地址映射关系 即 va -> pa 的 映射
在做本实验之前,xv6的虚拟内存机制如下
- 对于kernel , 内核只有一张全局的kernel pagetable. 所有kernel thread 共用这一张pagetable. 通过MMU使用.
- 对于user , 每个user process的user thread 有一张user pagetable. user通过MMU使用.
- 但对于user传入kernel的va,kernel该如何使用user pgtbl来进行寻址呢 ? kernel 通过软件模拟(walkaddr)来查询user pgtbl 来进行user va的寻址.
- 很显然,效率很低 不如硬件. 现代操作系统采用的也并非是这种机制.
本实验 : 那么 为了让kernel可以直接通过硬件MMU来使用user pagetable. 我们实现如下措施
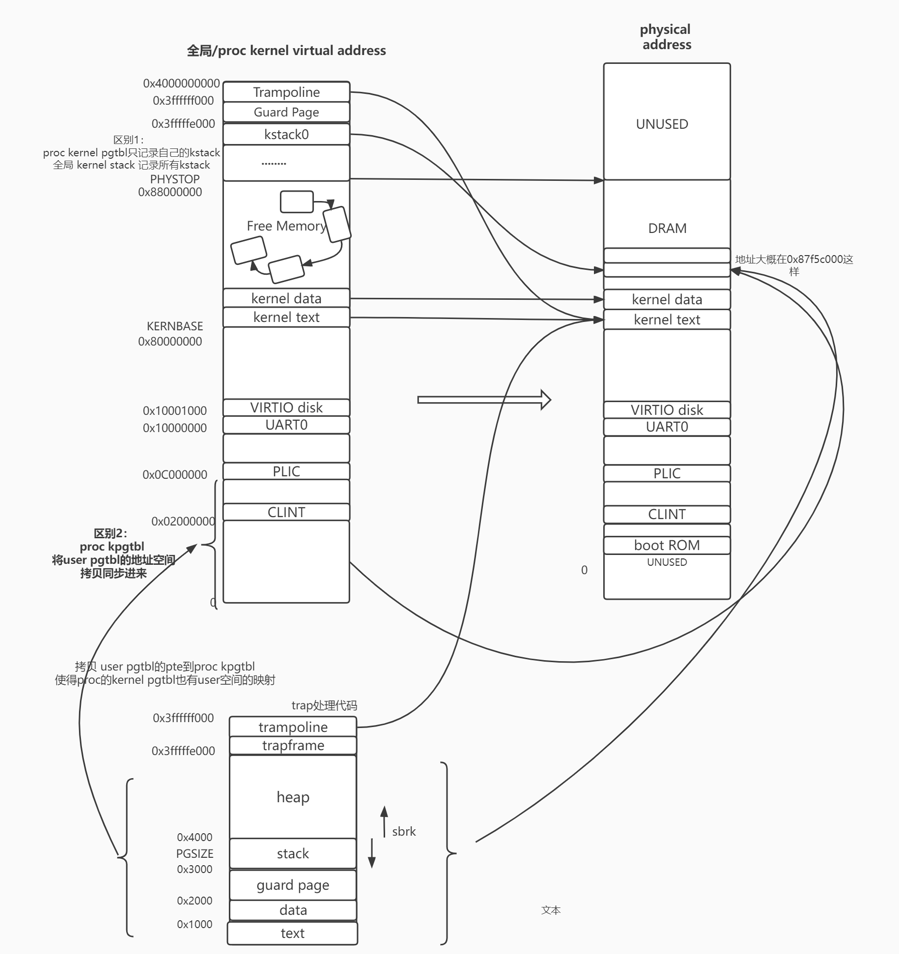
- (以下就是所谓的将内核页表和用户页表合并)
- 为每一个process的kernel thread 都 分配一个 pagetable.
- 且在这个kernel thread pgtable
- 不但维护了kernel 的地址空间映射
- 2. 还要 维护user thread的user pgtable的地址空间的映射(va->pa)
- 对于1. 我们应当 为 每个kernel thread pgtbl建立和 全局 kenrel pgtbl 基本一样的地址映射关系 (kvminitproc)
- 对于2. 我们应当 将user thread pgtbl 的维护的地址映射关系 拷贝到 kernel thread pgtbl 的 [0,0XC00..00-1]处
- 并在 user thread pgtbl 的地址映射关系发生改变时(pte的增加/删除/修改),即时拷贝到kernel thread pgtbl上
- 合并之后,kernel 使用 user va的方式 就是 直接通过MMU在kernel thread pgtbl的user部分进行查询. 而不用通过walkaddr,提高效率
- (以下就是所谓的将内核页表和用户页表合并)
下图就是一个合并user部分后的kernel thread pgtbl
本实验后,xv6的虚拟内存机制如下
- 3个pgtbtl
- 全局 kernel pgtbl (kernel的scheduler thread用)
- user thread pgtbl (user thread用)
- kernel thread pgtbl(包含user部分) (kernel 用)
- 主流的OS也是用这种方法.
- 3个pgtbtl
关于 vm.c 注释见文
关于虚拟内存是否连续见文末