心血来潮,给lab4来个性能优化. 失败
成功了
结果如图
方式:改进StreamReassembler + ByteStream
分析 & 优化
- You may need to profile your code or reason about where it is slow, and you may have to improve your implementation of some of the critical modules (e.g., ByteStream or StreamReassembler) to get to this point.
尝试优化 ByteStream (失败)
- 根据同学支招 , 尝试将ByteStream中的deque< char>替换为BufferList,不过效果不太明显甚至导致性能更差.
- 分析之后我认为原因如下几点
- a. bytestream由StreamReassembler调用 , 我实现的策略是StreamReassembler逐个字节的扫描并write进bytestream. 那么如果在stream.write()为一个字节造了个Buffer , 还要再填入BufferList , 得不偿失.
- b. 并且由于StreamReassembler策略(逐byte写入)会导致频繁的调用output_bytestream.write(),导致BufferList里面的buffer数量急剧增多,在求取BufferList.size()时会极耗费时间.
- c. 更何况,即便使用了Buffer(shared_ptr管理data) ,每个字节进入bytestream必然要1次拷贝(因为传入的是const &) , 从bytestream离开也必然需要1次拷贝. 这点来讲这实际上和我的 deque< char > 并无差别.
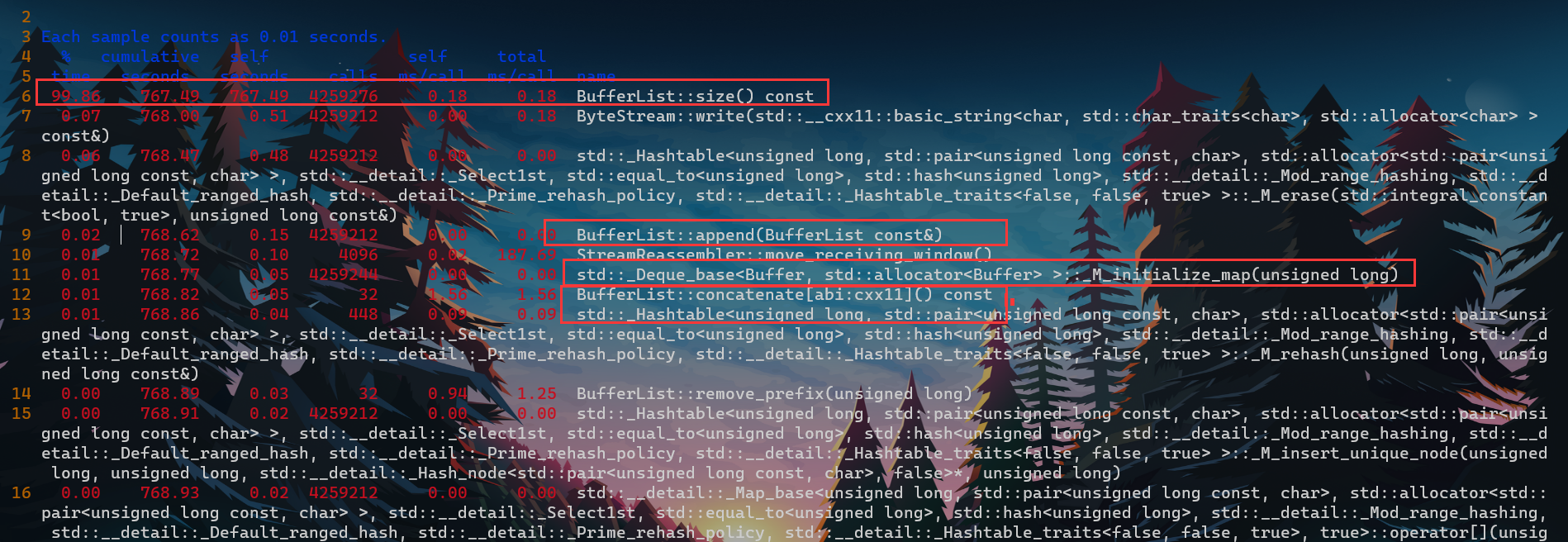
- gropf验证一下 , 可以看到BufferList造成的开销更大(归咎于StreamReassembler策略)
- 分析之后我认为原因如下几点
- 总结: 我的性能热点不在这里。即不在于str进出bytestream的拷贝次数过多. md浪费时间了
性能热点确定 : StreamReassembler
完全未优化图
- 使用gropf得到
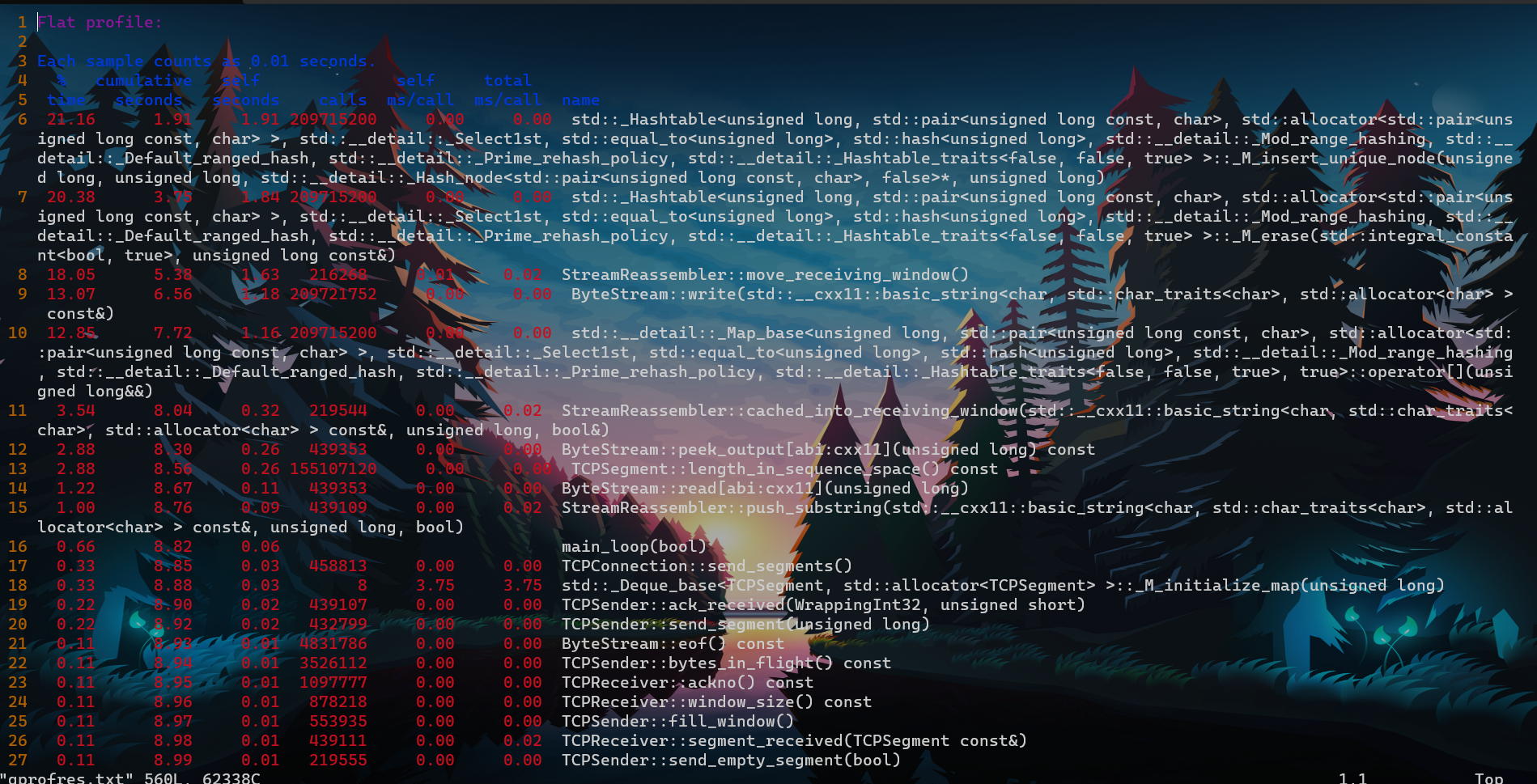
- 从图中可以看到,性能消耗的大头在于unordered_map和move_receiving_window , 也即性能热点都在StreamReassembler. 有点麻烦啊靠。
- unordered_map应该没啥优化空间了(也有,避免重复缓存),复杂度平摊下来O(1) ; 那么就是优化move_receiving_window. 我的代码没有时刻记录能移动到的位置,只能最后遍历一次. 所以应该尝试在重组字节的时候就记录下最大的顺序字节的位置. 日后有时间再尝试吧. 这一下午就当打游戏了…… 悲
- 突然想起来当时写StreamReassembler时,写到这部分时考虑过是否性能会较低,不过当时偷懒先只追求正确性了,可恶.
- 有时间再继续优化吧. 不赶趟了不赶趟了 快点复习数据库考试吧.
优化成功
优化StreamReassembler
- 优化成果

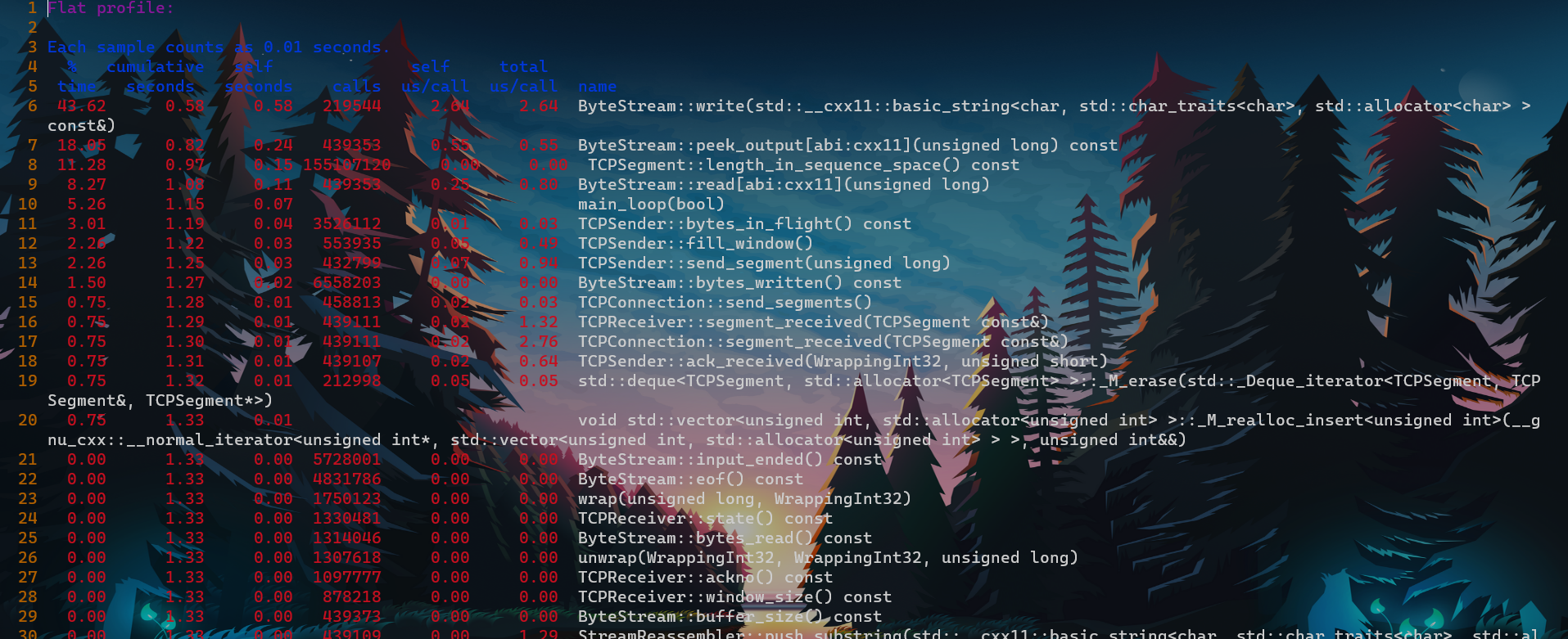
- 请和上图未优化对比
优化前后原理对比.改进StreamReassembler使得性能变高原因123
- 优化之前 底层容器 : unordered_map<size_t , char>
- 原先的策略,仅仅是为了保证正确性,以单个字符的形式维护char,无法维护字节连续的信息,只能每次通过遍历获取
- 向bytestreampush的时候,每次只能write1个字节,边遍历边write。
- 对于到来的char,哪怕这些char之前已经缓存过,还是重新缓存一遍(也即,每个char会加入到receive_window中多次),对于重复的大量字符串,效率极差.
1
2
3class StreamReassembler {
private:
unordered_map<size_t , char> _receving_window; // 乱序到达的,还没加入bytestream的bytes
- 原先的策略,仅仅是为了保证正确性,以单个字符的形式维护char,无法维护字节连续的信息,只能每次通过遍历获取
- 优化之后 底层容器 :map<size_t , string>
1
2
3
4
5
6
7
8class StreamReassembler {
private:
// map : 为支持二分查找. 找到新来串的上一个分组(称为前串)和下一个分组(称为后串)
// 前串 :prev_idx <= now_idx
// 后串 :ne_idx > now_idx
map<size_t , string> _receving_window; // 起始下标为key的string
// 维护receive_window中字节个数
size_t _receiving_window_size{0}; - 相比之下,通过map<size_t,string>可以以块的形式(因为底层用的是string)维护字节,即可以维护哪些块是连续的,以及其连续范围
- 故现在的策略,对于缓存的char,可以维护哪些字符是连在一起的。
- 原因之1. : 这样不会重复缓存已经缓存过的char! 每个char只会缓存一次. 也即 每个char只会加到 receive_window中一次!。
- 可以看到两张性能分析图中,对于StreamReassembler::底层容器unordered_map的查询、插入不再是性能热点
- 原因之2. : 且这样调用write的时候不必1个char1个char的遍历、write。直接write一个string即可。
- 原先StreamReassembler(unordered_map<size_t,char>)调用write时只能传递char,故每个char在传参的时候都会拷贝一次,这个const &就跟直接传值一样。那么对于一个大字符串,每个字符都要拷贝一次。
- 为什么原先只能传递char 不能传递string呢? 因为原先是以char为单元来对窗口进行维护的,也没有维护哪些字符连续,只能边遍历边传unordered_map里的字符char拷贝给write
- 而我们将StreamReassembler 底层容器改为 map<size_t,string>时,可以以块(string)的形式维护字节连续的信息,这样当我们调用write的时候,直接传入给write const string &的就是map里的string,所以是以引用的方式传递的,故减少了拷贝的时间和内存上的消耗
- 这就是改变StreamReassembler提升性能的原因之2
- 可以看到两张性能分析图中,moving_receive_window,即原先一个一个给bytestream write char,在这里也不是热点了。整个push_substring里都没有性能消耗过大的.
- 原先StreamReassembler(unordered_map<size_t,char>)调用write时只能传递char,故每个char在传参的时候都会拷贝一次,这个const &就跟直接传值一样。那么对于一个大字符串,每个字符都要拷贝一次。
- 原因之3. : 原先StreamReassembler(unordered_map<size_t,char>)调用write时只能传递1个1个char,对于大量字符串,调用write的次数会极多,write开辟和回退栈帧的消耗会变得很大。
- 可以看到两张性能分析图中,moving_receive_window,即原先一个一个给bytestream write char,在这里也不是热点了。整个push_substring里都没有性能消耗过大的,
- 原因之1. : 这样不会重复缓存已经缓存过的char! 每个char只会缓存一次. 也即 每个char只会加到 receive_window中一次!。
- StreamReassembler改进后的思路: 参考
- 根据idx,寻找data的(1.1)前串和((1.2)后串,去除data和前串和后串重叠(覆盖)的部分,得到一个独立的data
- 然后判断能否将该独立的(不和其他串重叠)data压入bytestream中,若能,则写入,且写入之后要查询后续串是否能够写入,因为当前串的写入可能导致后续串被写入.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
// 1. 寻找前串,确定data_start_offset
prev_iter = _receving_window.upper_bound(index); // >
--prev_iter;
data_new_index = data非重叠的起始
// 去除重叠的data前缀.
// 去除前缀后的起始idx : data_new_index.
// 相对offset : data_start_offset
// data大小 : data_size
data_start_offset = new_idx - index
data_size = data.size() - (new_idx - index) // 还得处理下eof
// 寻找后串 : 确定data_size. (去掉全部覆盖的以及重叠后缀)
ne_iter = _receving_window.lower_bound(new_idx);
// 如果和后面的重叠
while(如果当前data和后串ne重叠)
{
if(new data 全部覆盖 ne_iter)
覆盖. erase 掉ne_iter
else
new data 部分覆盖 ne_iter,去除后缀,确定data长度
break;
}
!!!阶段1完成
至此,我们得到的 data.substr(data_start_offset,data_size)
是一个不和receive_window中其他字段重叠的data
开始阶段2
接下来只开始将data写入bytestream
isolated_data = data.substr(data_start_offset,data_size);
if(新串不可写)
存入receive_window.insert(isolated_data)
else if(新串可写)
写入
将没写完的存入receive_window
// 本次来的新串写入bytestream之后 , 有可能造成别的串也可以压入bytestream了。
for(iter = 遍历receive_window中的串;)
{
// 维护 receive_window_size
// 全部写入
_receving_window.insert({nidx,std::move(str.substr(written))});
iter = _receving_window.erase(iter);
}
处理eof
}
- 然后判断能否将该独立的(不和其他串重叠)data压入bytestream中,若能,则写入,且写入之后要查询后续串是否能够写入,因为当前串的写入可能导致后续串被写入.
优化ByteStream
- 上面优化完重排器后,性能已经从0.1Gbit/s达到了1.1Gbit/s
- 继续优化,我们将ByteStream内部的底层容器改成BufferList.(deque
) - 先看优化成果
实现如下
原先:deque
;现在:deque 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class ByteStream {
private:
// 原先:
// deque<char> _stream;
// 现在:
BufferList _stream;
public:
size_t ByteStream::write(const string &data) {
get bytes_to_write;
// 原先:一个一个char的copy
// for (size_t i = 0; i < bytes_to_write; ++i) {
// _stream.push_back(data[i]);
// }
// 现在:substr copy 一次 ; 然后一次move到_stream中
_stream.append(std::move(data.substr(0,bytes_to_write)));
}- 性能变高原因:调用push_back次数。
- 在write里面,使用vector
时,每次只能push_back一个char,对于大string,会push很多很多次,push_back开辟和回退栈帧的开销也会很大. - 使用deque
时,只需要一次push_back,就能得到所有char. 开辟回退栈帧开销小. - 两张性能分析图对比,明显看到,现在write不再是性能热点.
- 在write里面,使用vector
- 性能变高原因:调用push_back次数。
注意:实际上在ByteStream类内,write函数中,对字符的拷贝次数并无差别。push到队列,每个字符要拷贝一次;pop出去,还要拷贝一次。
- 可以看到,在ByteStream内部,底层容器采用BufferList还是deque
,对于在write中,拷贝char次数是相同的. - 采用deque
,每次push_back(char)的时候会有拷贝一个字符,最终会拷贝data的所有字符,将其放入deque中 - 采用BufferList(deque
, Buffer即shared_ptr拥有着一个string;可以看作是个deque ) - 则虽然string不同于char,是个内部有移动构造函数的对象
- 但是,由于data是个const & , 我们为了获取它的字符,还是需要substr一次。而substr是一个拷贝. 故 还是会拷贝一次string里所有的char
- 可以看到,在ByteStream内部,底层容器采用BufferList还是deque
分析 & gprof 和 gprof2dot.py 使用
gprof使用
- 编译选项 -g更改为 -pg
- ./apps/tcp_benchmark 运行一下生成gmon.out
- 分析生成的gmon.out :
gprof ./apps/tcp_benchmark
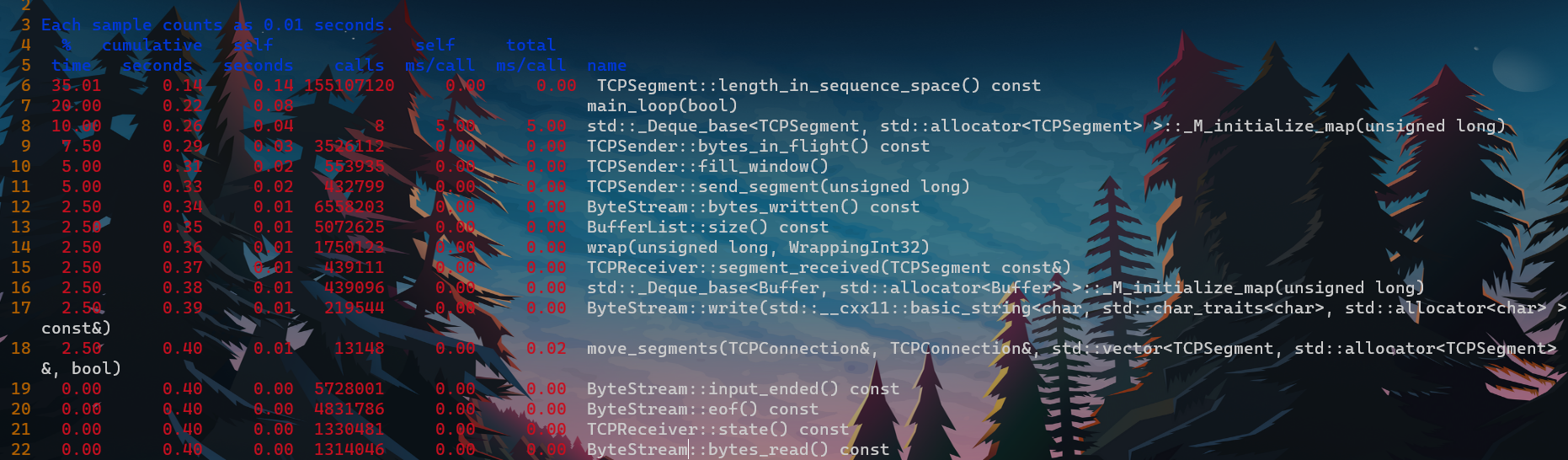
- 函数消耗时间分析. 依据self seconds进行排序

- call graph段. 描述函数调用关系
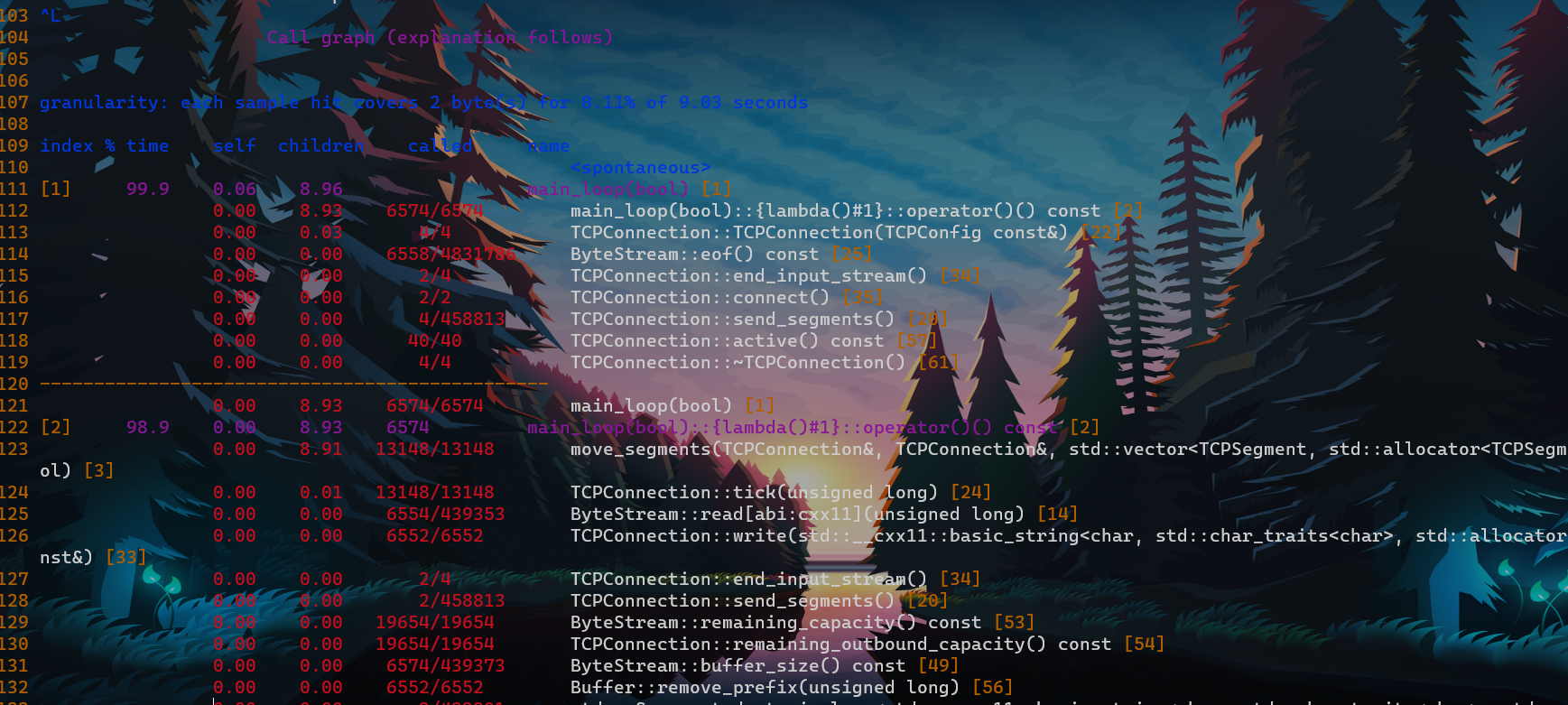
- 分析生成的gmon.out :
图形化 : gprof2dot.py使用
- 还是先生成gmon.out
- 分析生成的gmon.out , 并将输出传递给gprof2dot.py , 处理完之后传给dot. 生成png
-
sudo gprof ./apps/tcp_benchmark | gprof2dot.py | dot -Tpng -o report.png 
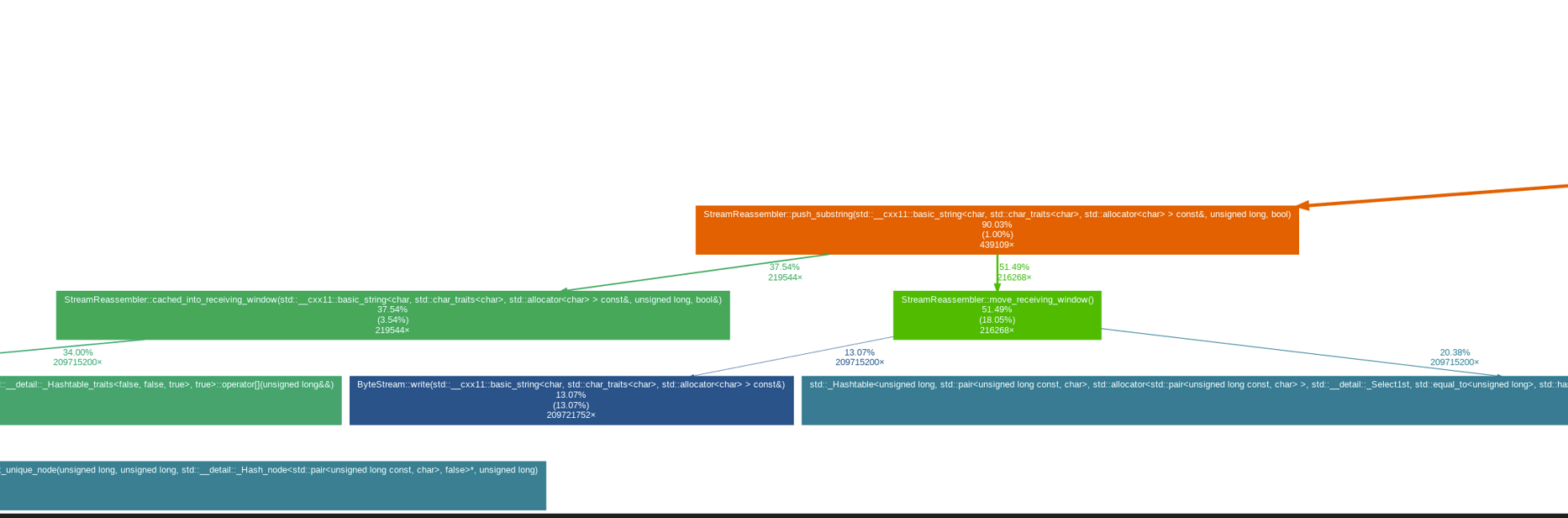
gprof 缺陷:只能分析应用程序在运行过程中所消耗掉的用户时间,无法得到程序内核空间的运行时间。
这类工具还有valgrind, google perftools , perf , systemtap , oprofile , dtrace 有时间再研究.