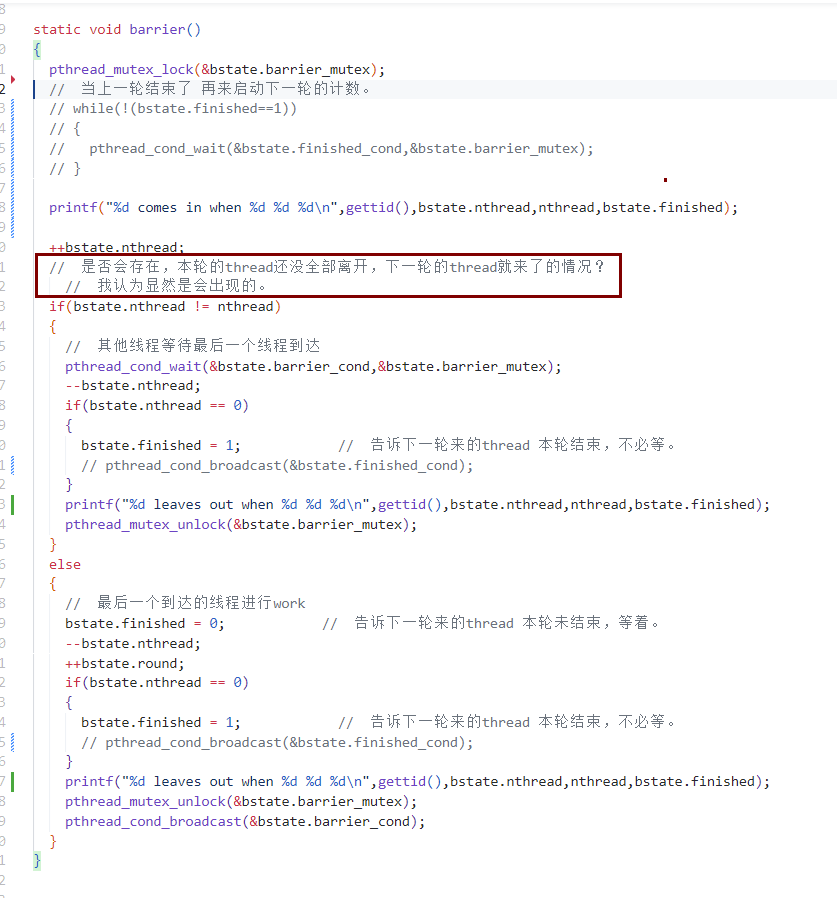
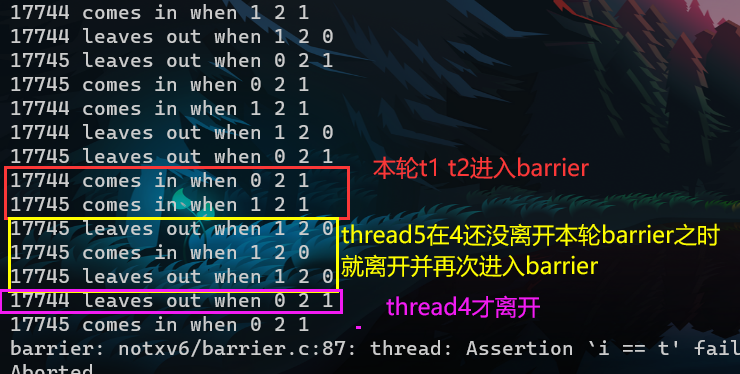
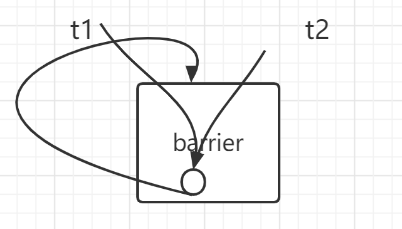
解决措施:添加一个finished_cond条件变量,代表上一轮round已经结束,也即上一轮的thread都已经离开barrier,可以开始本轮的thread计数,也即可以让本轮的thread进入barrier了。
实现
我所做的工作
添加个finished_cond 以及 finished 配合 条件变量使用
- finished = 1时,代表上一轮已经结束,当前thread可以进入barrier
- finished = 0时,代表上一轮没结束,正在运行,当前thread不可进入barrier。故 pthread_cond_wait when finished = 0。
1
2
3
4
5
6
7
8
9struct barrier {
pthread_mutex_t barrier_mutex;
pthread_cond_t barrier_cond;
int nthread; // Number of threads that have reached this round of the barrier
int round; // Barrier round
// 上一轮的thread 是否都已经从barrier中离开
pthread_cond_t finished_cond;
int finished;
} bstate;
finished_cond:等待上一轮的所有thread全部离开barrier
barrier_cond: 等待本轮的所有thread全部到达barrier
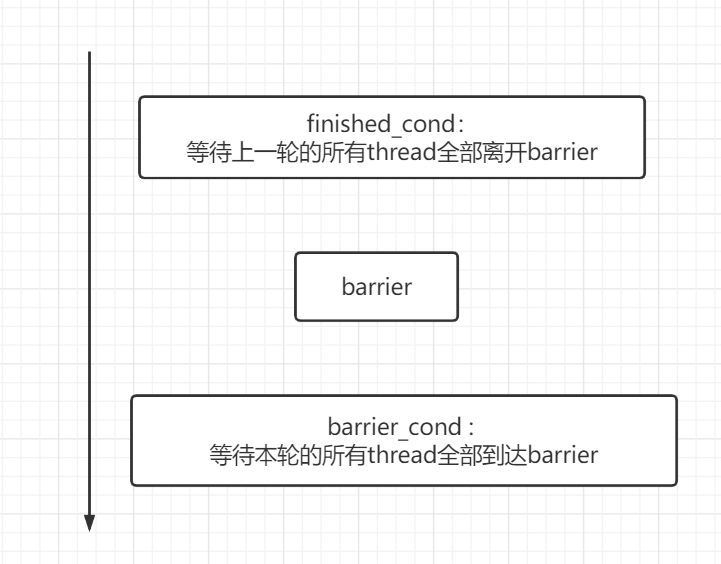
code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43static void barrier()
{
pthread_mutex_lock(&bstate.barrier_mutex);
// 当上一轮结束了 再来启动下一轮的计数。
while(!(bstate.finished==1))
{
pthread_cond_wait(&bstate.finished_cond,&bstate.barrier_mutex);
}
// 确保上一轮thread都离开barrier之后,本轮thread真正进入barrier,并进行计数。
++bstate.nthread;
// 是否会存在,本轮的thread还没全部离开,下一轮的thread就来了的情况?
// 我认为显然是会出现的。
if(bstate.nthread != nthread)
{
// 其他线程等待最后一个线程到达
pthread_cond_wait(&bstate.barrier_cond,&bstate.barrier_mutex);
--bstate.nthread;
// 告诉下一轮来的thread 本轮结束,不必再等,可以进入barrier。
if(bstate.nthread == 0)
{
bstate.finished = 1;
pthread_cond_broadcast(&bstate.finished_cond);
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}
else
{
// 最后一个到达的线程
// 告诉下一轮来的thread 本轮未结束,等着,不可进入barrier。
bstate.finished = 0;
--bstate.nthread;
++bstate.round;
// 告诉下一轮来的thread 本轮结束,不必再等,可以进入barrier。
if(bstate.nthread == 0)
{
bstate.finished = 1;
pthread_cond_broadcast(&bstate.finished_cond);
}
// 唤醒本轮的在barrier中等待的thread,告诉他们可以离开barrier。
pthread_mutex_unlock(&bstate.barrier_mutex);
pthread_cond_broadcast(&bstate.barrier_cond);
}
}pass
做完lab之后看一下initcode。