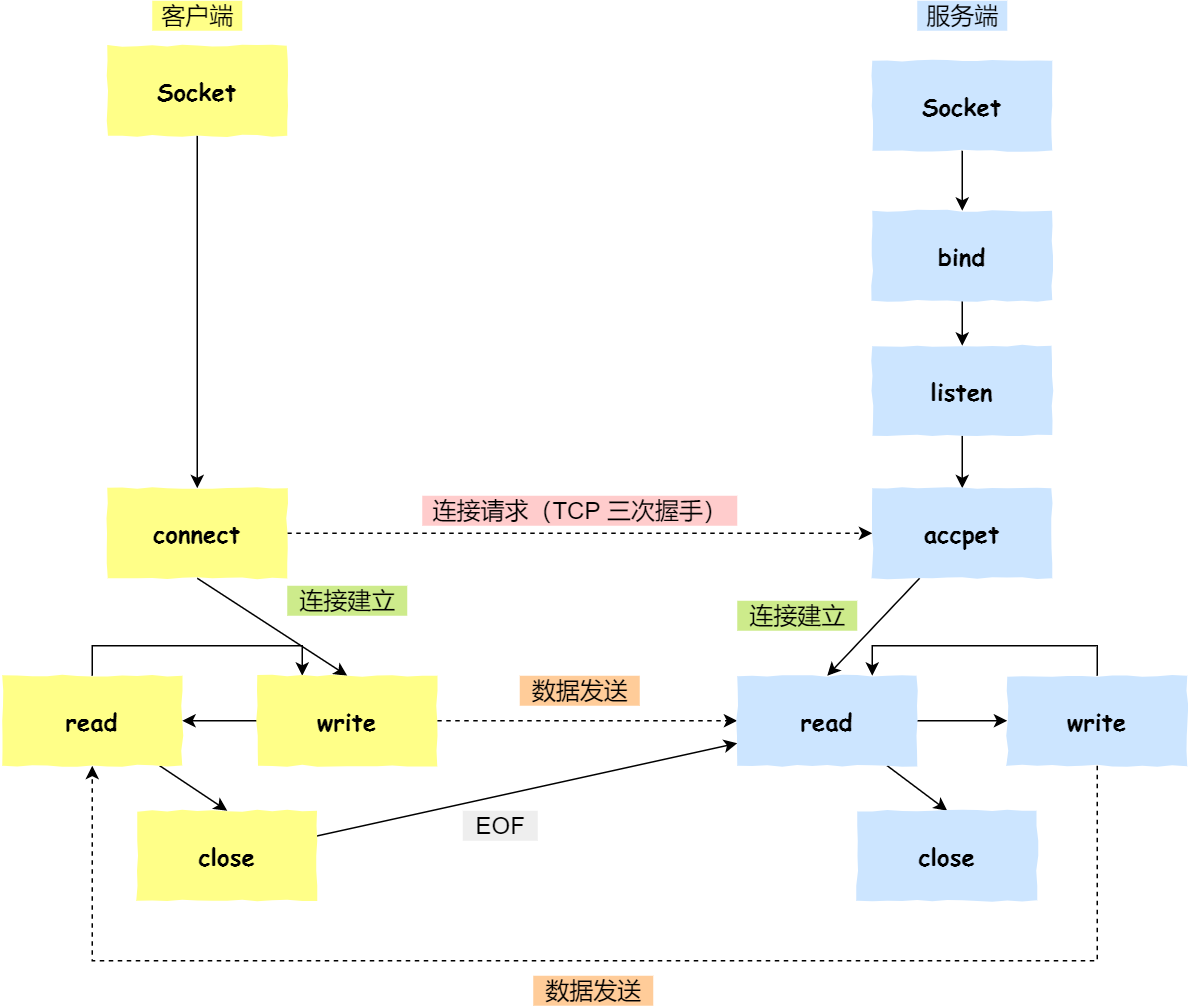
bug及解决
日志
起因:参考《Linux多线程服务端编程》第8章写my_muduo的class EventLoopThread时,想通过timerfd定时器测试功能,结果死循环。
- 注册回调:在main中给EventLoopThread注册回调函数,在回调函数中创建channel以及事件。注册的回调函数会在EventLoopThread startLoop前调用。
两处罪魁祸首


问题发生处
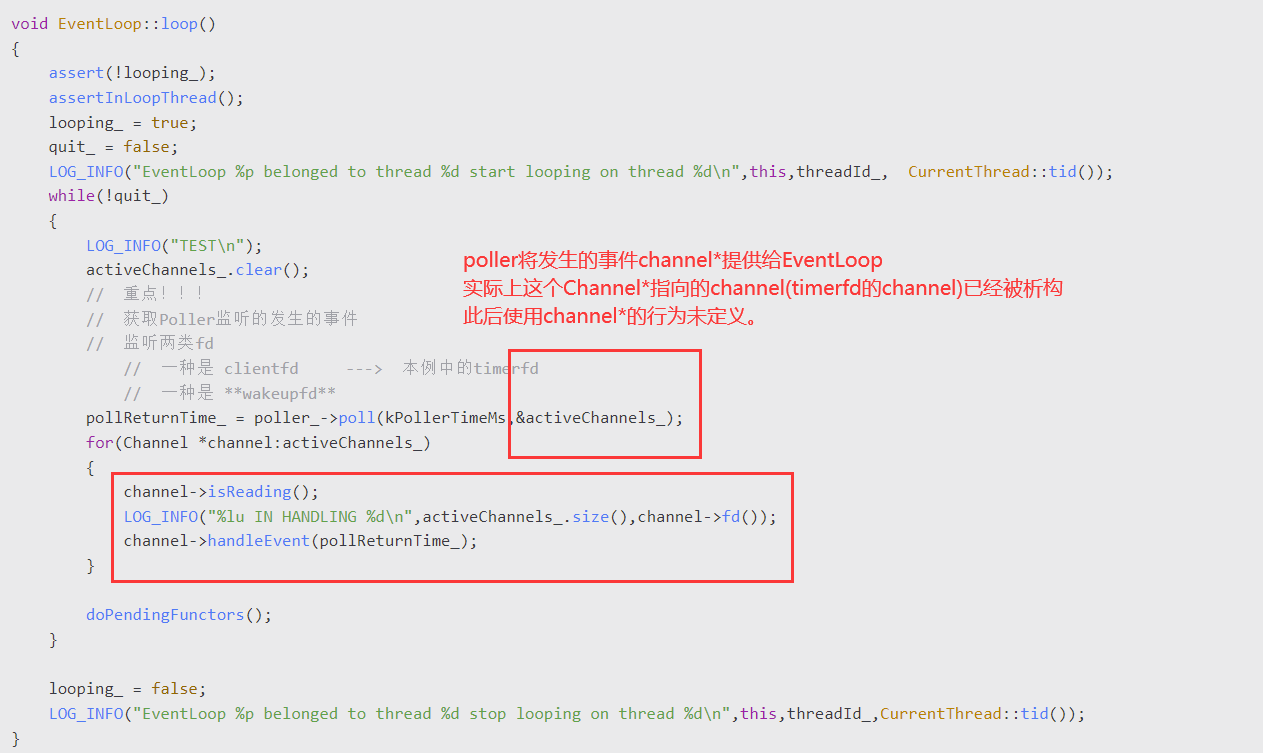
因此会与预期不符。
可以看到 注册到epoll上的是timerfd=5,实际上返回的events.data.ptr指向的channel却是fd=0。
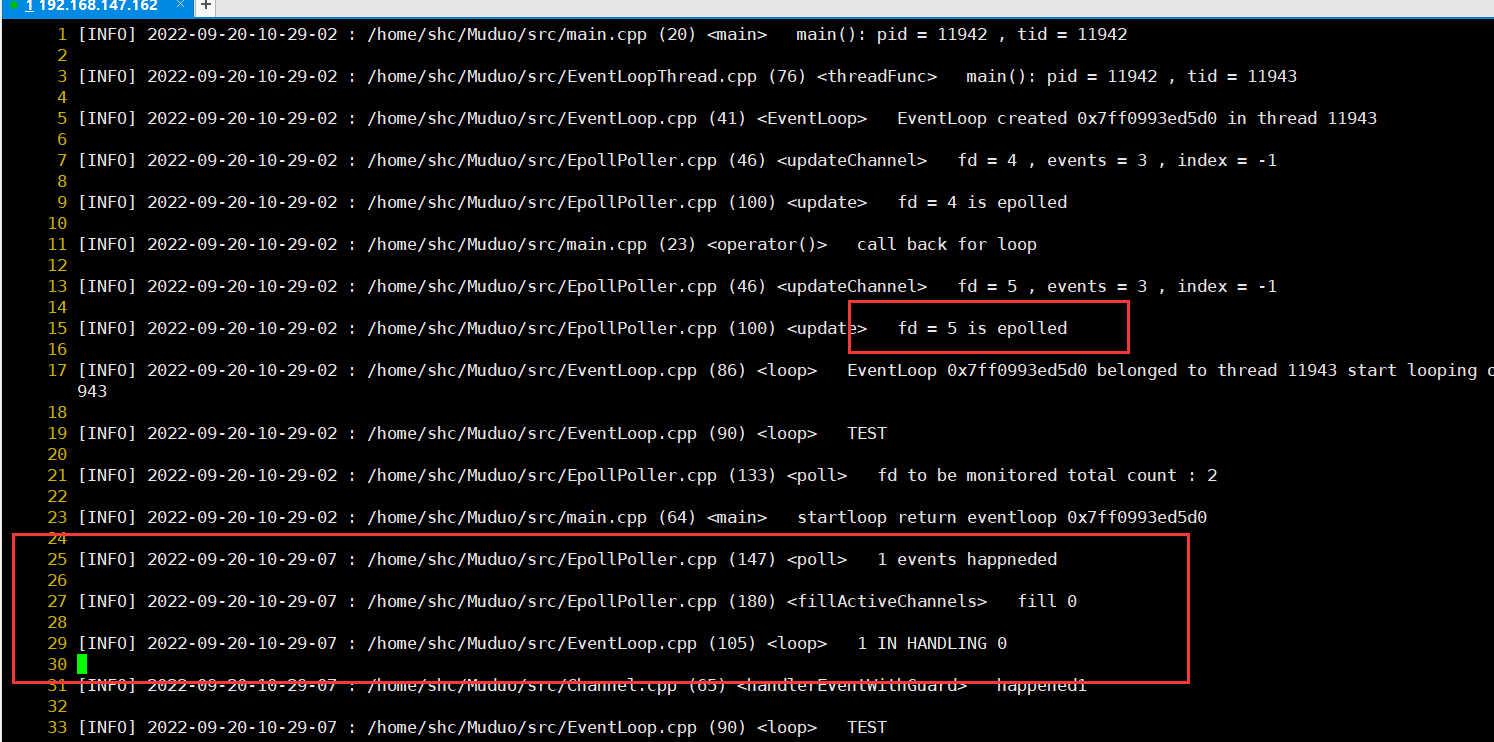
日志打到这里时怀疑是使用了一个已经释放的对象,当时以为会是移动造成,又或者是使用了已经free的堆造成的。
但其实还是不能肯定是内存方面的问题。因为没core dump.很奇怪为啥没core dump?
ASAN
- 参考资料配置AddressSanitizer
- 很强。一下子确定了在何处发生了什么错误。如下,在channel->handleEvent()时,发生stack-use-after-scope。比吭哧吭哧打日志方便很多。
- 并且还可以编译时warning是否有初始化顺序不恰当的代码,比如类的成员在构造函数中初始化与在类中的声明顺序不一致。
- 如此,可以确定时channel指针引用的对象已经不存在,并且是stack-use-after-scope而非heap-use-after-free。问题范围缩小一大半,直接去找定义该channel的地方。发现是在注册的回调函数中定义。因此,该channel出了回调函数就会被析构。(之前误以为注册给EventLoopThread的回调函数在其内部调用会展开,故认为loop结束前channel不会被析构,槽点过多)。
- 更改channel定义的位置,使其不会在loop结束前被析构即可。
- 也不是什么难bug,就是之前对这个内存方面的错误有些阴影,又恰好了解了asan这么好用的工具,因此在这里记录下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108[INFO] 2022-09-20-12-30-33 : /home/shc/Muduo/src/main.cpp (64) <main> startloop return eventloop 0x7f329bafdc40
[INFO] 2022-09-20-12-30-38 : /home/shc/Muduo/src/EpollPoller.cpp (147) <poll> 1 events happneded
[INFO] 2022-09-20-12-30-38 : /home/shc/Muduo/src/EpollPoller.cpp (180) <fillActiveChannels> fill 5
[INFO] 2022-09-20-12-30-38 : /home/shc/Muduo/src/EventLoop.cpp (109) <loop> 1 IN HANDLING 0
=================================================================
==14905==ERROR: AddressSanitizer: stack-use-after-scope on address 0x7f329bafd1d8 at pc 0x55840a7a315c bp 0x7f329bafba70 sp 0x7f329bafba60
READ of size 1 at 0x7f329bafd1d8 thread T1
# 显示过程调用栈 自出现问题处回溯一个个函数
#0 0x55840a7a315b in Channel::handleEvent(Timestamp const&) /home/shc/Muduo/src/Channel.cpp:44
#1 0x55840a7b2707 in EventLoop::loop() /home/shc/Muduo/src/EventLoop.cpp:112
#2 0x55840a7bab27 in EventLoopThread::threadFunc() /home/shc/Muduo/src/EventLoopThread.cpp:93
#3 0x55840a7bc5f3 in void std::__invoke_impl<void, void (EventLoopThread::*&)(), EventLoopThread*&>(std::__invoke_memfun_deref, void (EventLoopThread::*&)(), EventLoopThread*&) /usr/include/c++/7/bits/invoke.h:73
#4 0x55840a7bc450 in std::__invoke_result<void (EventLoopThread::*&)(), EventLoopThread*&>::type std::__invoke<void (EventLoopThread::*&)(), EventLoopThread*&>(void (EventLoopThread::*&)(), EventLoopThread*&) /usr/include/c++/7/bits/invoke.h:95
#5 0x55840a7bc2e9 in void std::_Bind<void (EventLoopThread::*(EventLoopThread*))()>::__call<void, , 0ul>(std::tuple<>&&, std::_Index_tuple<0ul>) /usr/include/c++/7/functional:467
#6 0x55840a7bbf99 in void std::_Bind<void (EventLoopThread::*(EventLoopThread*))()>::operator()<, void>() /usr/include/c++/7/functional:551
#7 0x55840a7bb9a2 in std::_Function_handler<void (), std::_Bind<void (EventLoopThread::*(EventLoopThread*))()> >::_M_invoke(std::_Any_data const&) /usr/include/c++/7/bits/std_function.h:316
#8 0x55840a7a483b in std::function<void ()>::operator()() const /usr/include/c++/7/bits/std_function.h:706
#9 0x55840a7c27c2 in operator() /home/shc/Muduo/src/Thread.cpp:63
#10 0x55840a7c2f78 in __invoke_impl<void, Thread::start()::<lambda()> > /usr/include/c++/7/bits/invoke.h:60
#11 0x55840a7c2bc2 in __invoke<Thread::start()::<lambda()> > /usr/include/c++/7/bits/invoke.h:95
#12 0x55840a7c32e5 in _M_invoke<0> /usr/include/c++/7/thread:234
#13 0x55840a7c326b in operator() /usr/include/c++/7/thread:243
#14 0x55840a7c31cf in _M_run /usr/include/c++/7/thread:186
#15 0x7f329f47e4bf (/usr/lib/x86_64-linux-gnu/libstdc++.so.6+0xd44bf)
#16 0x7f329f7be6da in start_thread (/lib/x86_64-linux-gnu/libpthread.so.0+0x76da)
#17 0x7f329eec261e in __clone (/lib/x86_64-linux-gnu/libc.so.6+0x12161e)
# 在哪里发生错误
Address 0x7f329bafd1d8 is located in stack of thread T1 at offset 5720 in frame
#0 0x55840a7b189d in EventLoop::loop() /home/shc/Muduo/src/EventLoop.cpp:81
This frame has 26 object(s):
[32, 33) '<unknown>'
[96, 97) '<unknown>'
[160, 161) '<unknown>'
[224, 225) '<unknown>'
[288, 289) '<unknown>'
[352, 353) '<unknown>'
[416, 417) '<unknown>'
[480, 481) '<unknown>'
[544, 552) '__for_begin'
[608, 616) '__for_end'
[672, 704) '<unknown>'
[736, 768) '<unknown>'
[800, 832) '<unknown>'
[864, 896) '<unknown>'
[928, 960) '<unknown>'
[992, 1024) '<unknown>'
[1056, 1088) '<unknown>'
[1120, 1152) '<unknown>'
[1184, 1696) 'header'
[1728, 2240) 'header'
[2272, 2784) 'header'
[2816, 3328) 'header'
[3360, 4384) 'buf'
[4416, 5440) 'buf'
[5472, 6496) 'buf' <== Memory access at offset 5720 is inside this variable
[6528, 7552) 'buf'
HINT: this may be a false positive if your program uses some custom stack unwind mechanism or swapcontext
(longjmp and C++ exceptions *are* supported)
# Thred T1在何处由T0生成
Thread T1 created by T0 here:
#0 0x7f329fa0dd2f in __interceptor_pthread_create (/usr/lib/x86_64-linux-gnu/libasan.so.4+0x37d2f)
#1 0x7f329f47e765 in std::thread::_M_start_thread(std::unique_ptr<std::thread::_State, std::default_delete<std::thread::_State> >, void (*)()) (/usr/lib/x86_64-linux-gnu/libstdc++.so.6+0xd4765)
#2 0x55840a7c2931 in Thread::start() /home/shc/Muduo/src/Thread.cpp:64
#3 0x55840a7ba49a in EventLoopThread::startLoop() /home/shc/Muduo/src/EventLoopThread.cpp:53
#4 0x55840a7c5b0a in main /home/shc/Muduo/src/main.cpp:62
#5 0x7f329edc2c86 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x21c86)
# 总结:handleEvent时 发生 stack-use-after-scope
SUMMARY: AddressSanitizer: stack-use-after-scope /home/shc/Muduo/src/Channel.cpp:44 in Channel::handleEvent(Timestamp const&)
Shadow bytes around the buggy address:
0x0fe6d37579e0: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d37579f0: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d3757a00: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d3757a10: f8 f8 f8 f8 f8 f8 f8 f8 f2 f2 f2 f2 f8 f8 f8 f8
0x0fe6d3757a20: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
=>0x0fe6d3757a30: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8[f8]f8 f8 f8 f8
0x0fe6d3757a40: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d3757a50: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d3757a60: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d3757a70: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
0x0fe6d3757a80: f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8 f8
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==14905==ABORTING
ASan Address Sanitizer
- 以下来自
- 谷歌有一系列Sanitizer官网见https://github.com/google/sanitizers,可以用于定位程序中的系列问题,常用的Sanitizer包括
- Address Sanitizer(ASan):用于检测内存使用错误
- Leak Sanitizer(LSan):用于检测内存泄漏
- Thread Sanitizer(TSan):用于检测多线程间的数据竞争和死锁
- Memory Sanitizer(MSan):用于检测使用未初始化内存的行为
概述
- ASan 是 Address Sanitizer 简称,它是一种基于编译器用于快速检测原生代码中内存错误的工具。
- 简而言之,ASan 就是一个用于快速检测内存错误的工具,目前已经集成在LLVM 3.1+和GCC 4.8+中
- 可检测类型

- 原理
- 在编译时,ASan会替换malloc/free接口
- 在程序申请内存时,ASan会额外分配一部分内存来标识该内存的状态
- 在程序使用内存时,ASan会额外进行判断,确认该内存是否可以被访问,并在访问异常时输出错误信息
设置
CMakeLists.txt
1
2
3
4
5
6
7
8
9# 编译设置
add_compile_options(-O0 -ggdb -std=c++14 -Wall -Wextra -mavx2
-fsanitize=address
-fno-omit-frame-pointer
-fno-optimize-sibling-calls
-fsanitize-address-use-after-scope
-fsanitize-recover=address)
# 链接设置
target_link_libraries(muduo pthread -fsanitize=address)环境变量
- llvm-symbolizer运行路径:export ASAN_SYMBOLIZER_PATH=”/usr/bin/llvm-symbolizer”
- ASAN_OPTIONS为ASan运行的Flags:export ASAN_OPTIONS=”halt_on_error=0:log_path=xxx/asan.log:detect_stack_use_after_return=1”

注意
- ASan版本程序在Linux环境下运行时会额外申请20TB的虚拟内存
- 需要确保/proc/sys/vm/overcommit_memory的值不为2
- 这也可以作为检验ASan是否工作的标志
- ASan版本性能大幅受损,大约会下降2x左右
- ASan工具不是万能的,他必须要跑到有问题的代码才可以暴漏出来