void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
本实验实现了简易的mmap syscall(阉割版). 实现所谓的将”文件映射到内存”
对比
- 现代OSmmap : disk -> kernel buf. user va映射到kernel bu
- 实现的xv6mmap : disk -> kernel buf -> user physical mem. user va映射到 physical mem
- 且没有实现MAP_PRIVATE,MAP_SHARED时的共享mem,也没实现MAP_PRIVATE的cow
实现关键 : lazy allocation
- mmap 先获取一块vma区域 但并不建立映射, 仅仅设定这块va合法 ; 当发生pgfault的时候,再读取文件相应内容 , 为va建立映射 , 然后返回.
- munmap 就是解除vma内建立了映射的va
mmap优势
- 效率高,高于普通的read file
- 比起read少一次拷贝. 映射到kenerl buf
- 减少陷入内核次数,减少上下文切换开销.(read每次都陷入)
- lazy allocation(不必一次全部读入)
- 更加方便user读写文件
- 这也就是mmap所谓的 “映射文件到用户进程”。
- user调用mmap之后 , 可以将对内存的读写看成对文件的读写,如何加载数据,如何落入磁盘 等都不需要user管.
- 效率高,高于普通的read file
prot : 对内存权限 ; flags : 对file权限。 二者不可冲突
背景
在xv6中实现 mmap munmap
mmap:将用户的虚拟地址(user virtual address)映射到内核占有的物理内存。其中物理内存中保存的是自file中读出的数据。
munmap:解除映射。
- vma : 约定将 vma 称为 user通过mmap建立映射时,被kernel选择的用户的虚拟地址范围的那一块区域的虚拟内存
- vma也即映射到的虚拟内存。也即mapping memory。
- 将 mmap将vma映射到的真实的物理地址范围的物理内存(其中有file的数据) 称为 目标物理内存
API含义
**void \*mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);***- addr : 0
- kernel替user选择,将user的哪部分虚拟地址范围作为映射区域。
- length : vma区域的大小
- prot 对于内存权限 :
- user关于vma虚拟内存区域/映射到的物理内存(一样,反正对vma读写就是在对physical mem读写)的权限,不可以和file的打开模式冲突。
- The prot argument describes the desired memory protection of the mapping (and must not conflict with the open mode of the file).
- PROT_READ
- Pages may be read。vma的每页可以读。
- PROT_WRITE
- Pages may be written。vma的每页可以写。
- PROT_EXEC
- Pages may be executed。vma的每页可执行。
- flags 对于file的权限(写回标志) + process之间是否共享physical mem
- MAP_SHARED
- Share this mapping. Updates to the mapping are visible to other processes mapping the same region, and (in the case of file-backed mappings) are carried through to the underlying file.
- 共享mapping。
- 1. 也即,当file相同时,不同process将各自的vma映射到同一块目标physical memory。一个process对vma进行修改(也即对vma映射到的physical memory修改),其他process都可以看到。(因为映射到的是同一physical mempry)
- 2. 且,当munmap解除vma到dram的映射时,会将physical memory的修改(通过dirty bit判断)写回disk上的file。
- lab实现区别:对于MAP_SHARED , 本lab只实现了2,1的话lab没做要求。(对于MAP_SHARED,正常来讲,第一个process会lazy allocation分配vma映射到的physicalmem,其余process会直接指向该块physicalmem。然而本lab中实现的仅仅是每个process都lazy allocation一块physical mem)也即,本实验只是实现了将vma映射到的physical mem写回disk。
- MAP_PRIVATE
- Create a private copy-on-write mapping. Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file.
- 创建一个写时复制的映射。
- 我理解的是:
- 当file相同时,第一个process会为vma进行lazy allocation一块phyiscal mem,其余的process再使用他们自己的vma时,先映射到第一个process lazy alloc的pm,然后当某个process发生写动作时,该process再进行copy on write。
- 对于file加载进的physical mem的修改,在munmap解除映射时,不会落入disk。
- lab实现区别:然而本lab实现的,并没有实现copy on write,仅仅实现了对于每个process,当其要使用vma的某一page时,都要进行lazy allocation。也即每个process即使在读vma时,其映射到的physical mem也是各自独享的。
- MAP_SHARED
- addr : 0
int munmap(void *addr, size_t length);
- The munmap() system call deletes the mappings for the specified address range, and causes further references to addresses within the range to generate invalid memory references. The region is also automatically unmapped when the process is terminated. On the other hand, closing the file descriptor does not unmap the region.
- 解除从vma到physical mem的映射。后续process的vma变成无效的虚拟地址;
- 当进程exit时,vma区域会自动解除映射;
- user close(fd)不会导致vma映射解除,也不会导致lazy allocation失败。
- After the mmap() call has returned, the file descriptor, fd, can be closed immediately without invalidating the mapping
- 即当mmap返回后 关闭fd文件 映射依然有效。
- 因为mmap时会自动将struct file的引用计数++,防止被从ftable中替换走;知道munmap时,才会–struct file
例子
- char *p = mmap(0, PGSIZE*2, PROT_READ, MAP_PRIVATE, fd, 0);
- 0: kernel choose the virtual address。内核选择负责映射到的用户虚拟地址
- PGSIZE*2 : 映射多少bytes内存
- PROT_READ : the mapped memory is read-only。用户对这段用户虚拟地址只能读、不能写
- MAP_PRIVATE :
- 如果进程修改了这段映射的内存,修改的内容不会被写回文件、也不会与其他映射同一文件的进程共享。
- fd :file
- 0 : offset
- char *p = mmap(0, PGSIZE*2, PROT_READ, MAP_PRIVATE, fd, 0);
mmap核心思想:(我感觉)
在user的va中划出一片区域,将文件内容映射其中。让user可以像操作内存数据一样,操作文件数据。也即使得user访问其virtual address就是在访问文件
更加方便user读写文件。
实现
我所做的工作如下
mmap
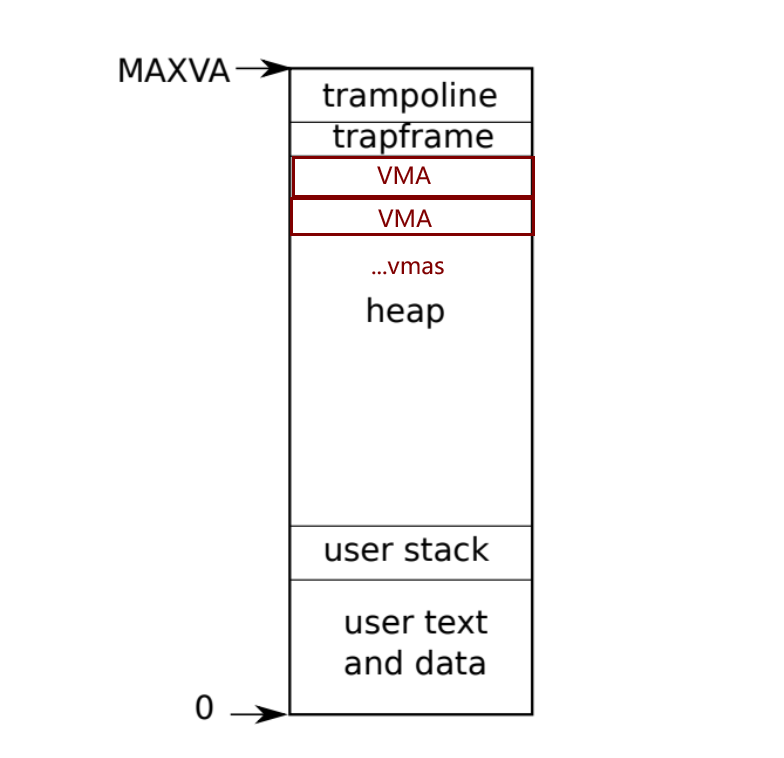
设计:将user process的最上方的可用虚拟地址,作为vma。也即自TRAPFRAME向下,选取虚拟内存区域作为vma。
struct vma : process用作映射到physical mem的virtual mem区域。(physical mem中是file的内容),然后为proc结构体添加vma数组。
- 是否有效、映射文件、映射范围、对mem(物理/虚拟一样,一个效果)的权限PROT、对file的权限(写回标志)、映射file的起始偏移量。
1
2
3
4
5
6
7
8
9
10
11
12
struct vma
{
int valid; // 是否有效
struct file *f; // 映射的文件
uint64 start; // user该段映射的起始虚拟地址 根据上一次映射的最低地址和本次的sz来确定。PGSIZE对齐
uint64 sz; // PGSIZE对齐。[start , end = start + sz - 1]
uint64 left; // vma中剩余的还没被释放的bytes数量
int prot; // 权限: 对mem的权限。PROT_READ PROT_WRITE
int flag; // 权限: 对file的权限。MAP_PRIVATE MAP_SHARED 是否写回文件。是否和其他process共享physical mem
uint64 offset; // 映射文件的起始偏移量
};
- 是否有效、映射文件、映射范围、对mem(物理/虚拟一样,一个效果)的权限PROT、对file的权限(写回标志)、映射file的起始偏移量。
实现 系统调用mmap
- 思想:和之前的lazy allocation lab相同,分为两步
- 1. sys_mmap 将vma的这段虚拟地址标记为合法,但未建立映射
- 2. pgfault handler : lazy allocation。然后当user process使用该段虚拟地址、进而触发pagefault时,对其进行lazy allocation。
- 与lazyalloc lab不同的是
- 这里只需要考虑user使用未建立映射的user va
- 而不需要考虑kenrel使用未建立映射的user va
- 因为只有user会调用mmap
- 与lazyalloc lab不同的是
- 思想:和之前的lazy allocation lab相同,分为两步
实现sys_mmap
- 取user传参
- 判定prot、flag 和 file 权限是否矛盾
- 寻找free的vma槽 并 计算 vma的start,end。
- 初始化vma
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61uint64 sys_mmap(void)
{
// 1. 取user传参
argaddr(0,&addr); argaddr(1,&sz); argint(2,&prot);
argint(3,&flag); argint(4,&fd); argaddr(5,&offset);
struct proc *p = myproc();
// 获取fd的file
struct file *f = p->ofile[fd];
// 2. 判定prot、flag 和 file 权限是否矛盾
// file不可读 user要求可读
if( (!f->readable) && (prot & PROT_READ) )
{
printf("file can not read but you want to read\n");
return -1;
}
// file不可写 user要求写file
// f->writable : file可写
// PROT_WRITE : user要求写映射内存
// flag : user要求将写的内容落入磁盘
if( (!f->writable) && ((prot & PROT_WRITE) && (flag & MAP_SHARED)) )
{
printf("file can not write but you want to write\n");
return -1;
}
// 3. 寻找free的vma槽 并 计算 vma的start,end。
sz = PGROUNDUP(sz); // sz对PGSIZE对齐
uint64 mapuplimit = TRAPFRAME;
int idx = 0;
int found = 0;
for(int i = 0 ; i < NVMA ; ++i)
{
if(p->vmas[i].valid == 0 && !found)
{
p->vmas[i].valid = 1;
idx = i;
found = 1;
}
// 找到proc中最低的 可以提供给 mmap的 end虚拟地址
else if(p->vmas[i].valid == 1 && mapuplimit > p->vmas[i].start)
{
mapuplimit = p->vmas[i].start; // 一定是对PGSIZE对齐的。
}
}
// 4. 初始化vma
p->vmas[idx].f = f;
p->vmas[idx].sz = sz;
p->vmas[idx].left = sz;
p->vmas[idx].start = PGROUNDDOWN(mapuplimit - sz); // start一定是PGSIZE对齐的 sz可能不是
p->vmas[idx].prot = prot;
p->vmas[idx].flag = flag;
p->vmas[idx].offset = offset;
filedup(f); // ++ref
// 增加struct file 引用计数
// 这样即使user关闭了文件,struct file也至少有一个引用计数由mmap的vma管理,防止struct file在ftable中被替换掉
return p->vmas[idx].start;
}
pagefault handler : lazy allocation
- trap : 自不必说,判断是否落入vma区域
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if(r_scause() == 15 || r_scause() == 13)
{
printf("pagefault %p cause %d\n",r_stval(),r_scause());
uint64 pgault_va = r_stval();
struct vma *vma = 0;
// 判断是否是被映射的地址范围 若是则获取相应vma
if(!validMmap(pgault_va,&vma))
{
p->killed = 1;
}
else
{
uvmlazyMmap(vma,pgault_va);
}
}
- trap : 自不必说,判断是否落入vma区域
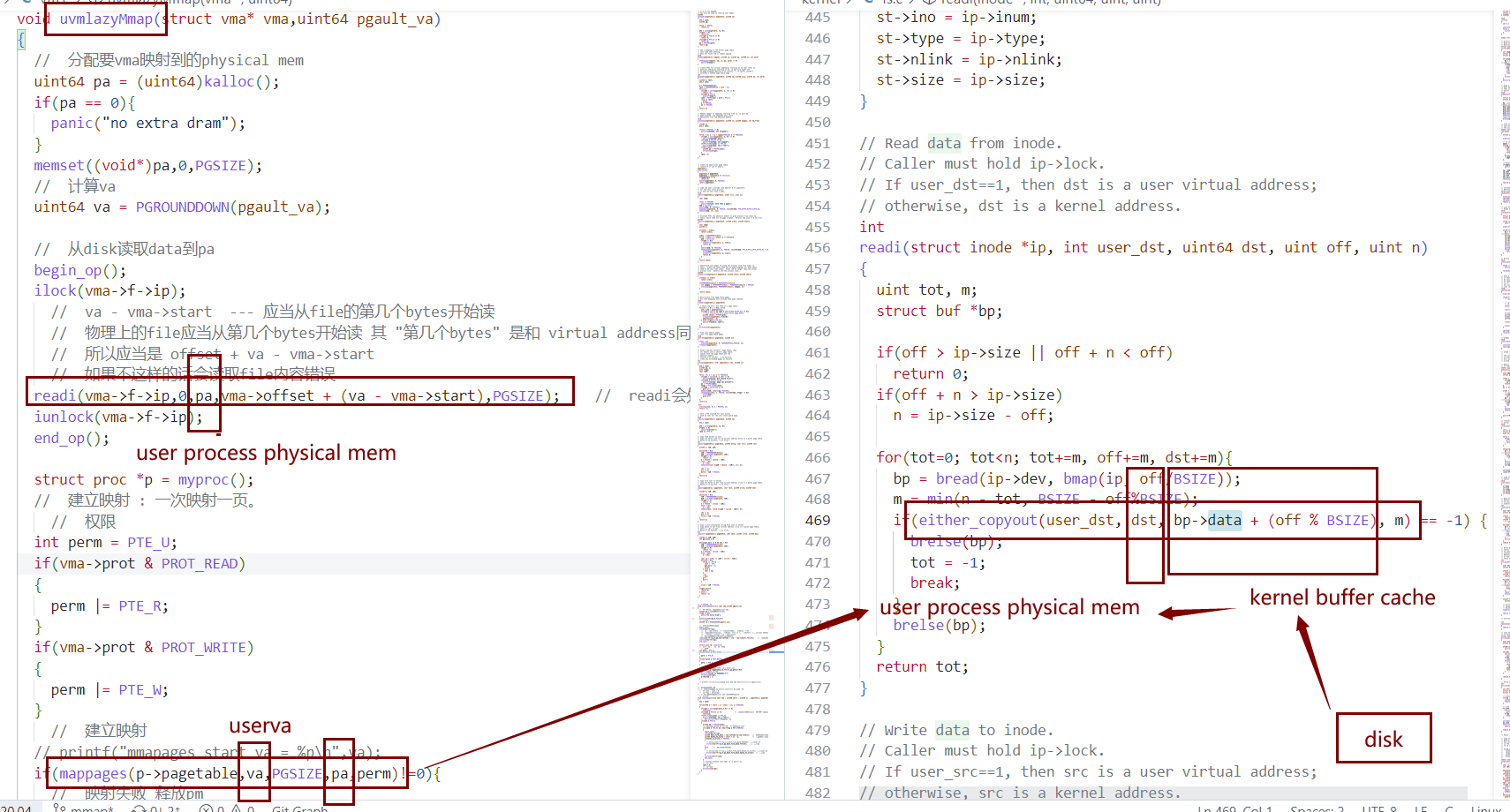
void uvmlazyMmap(struct vma* vma,uint64 pgault_va)
- 一言以蔽之:
- 为user process的pgfault_va所在的page进行lazyallocation(也即为va所在的虚拟页建立相应映射、映射到相应的物理页)。并且将file(由vma可知)的相应字节内容读入physical page。
- 分配要vma映射到的physical page
- 从disk读取data到pa 注意计算file读取的起始字节
- prot权限 – pte权限
- 建立映射 : (va所在virtual page) —> (physical page)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// 每次处理一页
void uvmlazyMmap(struct vma* vma,uint64 pgault_va)
{
// 1. 分配要vma映射到的physical mem
uint64 pa = (uint64)kalloc();
memset((void*)pa,0,PGSIZE);
uint64 va = PGROUNDDOWN(pgault_va); // va对齐
// 2. 从disk读取data到pa 注意计算file读取的起始字节
begin_op();
ilock(vma->f->ip);
// va - vma->start --- 应当从file的第几个bytes开始读
// 物理上的file应当从(offset开始的第几个bytes开始读) 其 "第几个bytes" 是和 (va相比与vm->start的差) 同步的。
// 所以应当是 offset + va - vma->start
// 如果不这样的话会读取错误的file内容
readi(vma->f->ip,0,pa,vma->offset + (va - vma->start),PGSIZE); // readi会处理PGSIZE超出文件剩余大小
iunlock(vma->f->ip);
end_op();
// 3. prot权限 -- pte权限
struct proc *p = myproc();
// 建立映射 : 一次映射一页。
// 权限
int perm = PTE_U;
if(vma->prot & PROT_READ)
perm |= PTE_R;
if(vma->prot & PROT_WRITE)
perm |= PTE_W;
// **4. 建立映射**
// (va所在virtual page) ---> (physical page)
mappages(p->pagetable,va,PGSIZE,pa,perm);
}
- 建立映射 : (va所在virtual page) —> (physical page)
- 一言以蔽之:
pgfaulthandler 之后user process再次使用该va即可.
munmap
int munmap(void *addr, size_t length);
uint64 sys_munmap(void)
- 作用:解除vma管理的va到pa的有效页的映射,并根据需要写回磁盘。(均由vmamunmap实现)
- 检查user传入的addr是否合法
- 计算释放范围对于释放范围以及对齐情况,本lab中没有corner case,
- 对于user传入的地址以及要映射的范围,从maptest中可以看出user传入的起始地址已经对PGSIZE对齐,传入的sz也和PGSIZE对齐。因此不必处理对齐也可过。如果真的处理全部corner case真是得不偿失了。这个实验的重点应该在与理解mmap流程、为什么比read/write file高效。
- 本lab中只需要实现如下三种地址范围的释放.
- [vma->start , x) (x <= vma->end) x不必和PGSIZE对齐
- [x , vma->end) (x >= vma->start) x不必和PGSIZE对齐
- [vma->start , vma->end) the whole region
- 只是禁止dig a hole : addr > vma->start && addr + sz < getVmaEnd(vma) is forbiddened
- 核心:vmamunmap解除映射 vmamunmap(vma,start,sz,myproc()->pagetable);
- 释放vma槽
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28uint64 sys_munmap(void)
{
argaddr(0,&addr); argaddr(1,&sz);
// 1. 检验addr和sz的合法性
// 是否在vma中
if(!validMmap(addr,&vma)) fail
// 检验munmap范围合法性 : not to dig a hole
if(addr > vma->start && addr + sz < getVmaEnd(vma)) fail
// 2. 计算要munmap的范围(核心逻辑如下)
uint64 start = PGROUNDDOWN(addr); // 起始地址向下对齐
sz = sz
// 3. **解除映射**
// 真正的核心实现逻辑在这个函数里
vmamunmap(vma,start,sz,myproc()->pagetable);
// 4. 释放vma槽
vma->left -= sz;
// 如果vma的所有bytes都被释放
if(vma->left == 0)
{
vma->valid = 0;
vma->left = 0;
fileclose(vma->f);
}
}
- 释放vma槽
void vmamunmap(struct vma* vma , uint64 start , uint64 sz , pagetable_t pagetable)
- sys_munmap的核心函数,真正负责解除映射的函数
- 1. 解除vma管理的 从 [start,start+sz) 到 pa 的 有效页的映射,释放physical mem
- 所谓有效页,我的意思是指那些在[start,start+sz)范围之内,已经建立了映射的虚拟页,解除他们的映射。对于无效的地址,也即vma中没有被lazy allocation建立映射的地址,则不必理会。
- pte = walk(pgtbl,va,0);
- *pte = 0;
- kfree(PTE2PA(pte))
- 2. 并在需要时将physical mem中的内容写入disk
- 如果vma管理的映射区域为MAP_SHARED,且该page之前修改过,则将该page(writei)落入磁盘. writei(vma->f->ip,0,pa,dest_file_byte,PGSIZE);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36参考uvmunmap
void vmamunmap(struct vma* vma , uint64 start , uint64 sz , pagetable_t pagetable)
{
for(uint64 a = start ; a < start + sz; a +=PGSIZE)
{
// 如果userva真的建立了到pa的映射
if(*pte & PTE_V)
{
uint64 pa = PTE2PA(*pte);
// 如果map_shared 且 确实写过 则 写入disk file
if((*pte & PTE_D) && (vma->flag & MAP_SHARED))
{
begin_op();
ilock(vma->f->ip);
uint64 dest_file_byte = vma->offset+(a-vma->start); // 要写入的file的起始bytes
uint64 bytes_to_write = start + sz - a; // 总共还有多少bytes要写
if(bytes_to_write >= PGSIZE)
{
// writei(vma->f->ip,1,a,dest_file_byte,PGSIZE); 使用user_va ok
writei(vma->f->ip,0,pa,dest_file_byte,PGSIZE); // 使用pa
}
else // 如果不足1PGSIZEs
{
// writei(vma->f->ip,1,a,dest_file_byte,bytes_to_write); 使用user_va ok
writei(vma->f->ip,0,pa,dest_file_byte,bytes_to_write); // 使用pa
}
iunlock(vma->f->ip);
end_op();
}
// 清空PTE
*pte = 0;
// 释放mem
kfree((void*)pa);
}
}
}
- 如果vma管理的映射区域为MAP_SHARED,且该page之前修改过,则将该page(writei)落入磁盘. writei(vma->f->ip,0,pa,dest_file_byte,PGSIZE);
收尾
- 下面考虑并发。修改fork
- fork
- child拷贝parent的有效vma信息
- 但是child只copy了parent vma区域信息,并没有为child分配物理内存建立映射。
- 也即只是说child和parent使用一样的虚拟地址范围用作vma区域,但是并没有映射到同样的物理内存,child的vma也并没有立刻建立到物理内存的映射。
- child要等到自己陷入pagefault后,再做如上pgfaulthandler处理,分配物理内存、建立映射。
1
2
3
4
5
6
7
8
9
10
11acquire(&np->lock);
for(int i=0;i<NVMA;++i)
{
if(p->vmas[i].valid)
{
np->vmas[i] = p->vmas[i];
filedup(p->vmas[i].f); // 增加struct file 引用计数
}
}
np->state = RUNNABLE;
release(&np->lock);
- exit时自动解除映射
1
2
3
4
5
6
7
8
9
10
11
12
13exit()
{
// 清空vma,关闭文件
for(int i=0;i<NVMA;++i)
{
if(p->vmas[i].valid)
{
vmamunmap(&p->vmas[i],p->vmas[i].start,p->vmas[i].sz,p->pagetable);
fileclose(p->vmas[i].f);
}
memset(&p->vmas[i],0,sizeof(p->vmas[i]));
}
}
拿下
杂记
写mmap的时候的疑问
易知vma管理了映射区域数据,其中就有struct file*。那么在user读写mmap映射到的vma虚拟内存时,kenrel需要去改变file的偏移量吗?
- 我觉得不应该会。因为和read fd write fd不同,read write时,user知道自己是在对文件进行操作;而mmap时user知道他只是在对一块内存中选取地址进行操作,只是其中有文件内容罢了。故不应该改变file偏移量。
关于MAP_SHARED ,在子进程对vma区域进行操作时,可以直接向父进程一样,为子进程的vma区域进行lazy allocation;更好的解决方式是 使得子进程的vma指向(父进程的vma指向的dram),也即父子进程共享同一块dram区域(该块dram中装的是file的data)。
- 我这里实现的是前者,感觉后者有点复杂。父进程munmap时还有看其有几个子进程,是否已经全部munmap,或许还要考虑其他的,目前还没想好.如果两个进程之间没有父子关系,该如何做,又是另一种情况。
当mmap之后,还没munmap之前,如果user关闭了文件会怎么样?也即close(fd)
- On the other hand, closing the file descriptor does not unmap the region.
- 即close(fd),对mapped memory无影响,user仍可以正常都写。
- filedup作用:
- 所谓打开一个文件,其实也就是拿到它的inode,拿到inode才可以读写相应数据。而我们又将inode*存储在struct file里,因此打开文件就是拿到相应的struct file。
- filedup就是增加file的引用计数,防止其被从ftable中踢掉。当struct file的引用计数降为0的时候,则会被其他inode的struct file替换。而user是通过自己的fd-file表引用struct file的,(其表中存储的是file*)那么user就会通过fd引用到错误的struct file。
关于效率(拷贝次数)
- mmap 加载file到physical mem,然后user映射读取 和 user自己读取file有什么区别?为什么高效?
XV6中mmap
- 结论:在xv6中,两者效率似乎并无高低之分,因为拷贝的次数都是相同的。
- 都是需要2次拷贝
- 从 disk 读进 kernel buffer cache,
- 然后从kernel buffer cache 拷贝到 user va 映射到的 physical mem
- 都是需要2次拷贝
首先,对于mmap
- user使用mmap读取文件数据流程:
- mmap : return mapped memory address
- read / write mapped memory
- munmap : 解除映射。vma管理的虚拟地址范围 全部解除映射后,mapped memory 就不可再被引用。
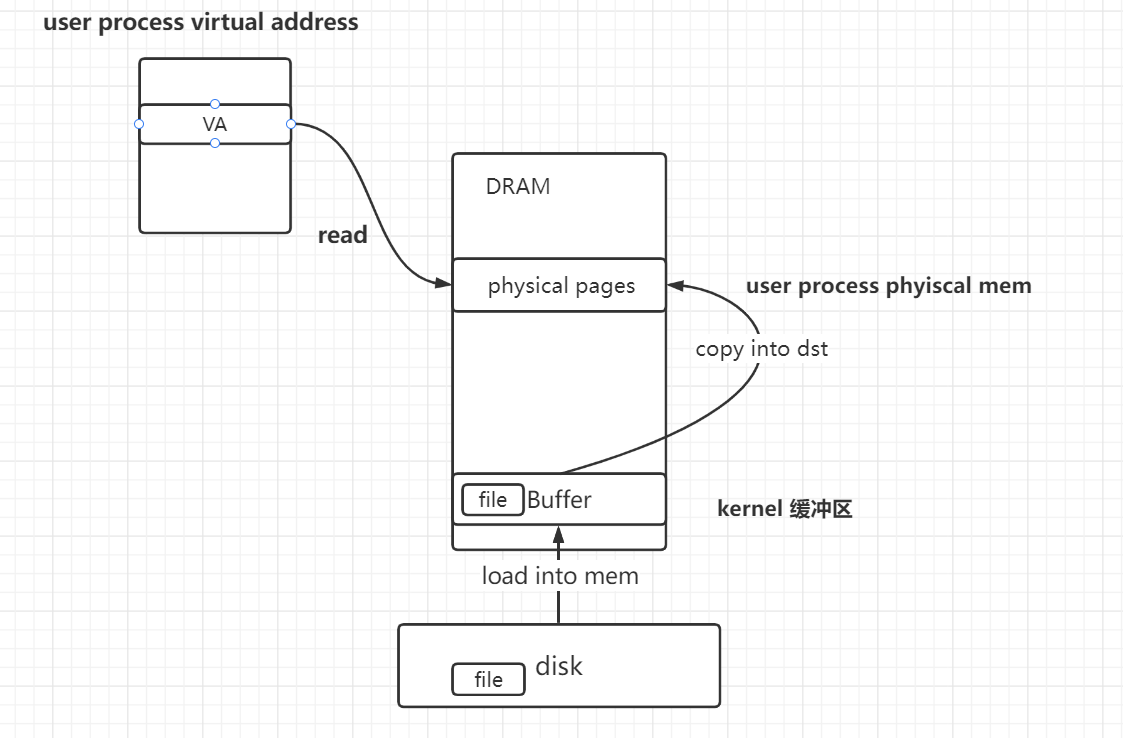
- 映射关系如图
- data拷贝逻辑如图
- disk -> kernel buffer cache -> user process
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// mmap
// open for get fd
fd = open(f, O_RDWR)
// mmap
p = mmap(0, PGSIZE*3, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// it's ok to close
close(fd);
// read / write mapped memory
// check that the mapping still works after close(fd). (read)
_v1(p);
// write the mapped memory.
for (i = 0; i < PGSIZE*2; i++)
p[i] = 'Z';
// munmap mapped memory
// unmap just the first two of three pages of mapped memory.
munmap(p, PGSIZE*2);
// unmap the rest of the mapped memory.
munmap(p+PGSIZE*2, PGSIZE);
- user使用mmap读取文件数据流程:
然后,对于read/write,拷贝逻辑并无不同。
- disk -> kernel buffer cache -> user process phyiscal mem
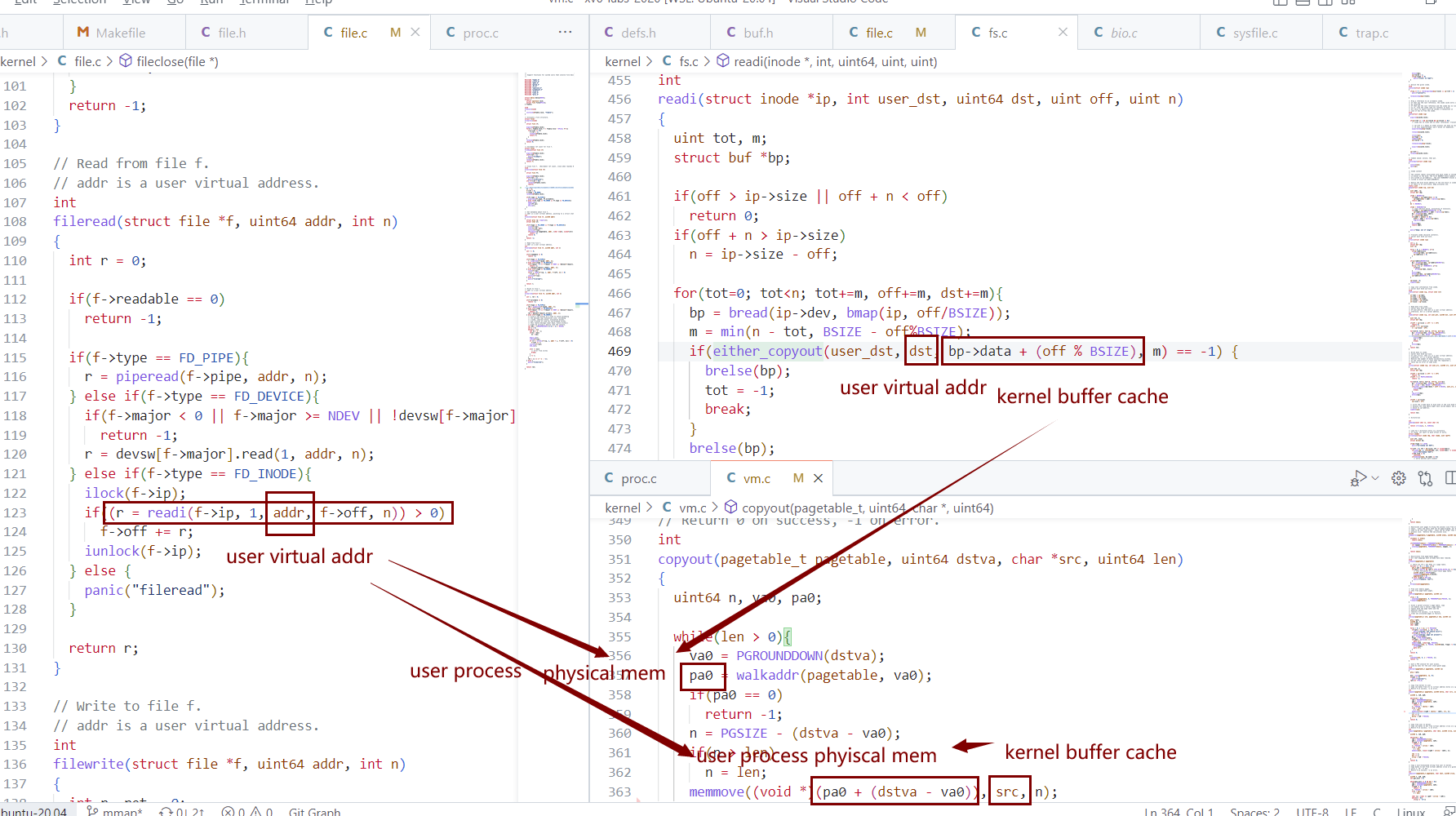
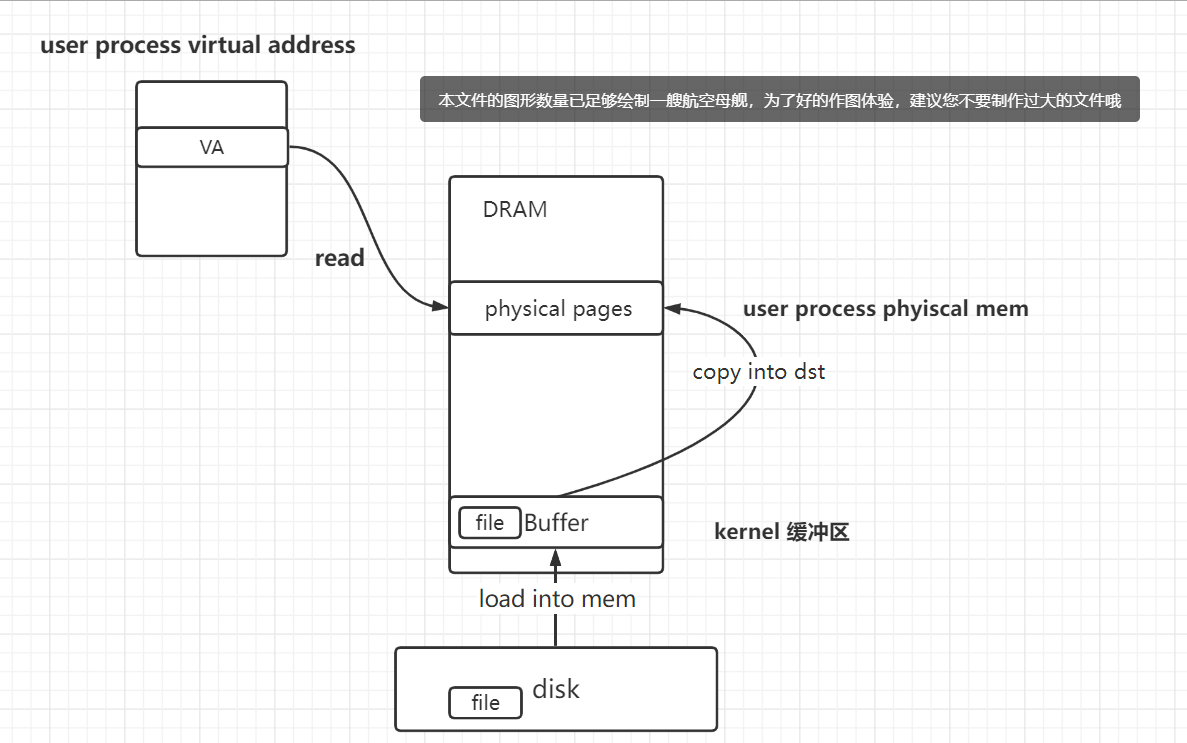
1
2
3
4
5fd = open(path, 0);
struct dirent de;
read(fd, &de, sizeof(de));
读写 de.member
write(fd,&de,sizeof(de))
- disk -> kernel buffer cache -> user process phyiscal mem
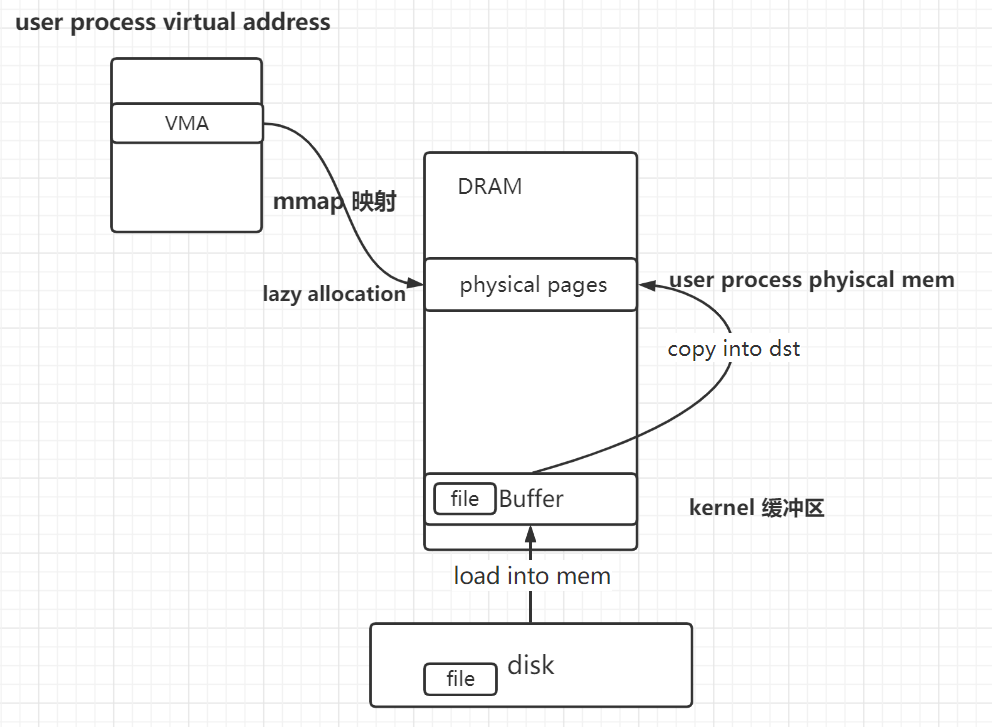
Linux
和xv6不同,拷贝次数少一次。没有从kernel buffer到user physical mem的拷贝。
至于所说的linux中的mmap比read高效,其中一点原因应当是指就拷贝次数而言,mmap比read少一次
- mmap直接将user va映射到了kernel buffer cache。而非新alloc一个physical page。这个实现应该是xv6得option challenge。
- Your solution probably allocates a new physical page for each page read from the mmap-ed file, even though the data is also in kernel memory in the buffer cache. Modify your implementation to use that physical memory, instead of allocating a new page. This requires that file blocks be the same size as pages (set BSIZE to 4096). You will need to pin mmap-ed blocks into the buffer cache. You will need worry about reference counts.
没有做optional challenge,不过实现完之后应当是这样。
- 当user第一次使用vma管理的虚拟地址时,file data 从disk —> 读到 kernel buffer。然后将user pagetable上建立从user va 到 kernel buffer的映射
- 可以看到,并没有未该vma新alloc一个physical page去映射,而是直接将user的va映射到buffer cache上,减少了一次从kernel buffer cache到user phyical mem的拷贝,效率比read更高。(read还要拷贝一次)
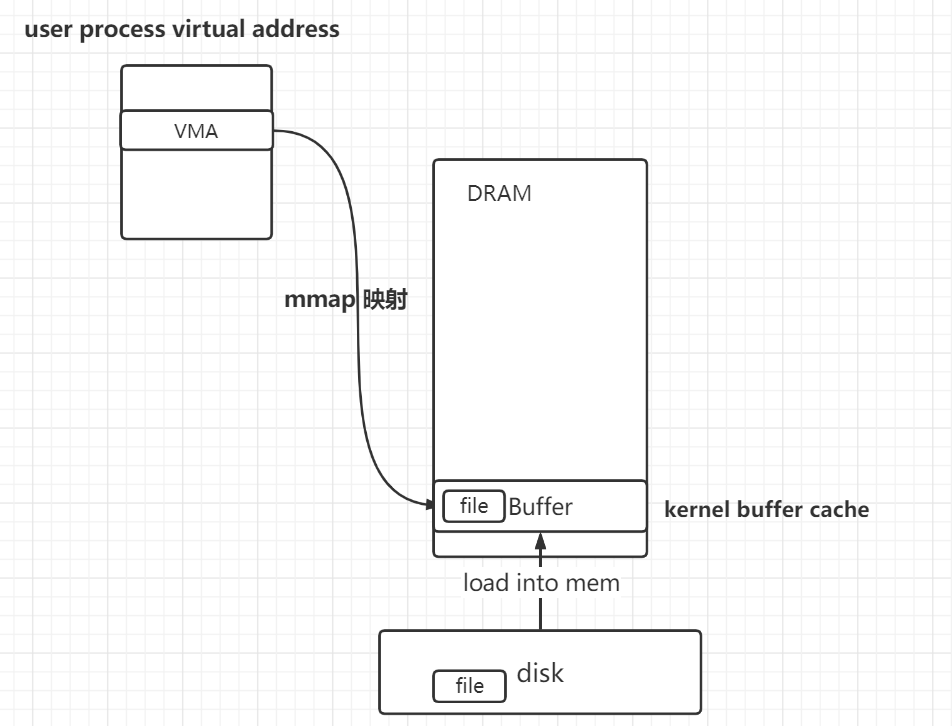
lazy allocation :
- 虽然没有为user va新alloc一块physical page,不过也可以称得上是lazy allocation
- 因为lazy allocation的思想就是要推迟va建立映射的时间,尽可能的推迟为va分配映射到的physical page。而这里确实是将va的映射推迟到了其被使用时才建立,只不过是没新alloc罢了,新建立的映射是从va到buffer cache的映射。
Optional Challenge
- 感觉把下面的都实现了的话,才能算是一个现代os中的mmap
If two processes have the same file mmap-ed (as in fork_test), share their physical pages. You will need reference counts on physical pages.
Your solution probably allocates a new physical page for each page read from the mmap-ed file, even though the data is also in kernel memory in the buffer cache. Modify your implementation to use that physical memory, instead of allocating a new page. This requires that file blocks be the same size as pages (set BSIZE to 4096). You will need to pin mmap-ed blocks into the buffer cache. You will need worry about reference counts.
Remove redundancy between your implementation for lazy allocation and your implementation of mmap-ed files. (Hint: create a VMA for the lazy allocation area.)
Modify exec to use a VMA for different sections of the binary so that you get on-demand-paged executables. This will make starting programs faster, because exec will not have to read any data from the file system.
Implement page-out and page-in: have the kernel move some parts of processes to disk when physical memory is low. Then, page in the paged-out memory when the process references it.
- 感觉把下面的都实现了的话,才能算是一个现代os中的mmap
小结 mmap优势
mmap优势
优势1:在于效率高,高于普通的read file
效率高原因如下
1. 减少拷贝次数,如上讨论。
- mmap 在读取va对应保存的内容时,内核只需要一次拷贝数据。
- optional Challenge中实现
- 以下为第一次使用va时触发的pgfault ,陷入内核,进入handler所做的工作
- disk —-> kernel buffer cache
- 建立va 到 kernel buffer cache的映射
- 然后回到user态,user再度读写va即可。
- 而read 读取va对应保存的内容时,内核需要拷贝两次数据。
- read时也需要进入一次内核。
- disk —> kernel buffer cache 一次拷贝
- kernel buffer cache —> user process physical mem 两次拷贝
- read时也需要进入一次内核。
- mmap 在读取va对应保存的内容时,内核只需要一次拷贝数据。
2. 减少陷入内核次数,减少上下文切换开销
- 通过mmap映射文件 : 对于一个page中的va,第一次使用该va,会触发pgfault,陷入内核,pgfault handler会进行lazy alloc处理(如1和上节linux所述)。而后,再次使用该page中的va,则不会触发pgfault,也就不会进入内核,直接在user态读写va即可。因为整个page都已经建立了映射。
- 而read,每次read都需要陷入内核。
- 如下,通过mmap减少大量陷入内核的次数.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// read: 每次read都要进入一次内核
char de;
while(read(fd, &de, sizeof(de)) == sizeof(de)){
read/write de
}
// mmap : 每个page进入一次内核即可(使用到哪个page就为哪个page进入内核建立映射)
char *p = mmap(0, PGSIZE, PROT_READ|PROT_WRITE, MAP_PRIVATE, fd, 0);
for (int i = 0; i < PGSIZE; i++)
{
if (p[i] != 'A') {
printf("mismatch at %d, wanted 'A', got 0x%x\n", i, p[i]);
err("v1 mismatch (1)");
}
}
}
3. 共享物理内存
- 当多个进程将同一页面映射到内存时,数据可以在这些进程之间共享。
- 对于 只读 PROT_READ 的PAGE可以完全共享。
- 对于PROT_WRITE && MAP_PRIVATE 的PAGE,可以通过COW节省开销。
- 当多个进程将同一页面映射到内存时,数据可以在这些进程之间共享。
优势2 : 更加方便user读写文件 :
- 在user的va中划出一片区域,将文件内容映射其中。让user可以像操作内存数据一样,操作文件数据。
- 也即**使得user读写va就是在读写file的内容(在物理内存中读写而非磁盘上)**。
- 也因此,对于随机访问,不用频繁 lseek。
- 优势3:lazy allocation
- mmap的另一个特点:lazy allocation
- 某种程度上说也提高了效率
- user使用mmap之后,kernel不会立刻将file全部内容读取physical mem,然后为user va建立映射。而是等待usr使用到相应的va,才会触发pagefault,进入kenerl,handler处理,读取内容,建立映射。
- 并且感觉也为user提供了方便
- user调用mmap之后,不必管file的内容如何加载到mem,也不用管如何建立映射,也不用管数据如何落回磁盘。user只需要简单地认为,这块内存里就存有file的数据即可,user只需要负责对其进行读写罢了,以及最后munmap,并且知道可以根据我们的需要落入磁盘。其余的都不必管。
- 解释:mmap所谓的 “映射文件到用户进程” :
- 读取文件内容,建立user va到dram的映射
- 所谓的映射:实际上就是将disk上file的内容读到一块physical mem,然后将user的pagetabl上,建立va到physical mem的映射
- 之所以叫映射,应当是和mmap的实现无关,只是因为从user的角度看起来,很像是将file的内容映射到user的一段va中
- mmap之后,user读写相应va就是在读写file的内容(在物理内存中读写而非磁盘上)