实现二级间接块、实现软链接系统调用
PART1
背景
实验目的:就是扩增一个inode所能引用的datablock大小
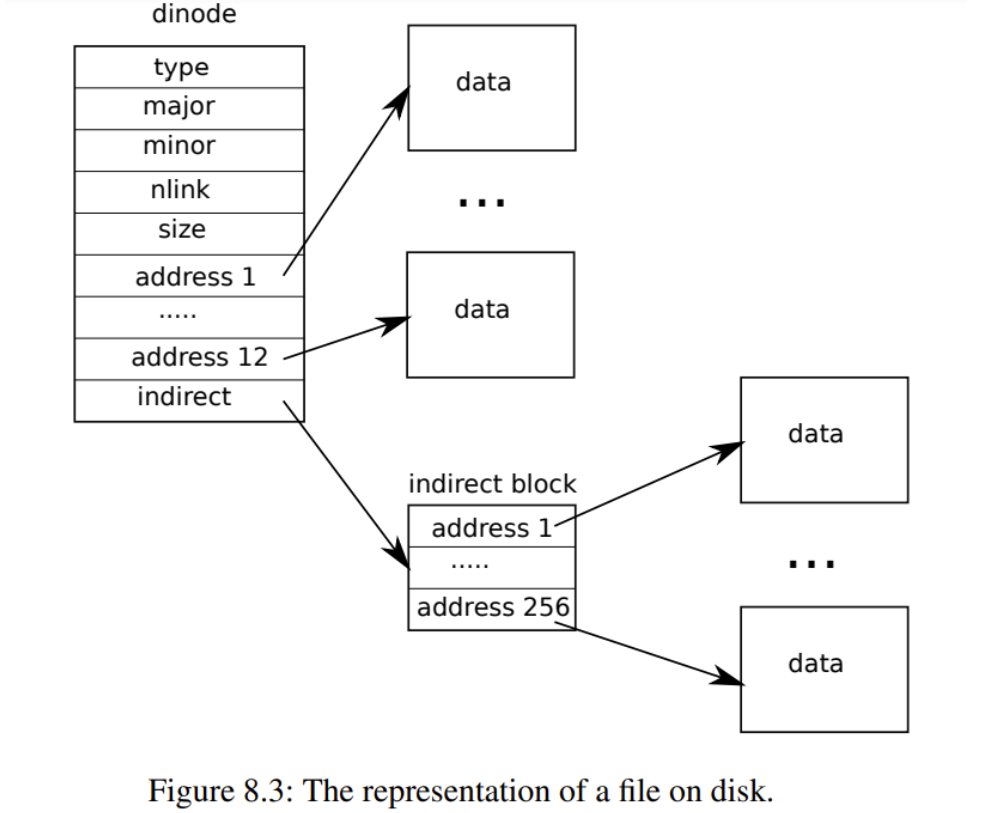
原先inode的结构如下
- addrs[0,11]是直接块
- addrs[12]是一级间接块
- 总共能引用的block 数量为 268 = 12 + 256
改动后的结构如下
- addrs[0,10]是直接块
- addrs[11]一级间接块
- addrs[12]二级间接块
- 总共能引用的block 数量为 65803 = 11 + 256 + 256*256
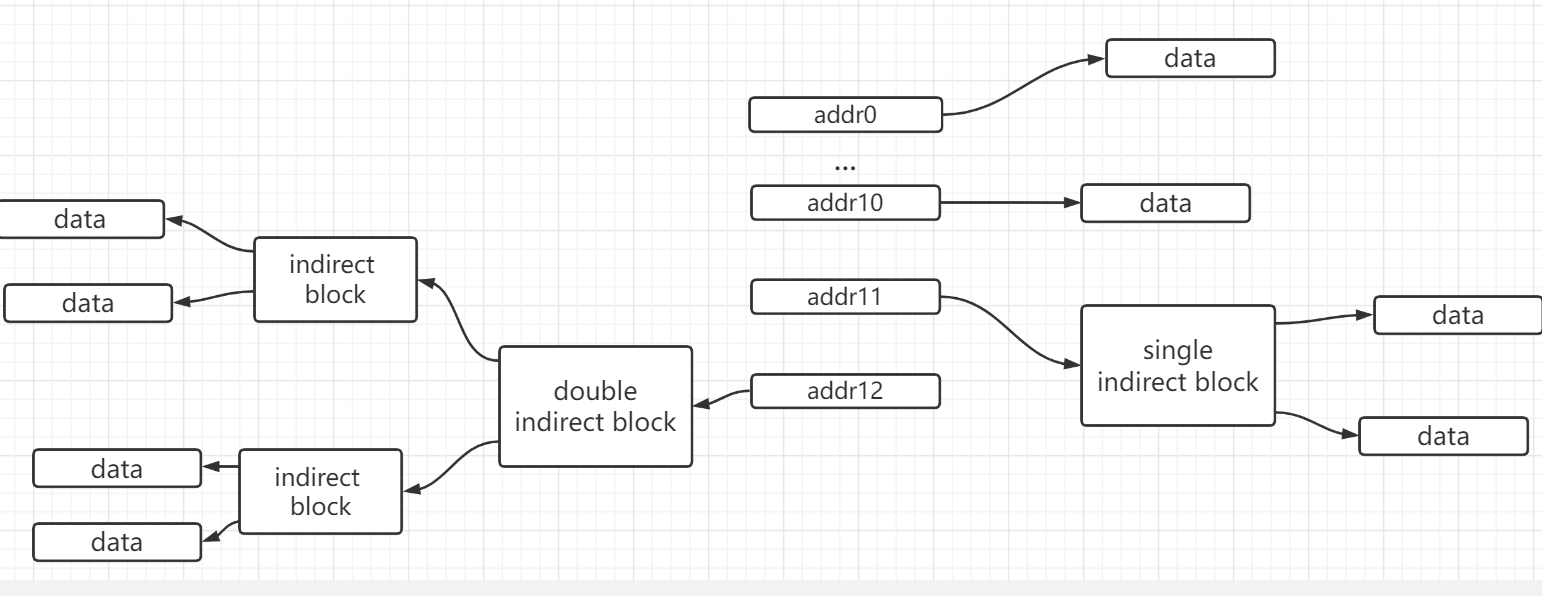
我愿将single indirect block 称为一级块表, double indirect block 称为二级块表
实现
以下为我所做的工作
struct inode和dinode中的addrs数组
1
2
3
4
5
6
7
8
9
10// On-disk inode structure
struct dinode {
short type; // File type 文件 / 目录 / 特殊文件 / 0表示inode空闲
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+2]; // Data block addresses 保存inode代表的文件的内容的磁盘块号
// 11 * direct block + 1 single indirect block + 1 * double indirect block
};bmap
- 功能: 查询并返回ip所引用的第bn个datablockno。过程中按需分配datablock。
- 可以看成是将inode的逻辑块号转化成disk上的物理块号。
- 修改:增添对于二级块表的从逻辑到物理的映射的处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71static uint bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// 1. NDIRECT = 11
// 11 个 direct block
// 如果inode的bn为直接地址块,且还没引用datablock
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
// 2. NINDIRECT = 256
// 1 个 single indirect block
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
// get indirect block cache
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
// 如果第bn项并没有指向一个block,则为其balloc分配一个freeblock,并记录
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp); // bread brelse 搭配
return addr;
}
bn -= NINDIRECT;
// 3. DOUBLE_NINDIRECT = 256 * 256
// 1 个 double indirect block
if(bn < DOUBLE_NINDIRECT)
{
// addr pointed to the first level indirect block
if((addr = ip->addrs[NDIRECT+NINDIRECT]) == 0)
{
ip->addrs[NDIRECT+NINDIRECT] = addr = balloc(ip->dev);
}
bp = bread(ip->dev,addr);
a = (uint*)bp->data;
int n = bn / NINDIRECT;
int m = bn % NINDIRECT;
// the first level indirect block pointed to the second level indirect block
if((addr = a[n]) == 0)
{
a[n] = addr = balloc(ip->dev); // modify cache
log_write(bp);
}
brelse(bp);
// the second level indirect block pointed to the target data block
struct buf *m_bp = bread(ip->dev,addr);
uint *m_a = (uint*)m_bp->data;
if((addr = m_a[m]) == 0)
{
m_a[m] = addr = balloc(ip->dev);
log_write(m_bp);
}
brelse(m_bp);
return addr;
}
// 如果块号超过NDIRECT+NINDIRECT,则bmap调用panic崩溃
panic("bmap: out of range");
}
同理,在itrunc释放块表的时候也需要释放下二级块表
- 注意不要忘记清空addrs本身
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40void itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
// 释放所有直接引用的disk上的块 并清空addrs
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
// 释放所有间接引用的disk上的块 并清空addrs
if(ip->addrs[NDIRECT]){
walkfreeblock(ip->addrs[NDIRECT],ip);
ip->addrs[NDIRECT] = 0;
}
// 释放double indirect block 及 其所引用的block
if(ip->addrs[NDIRECT + NINDIRECT])
{
bp = bread(ip->dev,ip->addrs[NDIRECT + NINDIRECT]);
a = (uint*)bp->data;
for(j = 0; j<NINDIRECT;++j)
{
if(a[j])
walkfreeblock(a[j],ip);
}
brelse(bp);
// 释放二级块表本身
bfree(ip->dev,ip->addrs[NDIRECT + NINDIRECT]);
ip->addrs[NDIRECT + NINDIRECT] = 0;
}
// inode代表的文件大小为0
ip->size = 0;
// 更新inode之后 应当立刻落入磁盘记入日志
iupdate(ip);
}
- 注意不要忘记清空addrs本身
工具函数
- 释放single indirect block所引用的256个datablock,并释放一级块标自身所占的datablock
- 传入一级块表的所在的datablock的blockno,以及disk编号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// blockno是一块direct address blockno
// 其中所有的数据都是指向datablock。也即都是datablockno
// walkfreeblock : 存储在释放blockno中引用的所有datablock
static void walkfreeblock(int indirect_blockno,struct inode *ip)
{
struct buf *bp = bread(ip->dev,indirect_blockno);
uint* pd = (uint*)bp->data; // pointer to datablock
for(int k=0;k<NINDIRECT;++k)
{
if(pd[k])
bfree(ip->dev,pd[k]);
}
brelse(bp); // 不要忘记释放自身cache
bfree(ip->dev,indirect_blockno); // 不要忘记释放自身
}
PART2
背景
约定路径为path:path处有个entry指向该inode
软链接文件的inode为:symbolic inode
- 目标:为xv6实现软链接系统调用。
- int symlink(char *target, char *path)
- 在路径path,创建一个symbloic inode,导向target下的inode
- 即便目标target inode并不存在,symlink也可以成功。只是当open symbolic inode时会fail。
- success : return 0;
- fail : return -1
- open symbolic inode时,如果trace到的还是一个symbloic inode,那么递归的追踪下去,直到深度超过上限。
- You do not have to handle symbolic links to directories for this lab.
实现
- 我所做的工作如下
- 新增一种inode类型:T_SYMLINK,代表symbolic inode
- open新增一种访问权限:O_NOFOLLOW
- When a process specifies O_NOFOLLOW in the flags to open, open should open the symlink (and not follow the symbolic link).
uint64 sys_symlink(void)
- 创建一个symbolic inode
- 向该symbolic inode的datablock写入数据:char *target。当open的时候访问该target路径对应的inode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42uint64 sys_symlink(void)
{
char target[MAXPATH] = {0};
char path[MAXPATH] = {0};
if(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)
return -1;
begin_op();
// 1. 创建一个symbolic inode
struct inode* ip = namei(path);
if(ip==0)
{
// 如果之前没有,创建inode
ip = create(path,T_SYMLINK,0,0);
if(ip == 0)
{
end_op();
return -1;
}
itrunc(ip); // 清空inode的引用
}
else
// 如果之前就有,那么写覆盖datablock即可
{
ilock(ip);
}
// 2. 向该symbolic inode的datablock写入数据:char *target。当open的时候访问该target路径对应的inode
int ret = writei(ip,0,(uint64)target,0,MAXPATH);
if(ret != MAXPATH)
{
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip); // 注意这里应当是iunlockput而非iunlock
end_op();
return 0;
}
sys_open
- 增添两部分
- 对于访问symbolic inode
- 递归的找到target inode 然后访问
- 对于以O_NOFOLLOW方式访问symbolic inode
- 直接访问symbolic inode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58uint64 sys_open(void)
{
begin_op();
// create 创建inode
if(omode & O_CREATE){
// 寻找已有inode
} else {
// open("/testsymlink/b", O_RDWR)
if((ip = namei(path)) == 0){
end_op();
return -1;
}
// 1. trace symlink .
// 失败则返回NULL ,syscall return -1。
// 成功则获得目标inode指针 , syscall return fd。
if(ip->type == T_SYMLINK && ((omode & O_NOFOLLOW) == 0))
{
ip = dfs_trace_symlink(ip,0);
if(ip == 0)
{
end_op();
return -1;
}
}
// 2.
else
{
ilock(ip);
}
if(ip->type == T_DIR && omode != O_RDONLY){
iunlockput(ip);
end_op();
return -1;
}
}
// ...
// 从ftable中分配free struct file 来承载inode + 从p->ofile中分配free fd 来索引struct file
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
// ...
iunlock(ip);
end_op();
return fd;
}
- 工具函数 dfs_trace_symlink
- 递归的追踪symbolic inode
- 如果超出最大深度,则返回0
- 如果是要target路径的inode不存在,则返回0
- 如果本inode是个非symbolic inode,那么返回该inode
- 注意在读写inode之前(如通过readi读取),一定要先通过ilock(inode)锁定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// fail : return 0
// success : return locked inode*
static struct inode* dfs_trace_symlink(struct inode *ip,int h)
{
// 如果超出最大深度,则返回0
// 如果是要target路径的inode不存在,则返回0
if(h > 10 || ip == 0) {return 0;}
// 注意!!!
// 在读写inode的元数据或内容之前,代码必须使用ilock锁定inode
ilock(ip);
// 如果本inode是个软链接inode,那么一路追踪到非软链接inode
if(ip->type != T_SYMLINK) return ip;
char target[MAXPATH] = {0};
int ret = readi(ip,0,(uint64)target,0,MAXPATH);
if(ret != MAXPATH) panic("open symlink");
iunlockput(ip);
struct inode* ne = namei(target);
return dfs_trace_symlink(ne,h+1);
}
待解决问题
- 遇见bug:
- 在sys_symlink中,不再引用inode时我只是iunlock(inode),并没有iunlockput(inode),造成panic virtio_disk_intr status
- iunlock(inode ip)
- 只是释放了当前thread对于该ip的占有,不意味着该ip对本thread已经无用,意味着稍后该ip仍会存在于inode cache,不会从inode cache中踢出。长此会造成inode cache满。
- iunlockput(inode ip)
- iunlock (inode) : 不但释放了当前thread对于该ip的占有
- iput(inode) : 还多了一步,也即释放了本thread对于ip的引用(通过减小ip的ref)
- 意味着本thread再也不会引用该ip。如此,ip的ref引用计数降至0,那么该ip就可以从inodecache中替换走。
- 不过我还是不知道为什么这样会造成panic virtio_disk_intr status。我以为应当造成的是iget: no inodes。
- 拿下

小结
话说path追踪的时候会用到entry吗?
会。
最一开始的directory inode 如何得到 ?
开始path追踪时,会天然的得到path最一开始所在的目录inode
因为该path 要么是一个绝对路径(从root’/‘开始),要么是一个相对路劲(从本目录开始),这两个都可以直接得到。
如何用到entry?
追踪时会扫描当前追踪到的directoy inode的entry,检查是否有path中的目标下一级(根据name是否是下一级目标enrty)的entry。
如果有,则使用该entry(通过inum)索引到的inode,继续遍历该direcoty inode。
如果该inode不是directry inode,且name等于path的最后一级元素,则搜索inode成功。
文件表 文件描述符表 file inode
对比一下Linux中的概念
Linux中的全局的文件表,在xv6中体现为全局的ftable
- 所有打开的文件以struct file的形式都存在于ftable
1
2
3
4struct {
struct spinlock lock;
struct file file[NFILE];
} ftable;
- 所有打开的文件以struct file的形式都存在于ftable
每个进程的文件描述符表
- fd table
- <fd - struct file *>
- fd table 的 file* 指向ftable里的 file。struct file又指向inode
1
2
3struct proc{
struct file *ofile[NOFILE]; // Open files
}
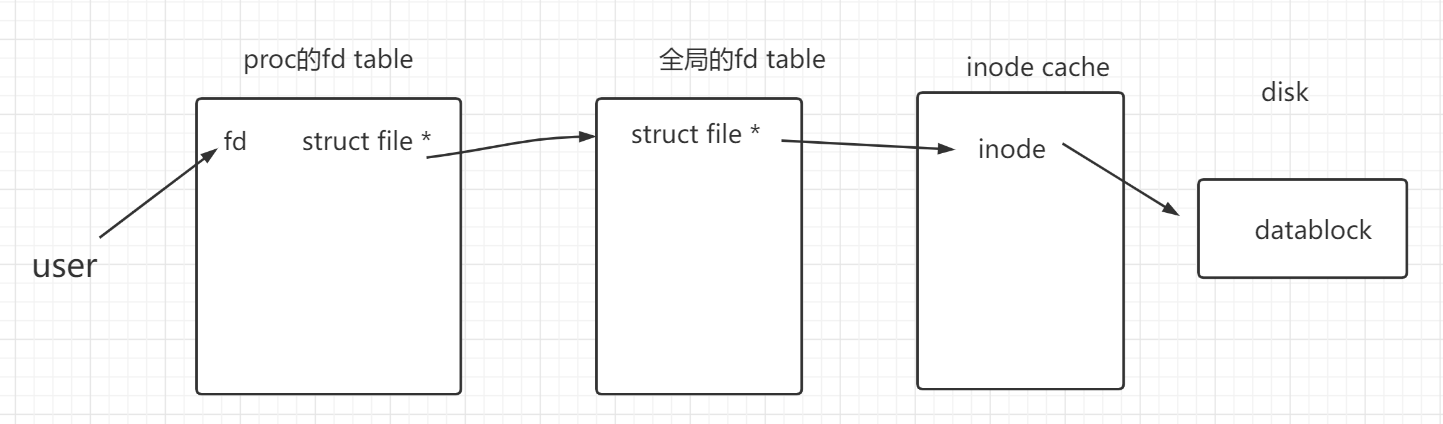
- 我们用户程序是如何使用file的?
- 打开file并以fd来引用他
- open -> sys_open
- sys_open
- 创建(create)/找到(namei)已有文件
- 从全局的ftable中分配free struct file 作为该文件结构体
- filealloc()
- 从进程的fd表ofile中分配fd来给该struct file*。也即,在fd表中记录了fd-struct file*
- fdalloc()
- 设置struct file的一些metadata如权限
- return fd to user
- sys_open
- 之后用户在即可通过fd来引用文件。
- fd -> struct file -> inode
- 如read(fd, &de, sizeof(de)
- read -> sys_read
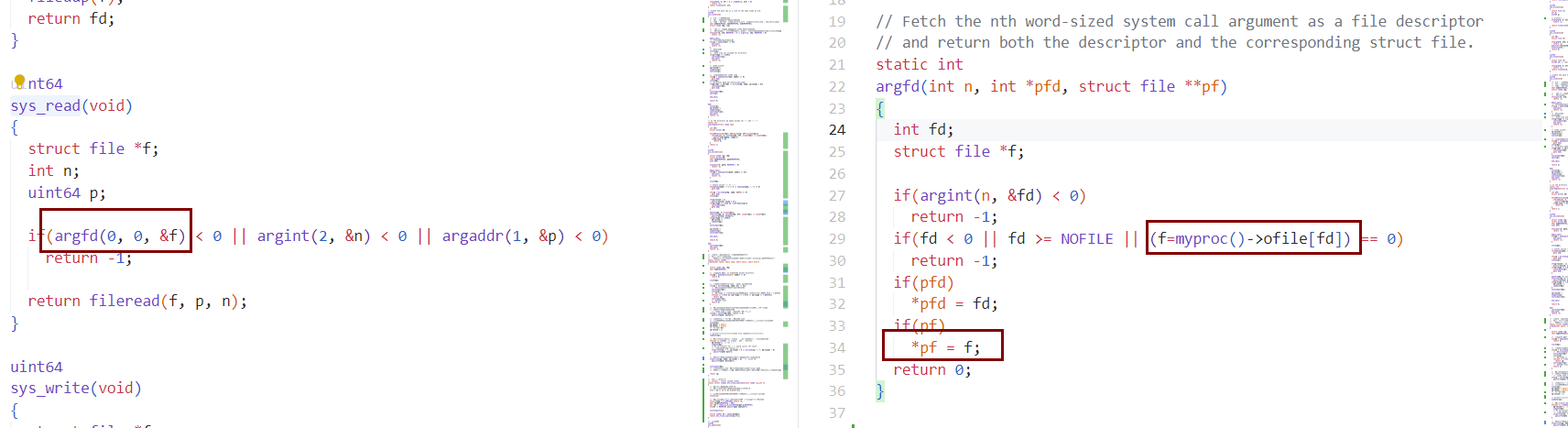
- read -> sys_read
name是inode的属性吗?
- 不是的。name是entry的属性。entry通过inum索引到inode。
- entry(name,inum)
1
2
3
4
5// 文件夹中的一系列entry 而非 文件夹
struct dirent {
ushort inum; // 用于索引inode
char name[DIRSIZ];
};
我们在目录下看到的,实际上是一个个条目entry。ls时是读取了并打印了目录下的所有entry。
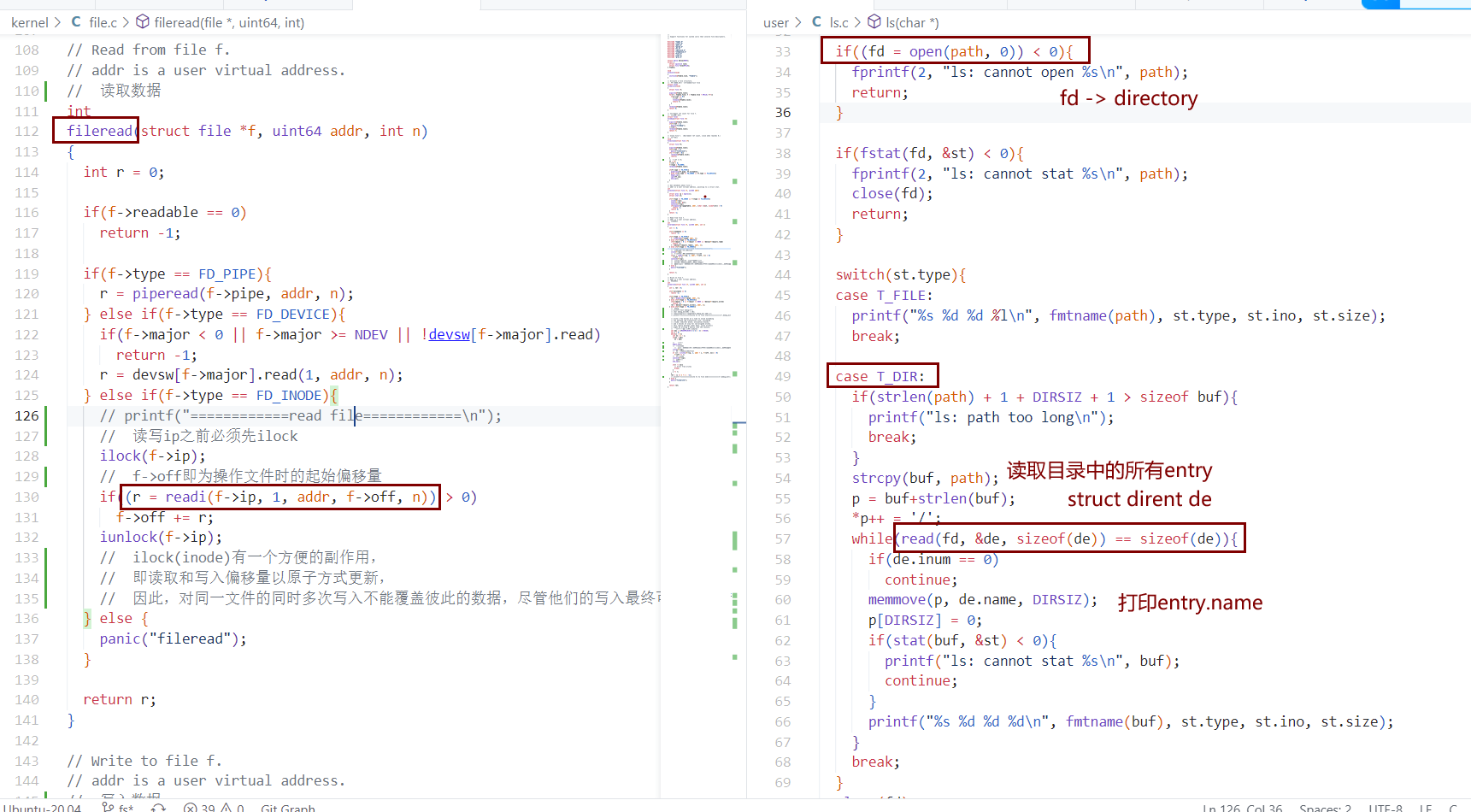
directory 和 entry 和 其他inode的关系
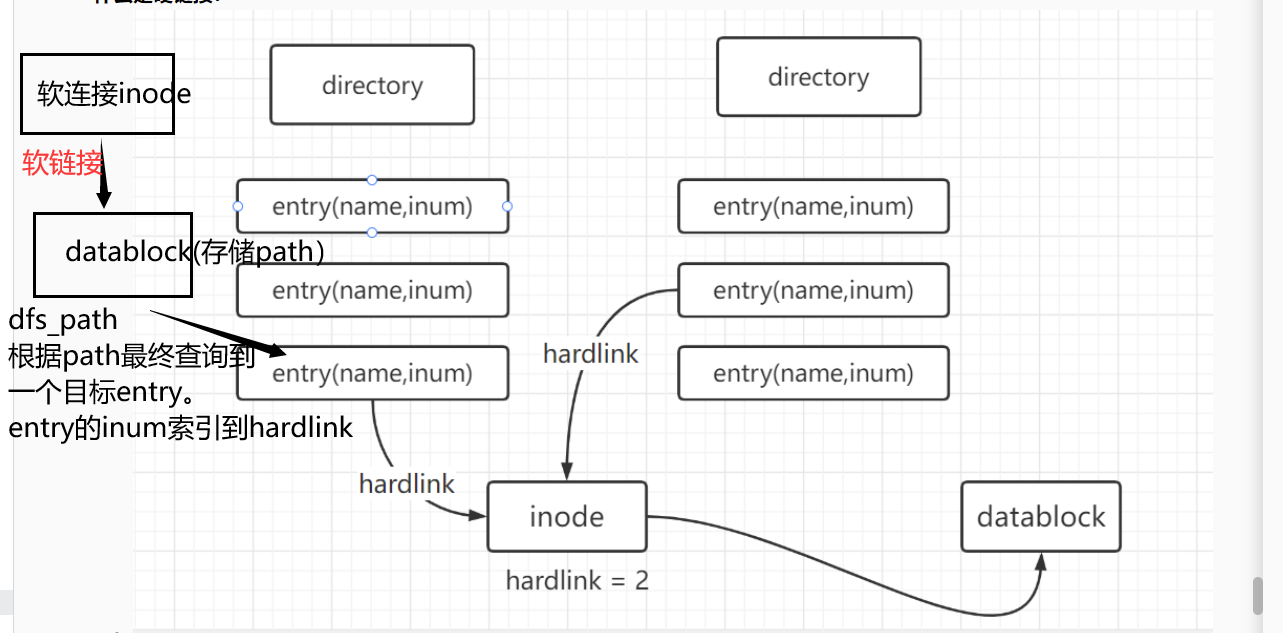
硬链接、软链接
- 什么是硬链接?
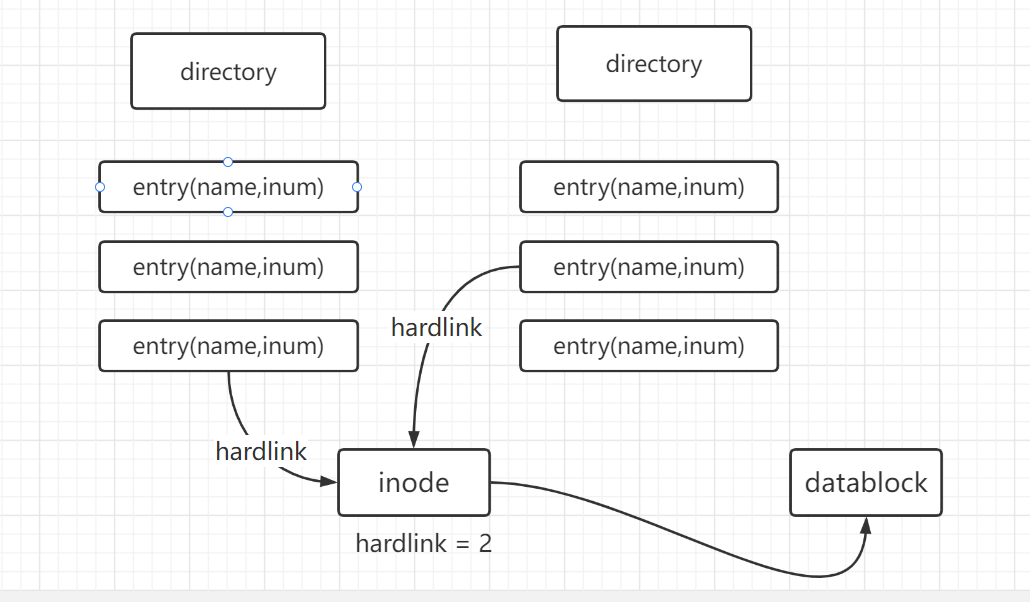
- name是entry的属性;hardlink是inode(dinode)的属性。
- 硬链接:引用本inode的entry的数量
- entry是真实存在于disk上的结构,断电之后还会保存在磁盘里面
- 一个entry指向一个inode,就是该inode一条硬链接hardlink。
- 多个entry指向同一个inode,就是该inode的多条hardlink。
- hardlink!=0时,该disk上的dinode就不会被释放。当nlink = 0时,就在disk上真正释放该inode。xv6中相关函数为iput。
- 可以看到,硬链接并不是文件,也即并不是inode,不以inode的形式存在。而是作为directory inode的数据存在于其datablock中。
- 什么是软链接?
- 与硬链接不同,硬链接是entry,而软链接是个文件,以inode的形式存在
- 软链接的datablock中存储的是 target inode path
- 通过open访问软链接inode时,通过其datablock的存储的路径去访问那个路径对应的inode。
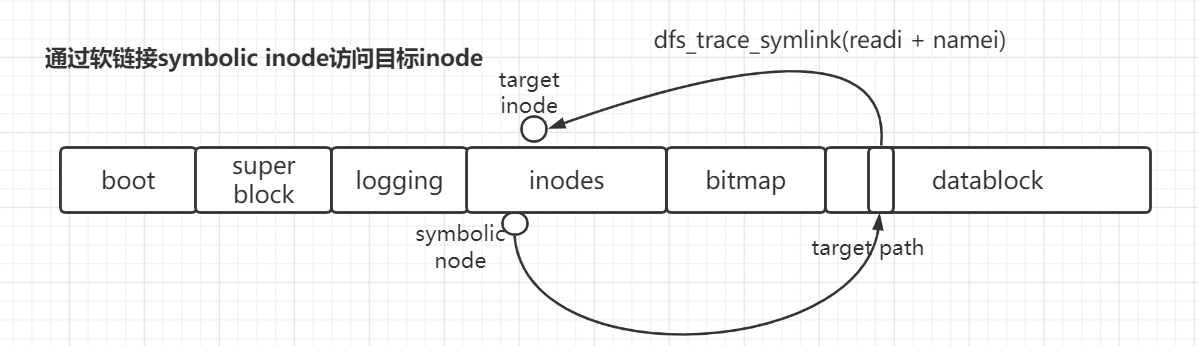
- 如何利用path找到对应inode的?
- 接口:namex(path)
- namex(path) -> dirlookup(dp,name) -> iget(inum)
- 将path一级级,逐级拆分出一个个name。
- 在每一级拆分出一个name之后,
- 通过dirlookup在当前directory inode下查找出name对应entry,进而得到inum。
- dirlookup 遍历directory inode的datablock的entry
- 得到inum之后,通过iget(inum),遍历inode cache,(从中找出/从磁盘加载出)inum匹配的inode
- 在非最后一轮,得到的inode应该是个directory inode
- 通过dirlookup在当前directory inode下查找出name对应entry,进而得到inum。
- 拆解到最后一轮,iget所得到的inode就是path最后一个element的inode。