关于如何发送TCP segment
- user负责 TCP
- user负责 TCP,IP
- user负责 TCP IP Ethernet
- CS144目标实现的就是从TCP到Ethernet全部在用户态实现.
- Ethernet报文的封装和解封装就由NetWorkInterface来做
实现一个NetWorkInterface
- 发送IP datagram –封装–> linker-layer frame
- 接收 linker-layer frame —解封–> IP datagram
- 在执行封装IP datagram成linker-layer frame时 , 需要ip->mac地址,这时就需要用到arp协议
- 涉及处理 arp table , 缓存未知mac的ipdatagram等
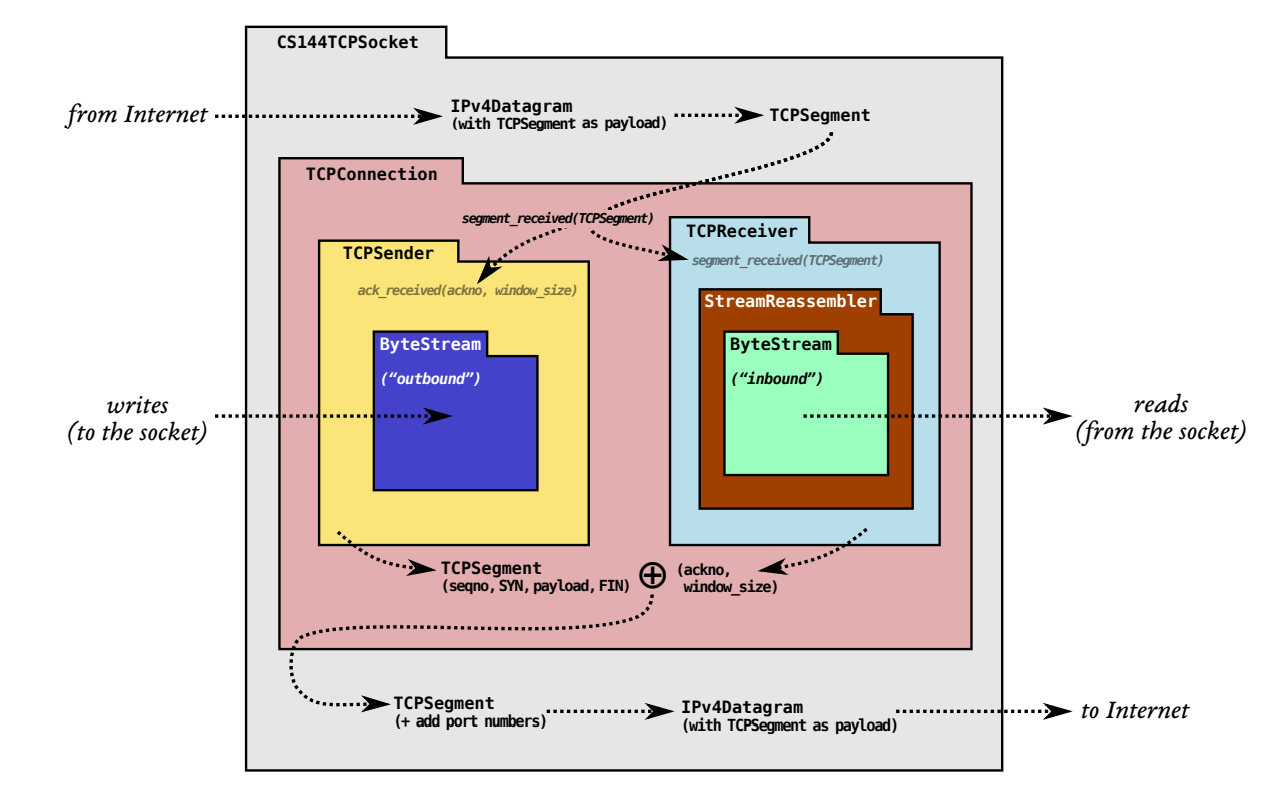
计算机网络-CS144-lab4
- TCPConnection : 基于之前实现的 TCPReciver和TCPSender ; 作为完整的一端的TCP实现
- 功能以及对应核心函数如下
- 接收segment : segment_received
- 本端接收seg 并根据自身receiver以及sender状态 发送相应seg给peer
- 注意在segment_receive中 会自动调用send_segments()
- 发送segment : send_segment. (会捎带ack)
- pass时间 : tick. 可能触发重传
- shutdown关闭连接
- unclean_shutdown : 清空要发送的seg , 根据是否主动异常,发送rst , 设置_sender和receiver状态error , active_ = false
- active unclean_shutdown : send rst
- passive unclean shut_down : not send rst
- clean_shutdown : active = false
- active clean_shutdown : 在tick时 判断是否经历完TIME_WAIT, 经历完,则clean_shutdown
- passive clean_shutdown : 在segment_recieve接收完FIN的ACK后发现进入CLOSED状态,则clean_shutdown
- unclean_shutdown : 清空要发送的seg , 根据是否主动异常,发送rst , 设置_sender和receiver状态error , active_ = false
- 接收segment : segment_received
- 功能以及对应核心函数如下
- 最核心的一点 : 如何确定结束连接. When TCPConnection is Done
- unclean shutdown : 接收或发送rst就立刻结束连接
- clean shutdown
- 需要满足#1#2#3#4
- 只有一端同时满足四个条件,该端才能认为TCPConnection is done. 结束连接.
- 对于#4有两种情况可以满足
- active close : A. 无法确定100%满足,只能通过TIME_WAIT接近100%
- 这也就是由于两军问题,不可能去保证两端(主动关闭的无法一定达成clean shutdown)都能达成clean shutdown,但是TCP已经尽可能地接近了。
- passive close : B. 100%满足
- 被动关闭的一端无需linger time,可以100%达成clean_shutdown
- active close : A. 无法确定100%满足,只能通过TIME_WAIT接近100%
muduo-http
muduo httpServer原理以及使用
为什么要加个httpServer ?
因为之前做校园猫管理平台的时候,底层用的就是这个之前学习做的tinyMuduo.
但是由于时间紧张,当时只是client和server裸发送json字符串,没有使用正经的应用层协议,遂在期末结束后给原先光秃秃的tcp server加一层http.
基本都是看完Muduo之后默着写 然后再改的。。
不难,就是string处理琐碎烦人.
计算机网络-传输层-拥塞控制
TCP 拥塞控制 : 为了公平性
原理(拥塞窗口)、原因、算法
算法包括 慢启动 拥塞避免 快速恢复 拥塞发生
计算机网络-CS144-lab3
- 实现 TCPSender
- 发送新segment : fill_window() when 上层有数据 && receive_window有空间
- fill_window 负责一直向后走 发送新数据. 更新send_window
- 重传的部分交由tick()来做
- 定时器超时重传 : tick()
- 更新send_window ; 重启定时器 ; 超时重传 , RTO加倍
- Retransmission Timer [RFC]
- 收到ACK报文 : ack_received()
- 更新rwnd , sender自动继续发送fill_window.(因为rwnd可能变大)
- 发送新segment : fill_window() when 上层有数据 && receive_window有空间
- 我们Sender并没有实现快速重传(可以不实现,易知不影响其正确性,仍然可以可靠传输)
- 有趣的是我们Sender并没有实现拥塞控制,但TCP仍然可以正常运行.
- 原因如下 : 拥塞控制只是为了TCP的公平性,使得其不会无节制的占用带宽. 如我们的信道中有两条TCP连接,若都实现了拥塞控制,那么最终二者所占带宽会向y=x收敛.
- 而为了保证己方Sender可以和对端Receiver正常交互,我们只需要保证:
- 每个字节都令对方接受到并返回ACK : 重传保证
- 对端receiver不会由于己方发送过快而导致receiver buf缓存溢出
- 这通过流量控制就解决了.
计算机网络-CS144-lab2
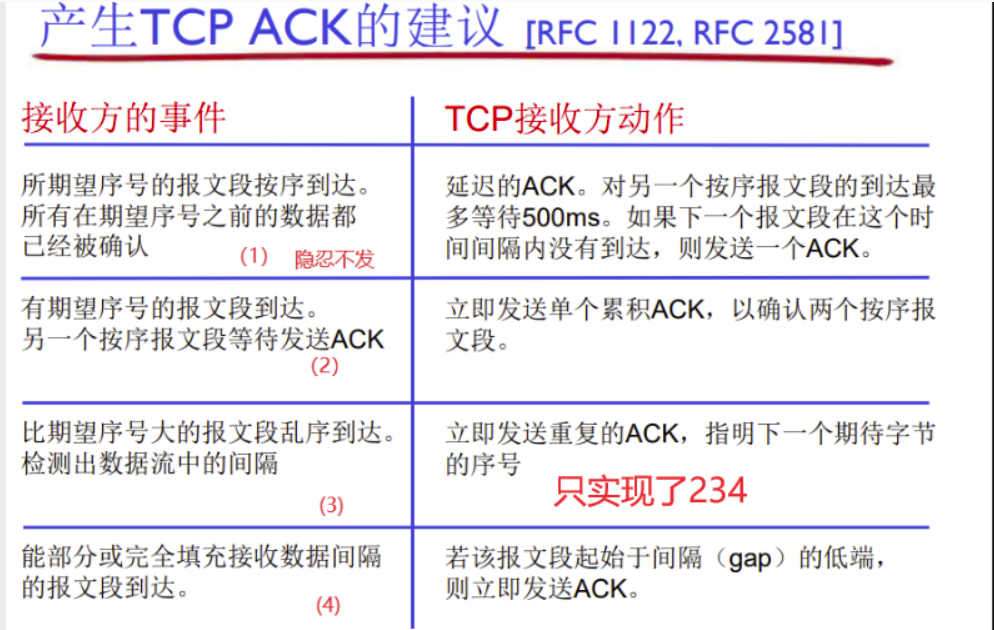
一言以蔽之
lab2实现的tcp receiver
- (0) 转换stream_idx ,abs_seq ,seq(属于内部功能)
- (1) 利用 StreamReassembler对 接收到的segment进行重组 并压入bytestream
- (2) 填充receive_window的相关信息:ackno , window_size, 从而实现flow-control流量控制
- (3) 根据 接收到的报文 对tcp receiver进行状态划分. listen syn_recv fin_recv
我们的receiver只实现了234
计算机网络-CS144-lab1
- lab1 : 实现一个接收端的重排器
- lab2实现的 TCP receiver 的重要功能:处理乱序到达的数据包 ,该功能即lab1 所谓的 重排器 reassembler
- 就是让我们实现一个tcp的滑动窗口协议的接收端。
- TCP协议中的滑动窗口协议是SR协议和GBN协议的结合
- 发送窗口 > 1
- ack代表 : 接收方接收到的顺序到来的最后一个字节 + 1
- 像GBN协议的部分 :
- 发送窗口内只有一个定时器(窗口内最老的分组的定时器)
- 发送ack累计确认
- 像SR协议的部分 :
- 可以乱序接收
- sender重传超时分组(最老的),receiver给sender发送新的ackno , sender可以发送新的数据. 是否重传发送窗口中的其他分组,取决于ackno的大小. 若大于send window中的所有segment , 则清空send window,不必重传所有分组. 若小于send window中的某些segment , 则会重传这某些分组.
- 我目前认为网上有些人说的 重传 所有分组 是不对的。又不是GBN协议. receve window是 > 0的
receiving_window 接收窗口 [the first unassembled , the first unaccepted)
capacity = bytestream.buffer_size() + receiving_window.size()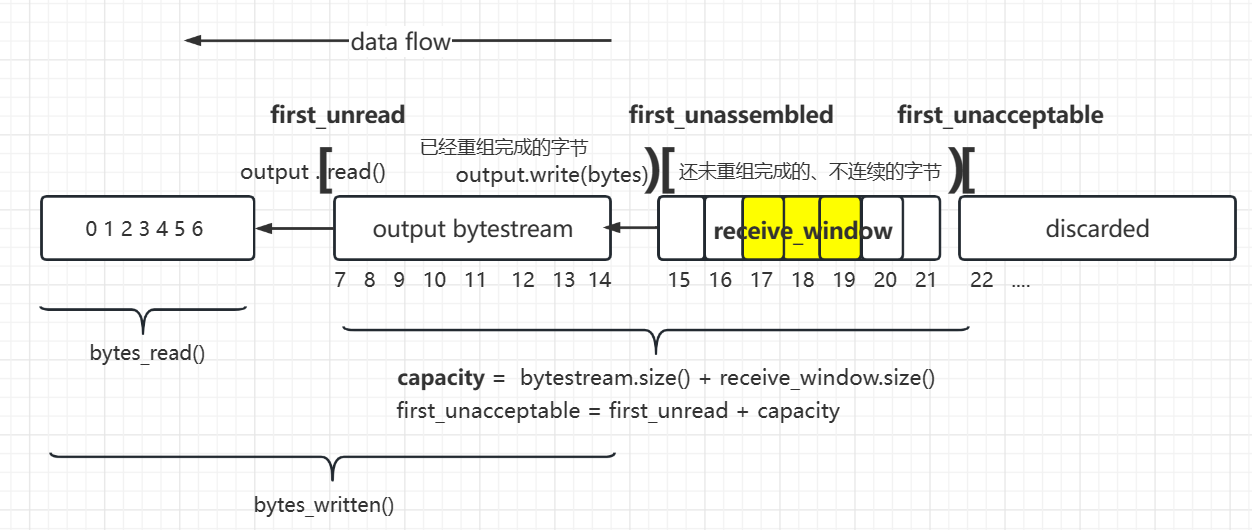
从某种意义上来说,receive_window就是就是从bytestream中划出了一部分用作乱序缓存
bytestream(顺序字节) + receive_window(乱序字节) = capacity
计算机网络-CS144-lab0
实现流量有限的bytestream,支持读写.
是TCPSender和TCPReceiver与用户层的接口.
app通过bytestream向下TCPSender写入
TCPReceiver通过bytestream向上app交付数据
操作系统-xv6-lab总结
历时2月有余。完成了lab1-lab10。由于疫情遣返一堆事儿,故net-work lab只能有时间再做了。
不得不说,跟这门课真的是相见恨晚,之前不清不楚的知识点和机制,在阅读xv6的代码时都有了更为清晰的认知。
比如一个进程究竟是怎么被划分成用户线程和内核线程的?(内核进程:就是在内核维护了进程陷入内核后的函数调用栈)
比如页表究竟是如何运作的?我原先甚至都不知道页表还分成用户页表和内核页表,内核究竟是如何使用用户传入的虚拟地址的?(进程的内核页表中维护了用户的地址空间)
比如系统调用究竟是如何使得进程陷入内核的?通过trap,那么trap机制究竟是如何做到的?ecall -> trampoline -> 保存用户线程上下文(cpu regs)到结构体trapframe,加载trapframe之前保存的进程的内核线程的信息到cpu上,用户页表切换成内核页表,然后跳转到kernel C code usertrap。然后就是内核根据用户陷入内核的原因以及传入参数,通过一系列函数syscall实现系统调用。
比如进程切换究竟是如何实现的?内核究竟是如何调度不同进程的?内涵和为什么调度不了用户态线程?:内核中的上下文分为每个进程的内核线程,以及一个调度器线程。会有定时器中断等机制,使得os陷入内核,执行调度器线程,其会寻找一个runnable的内核线程(也即寻找一个runnbale的进程),然后运行该内核线程;该内核线程离开内核态时,os就会在用户态运行该进程的用户线程。如此,就实现了进程切换。这也解释了内核为什么不会调度同一个进程的用户态线程,因为内核的调度器线程只能看到进程的内核线程,看不到用户态线程。
比如用户究竟是如何拿到物理内存的?我们常说的malloc啥的,究竟是在那一层次做出的设计。
又比如常说的内核的buffer,是在哪里?是dram里吗?是,就是xv6中的bcache,所有和disk的交互都要通过bacche
又比如socket buffer,是在哪里?:有点忘了,大概是net.c通过kalloc申请出的一些内存用作socket buffer。
又比如lazy allocation? 是如何工作的?:先声明user的一段虚拟地址为合法但不建立映射,然后在用户第一次使用到该地址时,再通过pgfault陷入内核,在进程的user pagetable上为该地址建立虚拟地址到物理地址映射。
又比如cow 是如何实现的?: fork时假分配,哪些process先write,那些process cow真分配
又比如mmap 如何实现的 ? 为什么叫映射 ? 为什么高效 ? :基于lazy allocation实现. 高效: 直接映射到buffer
又比如文件系统
操作系统-xv6-lab8-lock
本节的重点
- 一在于锁机制的优化
- 二在于物理内存如何分配
- 三在于buffer cache如何分配。
- 关于锁机制的优化,我基本上是参考博客
- 至于buffer cache如何分配,在操作系统-xv6-文件系统 buffercache中也已经讲过。
- 下面重点介绍 物理内存是如何分配的,也即user是如何通过malloc申请到物理内存的。
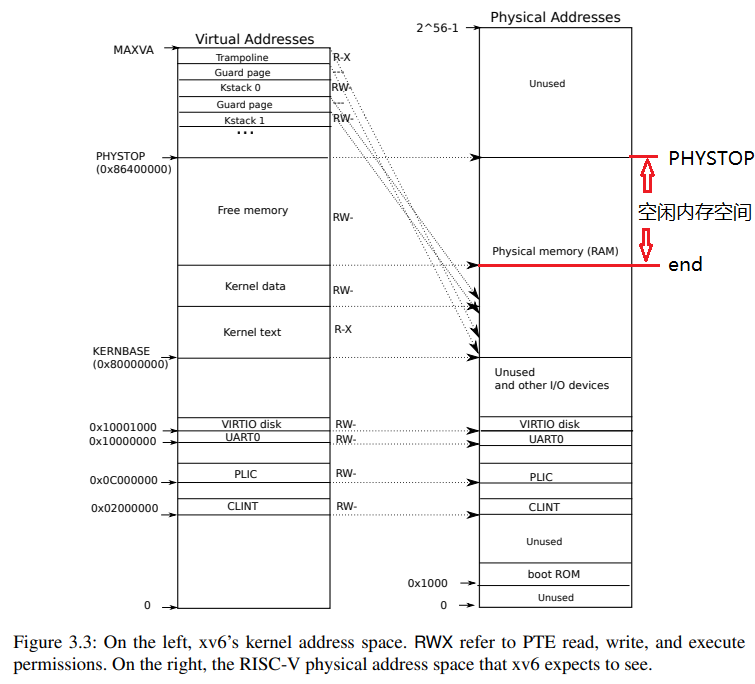
物理内存分配流程
- kernel是如何组织free physical page的。
- xv6 : freelist
- kernel为user提供的sycall接口
- sbrk->sys_sbrk()
- user层是如何封装sbrk的。
- malloc and free (维护了user态的cache list)
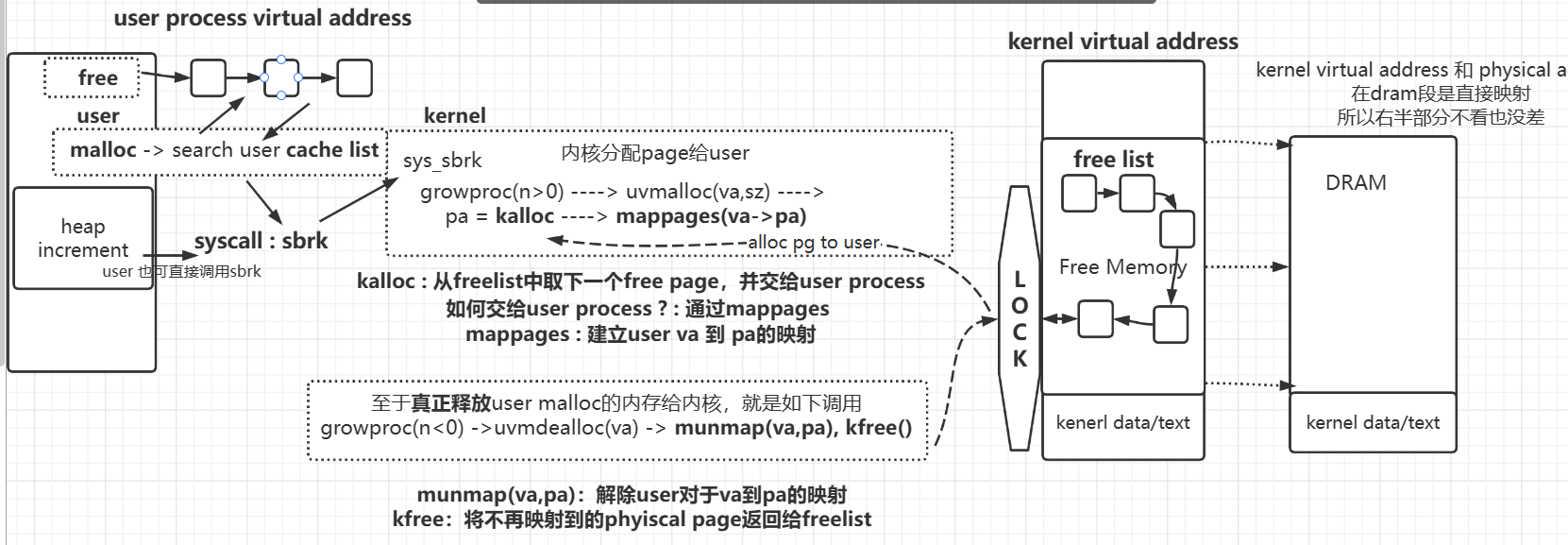
- malloc and free (维护了user态的cache list)
- kernel是如何组织free physical page的。