本节的重点
- 一在于锁机制的优化
- 二在于物理内存如何分配
- 三在于buffer cache如何分配。
- 关于锁机制的优化,我基本上是参考博客
- 至于buffer cache如何分配,在操作系统-xv6-文件系统 buffercache中也已经讲过。
- 下面重点介绍 物理内存是如何分配的,也即user是如何通过malloc申请到物理内存的。
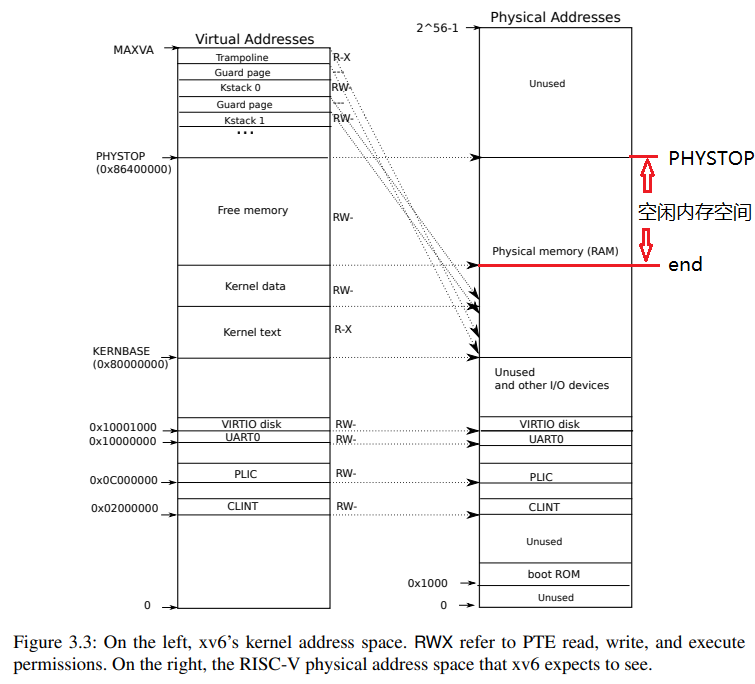
物理内存分配流程
- kernel是如何组织free physical page的。
- xv6 : freelist
- kernel为user提供的sycall接口
- sbrk->sys_sbrk()
- user层是如何封装sbrk的。
- malloc and free (维护了user态的cache list)
- malloc and free (维护了user态的cache list)
- kernel是如何组织free physical page的。
xv6 物理内存分配流程
结构
先看一下xv6中,physical memory是如何被组织起来的.
- kernel以freelist的形式将free physical memory 组织起来
- kernel如何组织free physical page是一个值得优化的策略。本lab实现的就是优化该策略
1
2
3
4
5
6
7
8struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;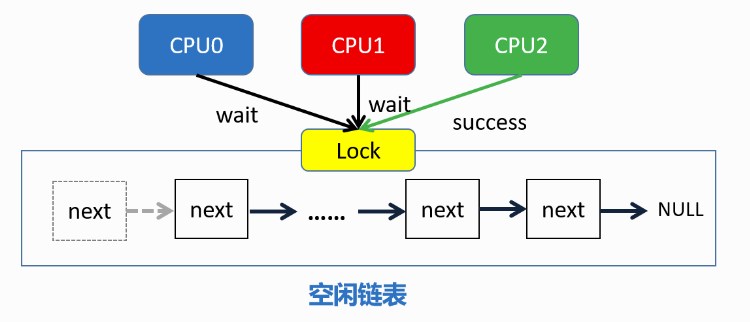
- kernel如何组织free physical page是一个值得优化的策略。本lab实现的就是优化该策略
- 初始化
- entry.S -> start -> main -> kinit -> freerange -> kfree
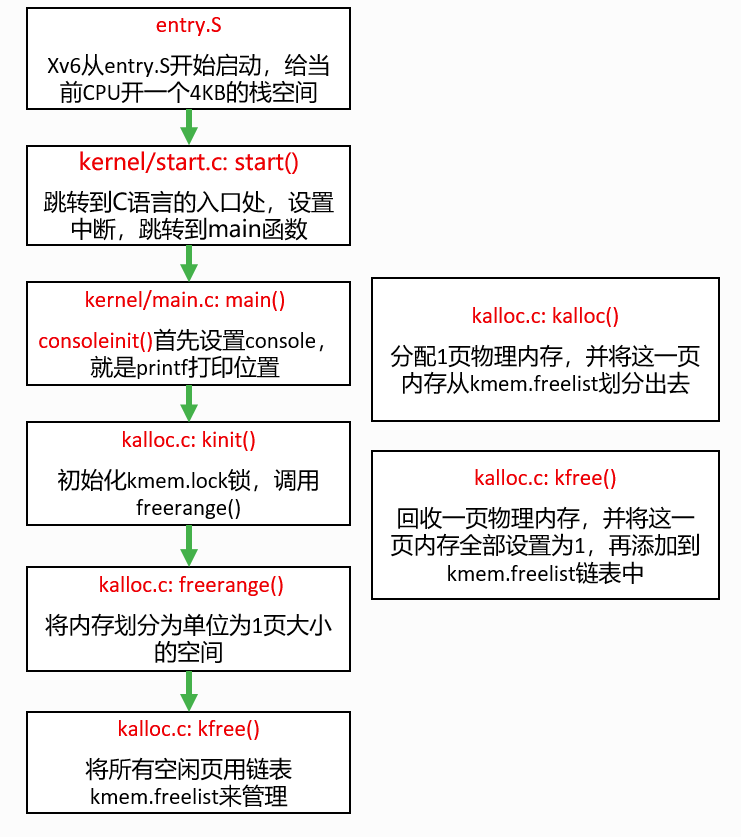
- entry.S -> start -> main -> kinit -> freerange -> kfree
接口
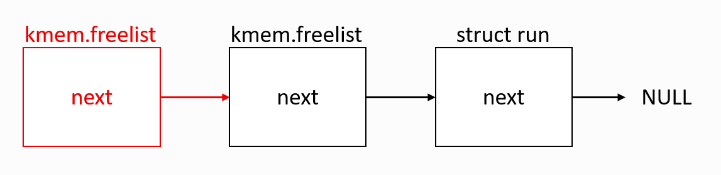
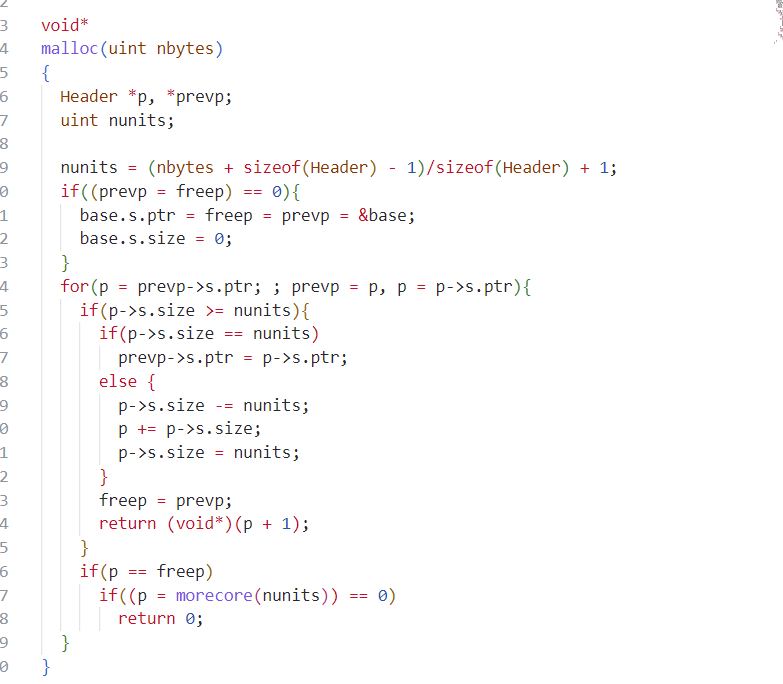
kalloc: 从freelist头部取下一个page 返回给调用者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
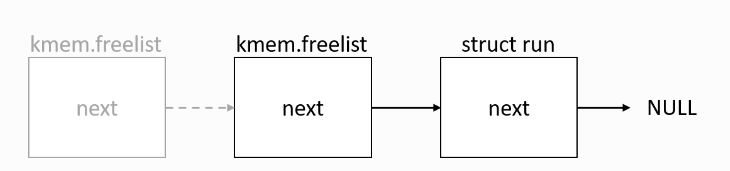
}kfree: 将一个无用的page 头插法插入freelist
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
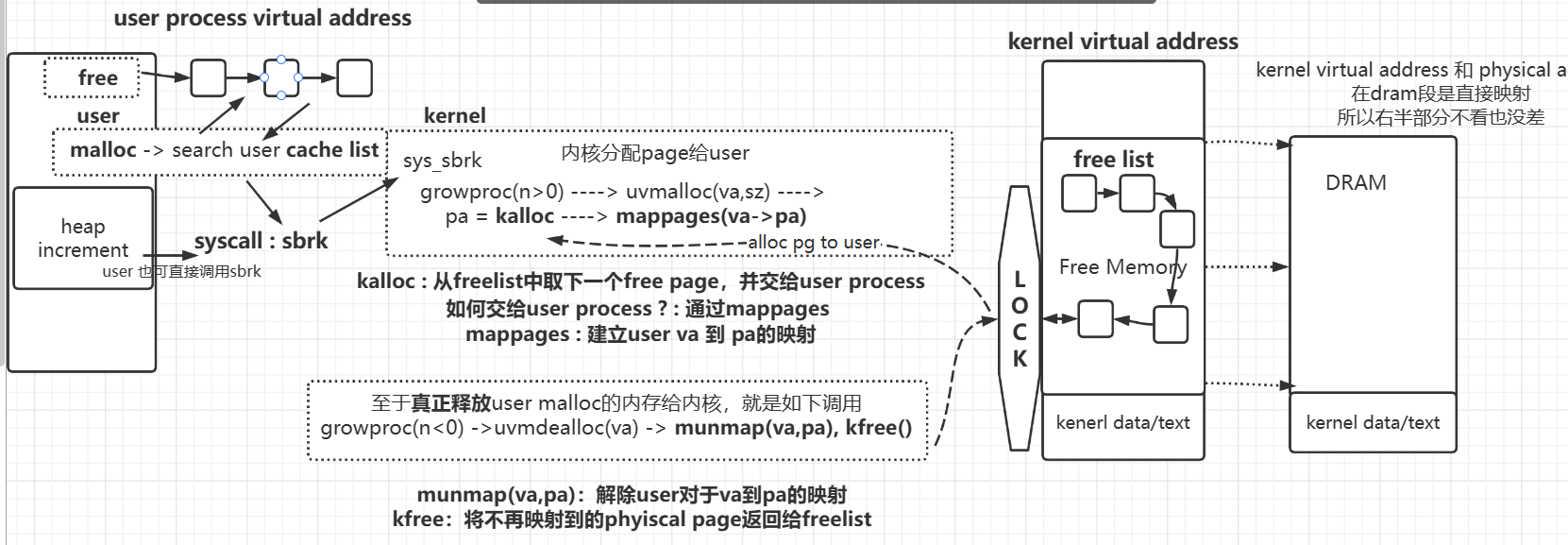
请求流程
malloc 和 free 共同维护了user态的cache list
如果user直接调用syscall sbrk的话,则并没有通过cache list
物理内存分配相关API层次如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15user
/////////////////////// user态
malloc / free
**user cache list**
///////////////////////
syscall : sbrk
/////////////////////// trap into kernel态
sys_sbrk
growproc
uvmalloc deamalloc
kalloc kfree
mappage unmap
**free physical pages in freelist**
///////////////////////
DRAM整体图
malloc (sbrk(n>0))
user向kernel(也可能会是从user态的cache list中取出page)申请内存(malloc –> sbrk (n>0))
- 核心思路:
- 0. 先检查user态中的cache list中是否有足够的cache pages,如果有从cache list中取出内存则返回;如果没有则进入1:通过syscall sbrk向kernel请求free physical pages
- 1. sbrk : kernel返回一个free physical page(即空闲物理页)给user。
- 2. 在user pgtbl建立user va 到pa的映射。
- 核心思路:
kernel如何分配free physical page给user?这就涉及到可以优化的策略了。本lab的内容就是优化该策略。
- xv6原先策略:所有free physical page都位于一个freelist上,所有cpu核使用同一个freelist。每个cpu核上的kernel可能会同时向freelist发出kalloc/kfree请求。因此需要采用一把大锁保护整个freelist。降低效率。
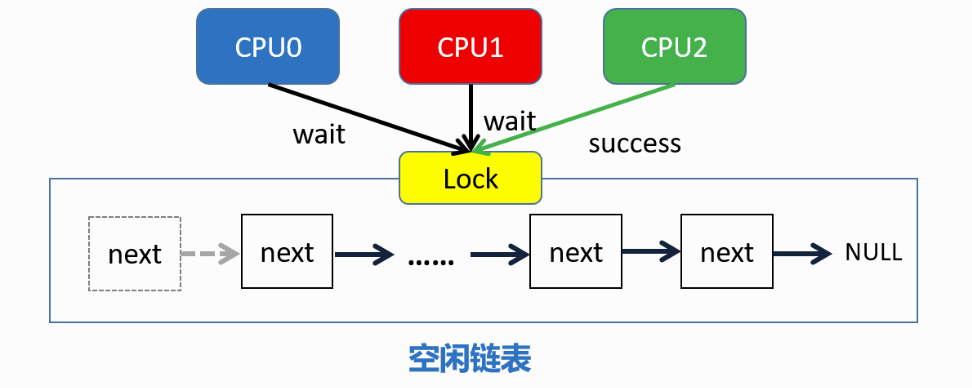
- lab优化后策略:每个cpu核心拥有一个独立的freelist,physical page散布在这些freelist上,每个kernel要分配物理内存时,只会操作属于自己的freelist,这样可以减少锁竞争情况的发生。
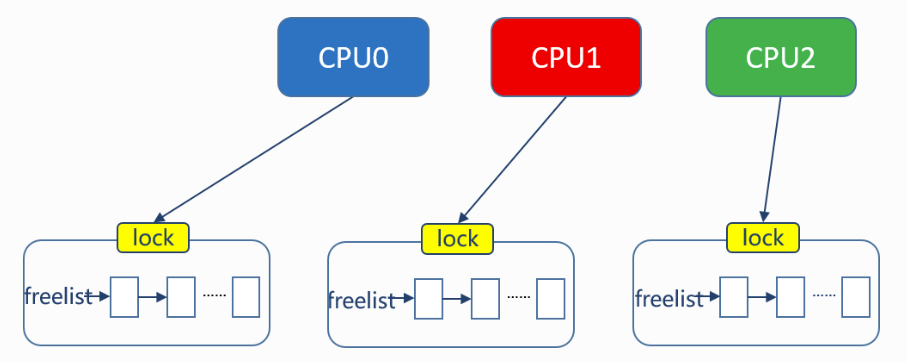
- xv6原先策略:所有free physical page都位于一个freelist上,所有cpu核使用同一个freelist。每个cpu核上的kernel可能会同时向freelist发出kalloc/kfree请求。因此需要采用一把大锁保护整个freelist。降低效率。
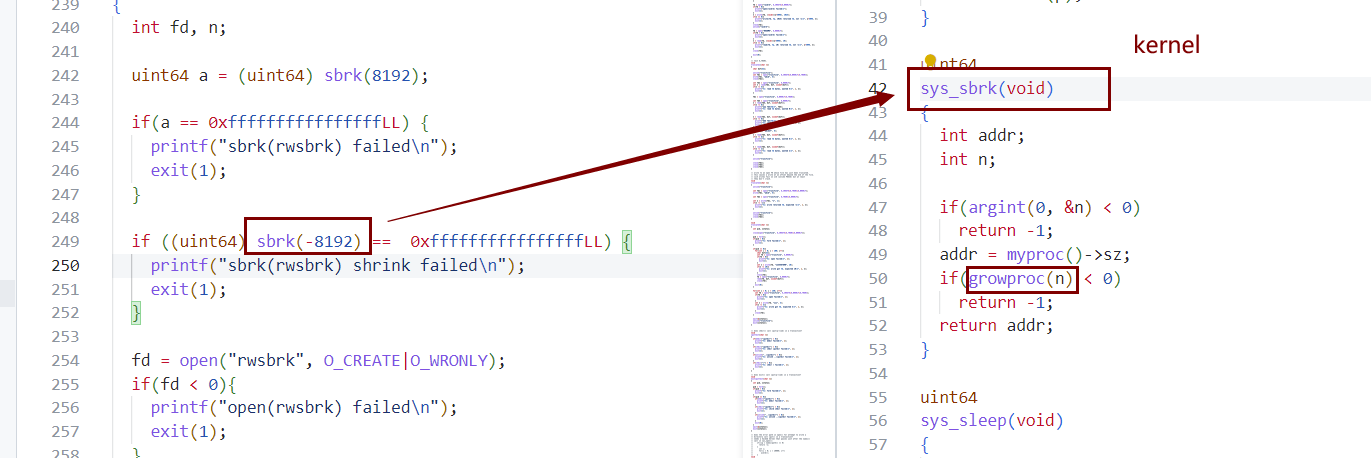
xv6 API流程:user -> malloc -> sbrk -> sys_sbrk -> growproc(n>0) —-> uvmalloc(va,sz) —-> pa = kalloc —-> mappages(va->pa)
- kalloc : kernel从freelist中取下一个free page,并交给user process
- 如何交给user process ? : 通过mappages , 建立user va 到 pa的映射
sbrk (n<0)
- user释放kernel分配的内存,真正的还给kernel(sbrk(n) < 0)
- 核心思路
- 1. userpgtbl 解除 va 到pa的映射
- 2. kernel将page重新挂在freelist上。(重新作为freepage维护起来)
- xv6 API流程:user -> sbrk(n<0) -> sys_sbrk -> growproc(n<0) —-> uvmdealloc(va) —> munmap(va,pa), kfree()
- munmap : 解除user对于va到pa的映射
- kfree:将不再映射到的phyiscal page重新挂到freelist
- 核心思路
free
- user释放内存到用户态(通过 free)
- user态维护了一个cache list,里面存储的是user之前通过malloc->sbrk从kernel申请来的、没被使用的pages(page在这个cachelist中是以virtual address的形式)。
- 也即,是物理内存分配机制在用户态维护的缓存。
- 这也应当是一个可以思考优化的策略
- user 调用free(page)。会将该page加入user态的cache list,该page还是由user process占据,而非真正的释放、返回给kernel。
- user态维护了一个cache list,里面存储的是user之前通过malloc->sbrk从kernel申请来的、没被使用的pages(page在这个cachelist中是以virtual address的形式)。
小结
物理内存的分配机制感觉也就如下几个关键点
- kernel是如何组织free physical page的。(上述xv6是以freelist。优化方法为每个cpu核一个freelist。)因为这会影响到kernel是如何将free physical page分配给user,kernel又会如何回收free physical page。
- kernel为user提供的:直接获取/直接释放(即不涉及用户态缓存) physical page的系统调用接口是什么:sbrk->sys_sbrk()
- user层是如何封装sbrk的。一般都是将sbrk封装成malloc和free供给user使用。为什么封装?:一大作用就是缓存:为user process 在 用户态 维护了 一个 从kernel中申请来的内存的 缓存。缓存中存的是user暂时用不到的free pages。
- xv6中是维护了一个cache list:
- malloc时先到cache list中寻找有无足够大的内存,没有则通过sbrk向kernel请求
- free时则是将不用的内存放入cache list中
TODO
日后有时间应该会做个简单的malloc
然后研究下slab内存分配器和伙伴系统
所谓内存分配器和伙伴系统:内核做出的设计而非user
感受:把做的是哪个层次的事情给搞明白了,剩下的对于具体的设计方法,就是数据结构层面的事情了,就好办很多了。
学校赶人收拾行李了,回家再研究.
伯克利 malloc lab
TODO
malloc : 链表(显/隐) , 红黑树…
slab内存分配器 & 伙伴系统
TODO