- lab1 : 实现一个接收端的重排器
- lab2实现的 TCP receiver 的重要功能:处理乱序到达的数据包 ,该功能即lab1 所谓的 重排器 reassembler
- 就是让我们实现一个tcp的滑动窗口协议的接收端。
- TCP协议中的滑动窗口协议是SR协议和GBN协议的结合
- 发送窗口 > 1
- ack代表 : 接收方接收到的顺序到来的最后一个字节 + 1
- 像GBN协议的部分 :
- 发送窗口内只有一个定时器(窗口内最老的分组的定时器)
- 发送ack累计确认
- 像SR协议的部分 :
- 可以乱序接收
- sender重传超时分组(最老的),receiver给sender发送新的ackno , sender可以发送新的数据. 是否重传发送窗口中的其他分组,取决于ackno的大小. 若大于send window中的所有segment , 则清空send window,不必重传所有分组. 若小于send window中的某些segment , 则会重传这某些分组.
- 我目前认为网上有些人说的 重传 所有分组 是不对的。又不是GBN协议. receve window是 > 0的
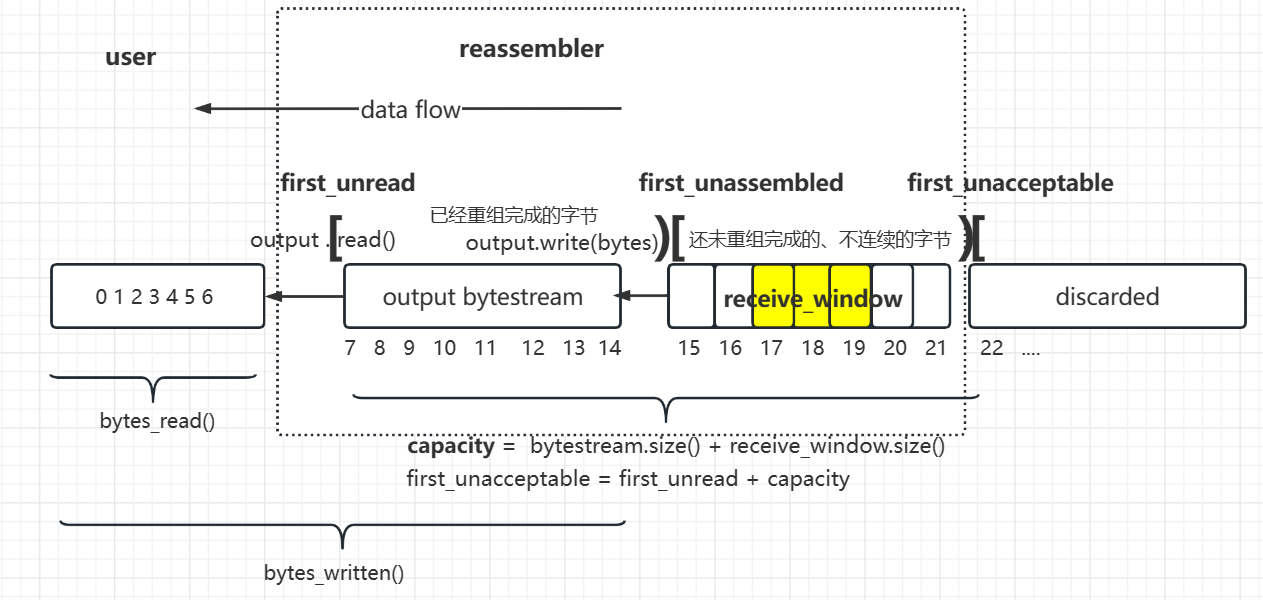
receiving_window 接收窗口 [the first unassembled , the first unaccepted)
capacity = bytestream.buffer_size() + receiving_window.size()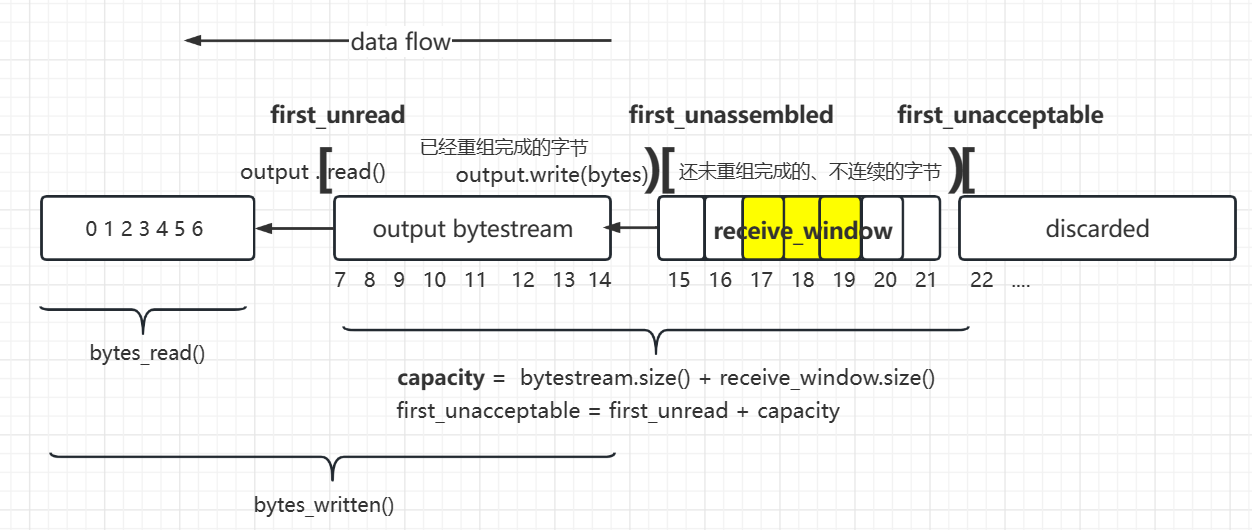
从某种意义上来说,receive_window就是就是从bytestream中划出了一部分用作乱序缓存
bytestream(顺序字节) + receive_window(乱序字节) = capacity
背景
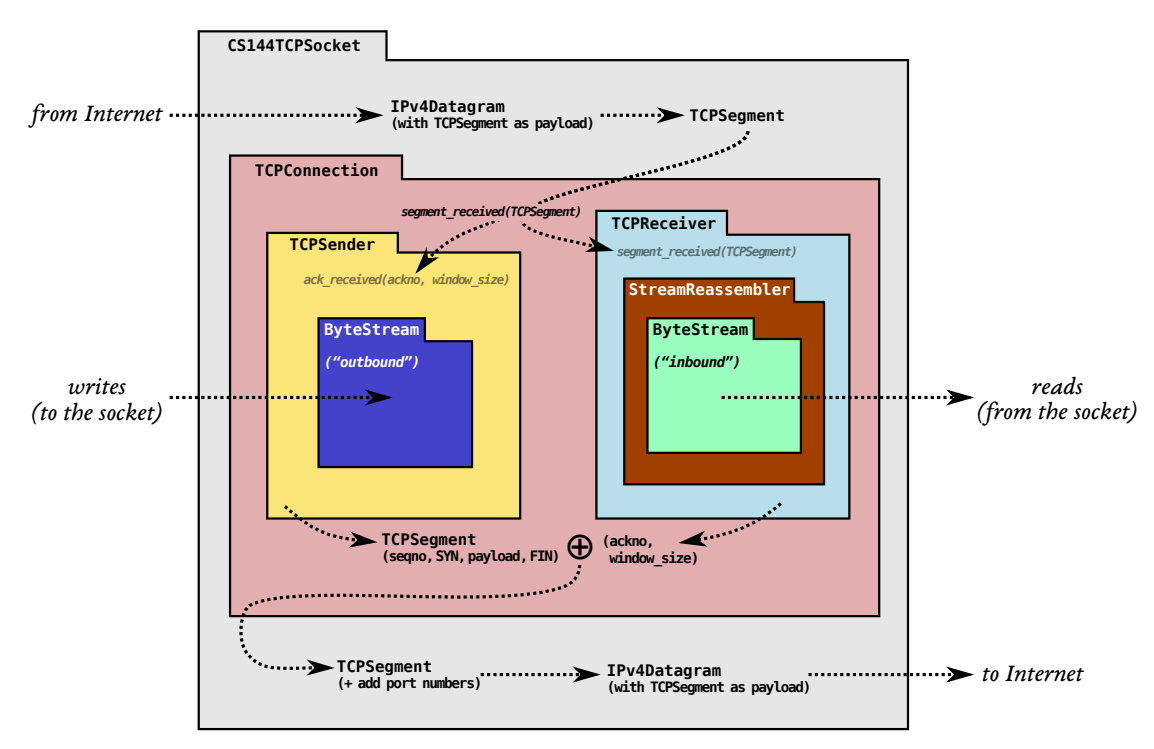
- 上图:我们将实现的TCP的 每一个模块的安排 以及 数据的流向。
- TCP的工作是在不可靠的datagram网络之上 传输两个方向的ByteStream,因此写入socket的字节(outbound)会在连接的对端作为可读字节(inbound)出现,反之亦然。
- Lab0实现了图中的ByteStream。
- Lab1实现的是流重组器(StreamReassembler)
- Lab2是TCP接收器(TCPReceiver)
- Lab3是TCP发送器(TCPSender)
- Lab4是TCP连接(TCPConnection) 将他们组合在一起
- 上图:我们将实现的TCP的 每一个模块的安排 以及 数据的流向。
我为什么要实现TCP ?

- 在不可靠的服务之上 提高服务或者抽象 可以解释网络中的许多有趣的问题。
- 在过去四十年中,调查者和实践者已经解决了如何通过互联网传输各种各样的信息 如邮件、超链接、搜索引擎、声音、视频、写作文件共享、数字货币。
- TCP自己的角色是:使用不可靠的数据报 提供可靠的字节流。就是上述所说的在不可靠服务之上提供服务的经典案例。一个合理的观点是:TCP是地球上使用的最广泛的非凡的计算机程序。
实验会要求你以模块化的方式构造一种TCP的实现。在接下来的四个实验中,你将会实现
- 通过网络传输lab0中实现的bytestream:
- outbound bytestream,用于本地的数据写入socket然后发送给TCP连接的对端;
- inbound bytestream,用于接收来自对端的数据,这些数据会被本地的app读取。
- lab1中,我们将实现一个流重组器(stream reassembler)
- 该模块用于将字节流中的片段(被称为substrings / segments)重组为顺序的字节流。
- lab2中 我们将实现TCPReceiver :
- 负责处理inbound bytestream。
- 这包括了思考TCP是如何将字节流中的每个字节的位置标记为序列号;TCPReceiver负责告知发送方inbound bytestrean有能力组装多少字节;并且发送方被允许再发送多少bytes.(这就是所谓的流量控制)
- lab3中 我们将实现TCPSender :
- 负责处理outbound bytestream.
- TCPSender需要如何反应 当它认为一个传输了的segment在路上丢失了;它在什么时候需要重传丢失的segment
- lab4中 我们将组合之前的lab,来创建构建一个TCP实现:一个TCP包含了TCPSender和TCPReceiver的连接。你将使用该TCP实现去和全世界的server通信。
- 通过网络传输lab0中实现的bytestream:
要求
- 背景:
- 在lab1和lab2,你将要实现TCP receiver。这个模块接收datagrams,并且将他们转化成将要被user从socket中读取的可靠字节流(就像lab0中 从webserver读取字节流的webget一样)
- TCP Sender会将字节流切割成short segment(每片不大于1460bytes的substring),因此每个short segment都可以放入一个datagram中。
- 但是网络可能会打乱datagram的顺序,或者丢弃他们,或者重复投递他们。
- TCP receiver需要 重新组合这些segments,将其重组进顺序连续的字节流(就像发送方刚开始发送的字节流一样)
- 在lab1和lab2,你将要实现TCP receiver。这个模块接收datagrams,并且将他们转化成将要被user从socket中读取的可靠字节流(就像lab0中 从webserver读取字节流的webget一样)
约定:segment/substring/bytes not reassembled
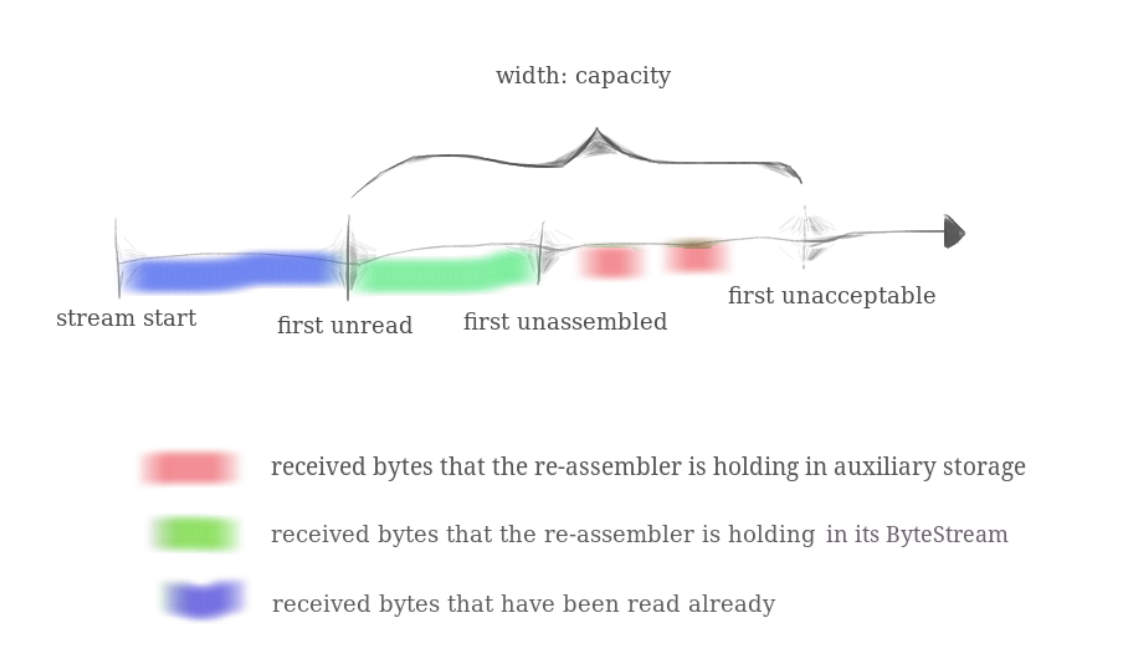
还没重组的字节:我们将 还没有 形成 顺序的 连续的 segment/byte,称为乱序的byte,也即需要reassemble重组的byte,这些byte被缓存在receving_window中,由于和bytestream中的byte还没连续起来,故不加入bytestream,等待所需字节的到来,也即等待reassemble。
重组完成的字节:已经形成了顺序的、连续的byte,这些byte已经从receving_window被压入bytestream中.
老数据:已经从bytestream中读走的字节 以及 已经压入到bytestream中的字节
新数据:下标范围落在receiving_window中的字节。这些字节可能之前已经被缓存在receive_window中。
StreamReassembler要求如下
本实验实现目标:StreamReassembler 流重组器。
- 所谓的流重组器StreamReassembler,也就是我们常说的 滑动窗口协议中 接收窗口大小大于1时(Selective Repeat协议) 的 接收端。只不过这里接收窗口的大小不是固定的,是和bytestream的大小加在一起=capacity)
- StreamReassembler接收segment(substring)
- segment结构:string data , index(data[0])
- 整个字节流的起始byte下标为0.
- output bytestream : StreamReassembler 的输出接口。
- 其中装载的是已经顺序的连续的字节。
- output.write(msg) : 一旦StreamReassembler确认流中顺序的下一个字节,就将其写入ByteStream.
- output.read() : user可以使用该output bytestream,并在任何时候从其中读取字节。
接口
- void push_segment(const string &data, const uint64_t index, const bool eof);
- data : the segment
- index : data[0]在整个字节流中的下标
- eof : 该data segment的最后一个字节将成为整个流的最后一个字节
- 可以看出,eof本身并不占据字节流中的位置,不消耗下标。(也即stream_idx不记录eof)
- 接收segment data , 将相应的部分落入 recving_window , 并将连续的bytes写入output bytestream。超出capactiy部分的字节将自动被舍弃。
- size_t unassembled_bytes() const;
- 被缓存 但还没被重组的 segment的字节数量。(segment stored but not yet reassembled)
- bool empty() const
- 我认为是 outputstream和recving_window均为empty(Is the internal state empty (other than the output stream)?)
- void push_segment(const string &data, const uint64_t index, const bool eof);
关于capacity
- 一言以蔽之: capacity = bytestream.buffer_size() + receving_window.size()
- 也即,capacity = reassembled bytes (in bytestream)+ unreassembled bytes (in segment)
- 也可以看作是 从 bytestream的capacity中,划走一部分作为接收窗口(即缓存)
- capacity作用:流量控制的一部分,防止己方接受过多bytes
- push_substring()会忽略任何超出capacity的字节,这防止了StreamReassembler没有限制的使用内存,不管TCP Sender打算做什么。
整个字节流图。整个字节流从左向右增长,从右向左流动。
实现
class StreamReassembler
由上述分析可知,我们所要实现的,就是一个接受窗口大小>1的滑动窗口协议接收端
图
一些关系
- capacity = bytestream.size() + receving_window.size()
- 从某种意义上来说
- receive_window就是就是从bytestream中划出了一部分用作乱序缓存
- bytestream(顺序字节) + receive_window(乱序字节) = capacity
- bytestream中 存储的是 StreamReassembler已经重组完成的顺序连续字节。上层user可通过调用bytestream.read()将其读走
- receiving_window : [first_unassembled,first_unacceptable)
- 作用:缓存乱序字节
- receiving_window 中存储的是 没能和bytestream形成连续的字节,当其能和bytestream连起来时,就将连起来的字节压入bytestream。
- 大小变化,受capacity限制。
- 实现:unordered_map<size_t , char> _receving_window;
- 作用:缓存乱序字节
成员
1
2
3
4
5
6
7
8
9
10
11
12
13private:
ByteStream _output; //!< The reassembled in-order byte stream 有序的bytes
size_t _capacity; //!< The maximum number of bytes
// receiving_window
unordered_map<size_t , char> _receving_window; // 乱序到达的,还没加入bytestream的bytes
size_t _first_unread; // 第一个没被读的byte的索引。其大小等于上层已经从bytestream读走了多少bytess
size_t _first_unassembled; // 第一个没加入bytestream的byte的索引(第一个乱序的byte索引)
size_t first_unacceptable() const {return _first_unread + _capacity;} // the first_unacceptable
// eof
size_t _eof_idx;
bool _eof;push_segment实现
- void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof)
- 主要分为两步
- 1. 将segment data的相应部分,正确的缓存在receiving_window中(1.)
- 这也就是 所谓的 StreamReassembler 所做的重组工作,即将字节正确的排列在receiving_window中,当形成连续的顺序字节时,就输出出去(即送入bytestream中)
- 对于segment data,可分为如下情况讨论。
- segment data全部是老数据,那么不必缓存在receiving_window中
- segment data全部是新数据,那么则将其全部缓存在receiving_window中(当然超出capacity的要截断)
- 这里我的实现可能会造成重复缓存的问题,可以优化,比如用一个数组记录下接收窗口中连续字节的起始位置,不过目前还没做优化,只是保证正确性,反正没超0.5s。
- segment data一部分是老数据,一部分是新数据,那么截断新数据,缓存进receiving_window中.
- 2. 将receiving_window中 已经重组好的字节 压入 output bytestream中(3.)
- 就是 根据规则移动receiving_window接收窗口
- 1. 将segment data的相应部分,正确的缓存在receiving_window中(1.)
核心代码逻辑如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
// 0. corner case
if(corner(data,index,eof))
return ;
_first_unread = _output.bytes_read();
_first_unassembled = _output.bytes_written();
// 1. 将data的相应部分cached into receiving_window
size_t last_idx = cached_into_receiving_window(data,index,non);
// 2. 计算eof下标
whether_eof(data,index,eof,last_idx);
// 3. 将receiving_window中的顺序字节加入bytestream,宏观来看就是移动接收窗口
move_receiving_window();
}test passed
- 几个小问题
- 2个小bug
- eof本身并不占据字节流中的索引位置(即不消耗stream_idx),故即使其位于first_unacceptable(recving_window的右开边界),也可以将eof加入到bytestream中。
- 如果push_segment之前已经有了eof,那么接下来的push_segment该怎么办?
- 首先bytestream 的eof标志后面,就不应当再加入任何字节到bytestream中。(即外界禁止调用bytestream.write(data))
- 其次关于这个问题,我们应当看eof位于哪里。
- 如果eof已经加入了bytestream,则接下来的push_segment直接返回。因为此时bytestream已经关闭了,再往receive_window中加也没有意义,并且逻辑上来讲就不该再有字节。
- 如果eof只是在receive_window中,也即还并没有加入bytestream,则正常push_segment。(因为此时receive_window中eof之前 还并没有形成连续的字节。)直到接收窗口中字节重组完毕 连带着eof加入bytestream。
- 对于字节流中的同一下标位置,是否会出现不同的字节?也即对于同一index,是否会出现不同的data?该如何处理?
- 本实验中认为不会出现这种不一致的情况,也即外界调用push_segment 传给reassembler的字节流是一个唯一的字节流,且所有的segment 是字节流的正确的一个个切片。
- 2个小bug
杂记
感觉大部分时间都画在搞懂实验要求上了。。
明确我们要实现的是个接收窗口之后 就好办很多了
- 代码拆开见下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof)
{
// corner case 1 : data empty
if(data.empty() && (!eof))
return ;
// corner case 2 : data empty and eof
if(data.empty() && eof)
{
_output.end_input();
return ;
}
_first_unread = _output.bytes_read();
_first_unassembled = _output.bytes_written();
// 1. 将data的相应部分 正确的放入receving window O(n)
// (1). data全部是已经排好序的老数据,即data全部是已经加入bytestream _output的数据,
// 则不必加入bytestream,也不必有其他操作
if (index + data.size() < _first_unassembled) {
return; // nothiing
}
// (2). data全部是还没加入bytestream output的数据
// 则将其加入_receving_window、这里可能会重复加入,效率低,不过先无所谓了,保证正确性再说别的。
else if (index >= _first_unassembled && index < first_unacceptable()) {
for (size_t i = 0; i < len; ++i) {
_receving_window[index + i] = data[i];
}
last_idx = index + len;
}
// (3). data全部位于receving_window范围之外
else if (index >= first_unacceptable()) {
return; // nothing
}
// (4). data一部分加入 一部分没加入bytestream
// 则截取相应部分落入recv_window
else if (index < _first_unassembled && index + data.size() >= _first_unassembled) {
for (size_t i = 0; i < len; ++i) {
_receving_window[_first_unassembled + i] = data[i + start_idx];
}
last_idx = _first_unassembled + len;
} else {
cout<<"sth unknown happened!!"<<endl;
}
if (eof && index + data.size() <= first_unacceptable()) { // 注意是 <= 。eof本身并不占据字节流中的位置(stream_idx),只是标记结束。
_eof = true;
_eof_idx = last_idx;
}
cout<<"============receving window to bytestream============="<<endl;
size_t old_first_unacceptable = first_unacceptable();
// 2. 将recv_window中已经顺序的加入bytestream
for (size_t i = _first_unassembled; i <= old_first_unacceptable; ++i) { // == first_unacceptable 仅仅是为了eof可能出现在first_unacceptable处。
if(i == _eof_idx && _eof)
{
_output.end_input();
break;
}
if(i == old_first_unacceptable)
break;
if (_receving_window.find(i) == _receving_window.end())
break;
// 从recving_window进入bytestream
_output.write(string(1,_receving_window[i]));
// 从recving_window中移除
_receving_window.erase(i);
}
}