Basic x86-64常识以及基本指令
Control 条件码相关、循环、跳转表
Basic
抽象
指令集架构:ISA
- architecture(计算机的体系结构,架构)
- also ISA:instruction set architecture 指令集架构
- 当我们谈论指令和指令集,这是编译器的目标,为你提供一系列指令,告诉机器确切第做了什么
- 事实证明,关于指令如何实现,硬件的实现者已经想好了。有的速度快,需要很多硬件;有的速度慢,但需要很少的硬件。
- 所以,人们创建了instruction set architecture 指令集架构这一抽象概念
- 编译器的目标是他
- 如何最好的实现他是硬件研究者需要负责的
- 处理器实际执行指令是并发执行的,但可以采取措施保证整体行为与ISA指定的顺序执行的行为完全一致。
虚拟地址
- 机器级变成使用多个内存地址是虚拟地址,提供的内存模型看上去是一个非常大的字节数组。
- 程序用虚拟地址寻址,操作系统负责管理虚拟地址空间,将虚拟地址翻译成实际处理器内存的物理地址
text c program —Complier—-> text 汇编asm program —–Assembler—–> binary 文本表示的指令转化成了实际的字节object program ——linker—–> binary executable program
x86-64常识
反汇编
汇编中
- %开头 代表寄存器的实际名称
- 句点.开头,表示他们事实上不是实际指令,而是直到汇编器和链接器工作的伪指令。
- 一些信息提供给调试器,使它能够定位程序的各个部分
- 一些信息提供给链接器,告诉他这是一个全局定义的函数
- 还有很多其他信息,在一开始的时候不需要考虑他们太多,因此先删掉
例子
1
2
3
4
5
6
7
8
9shc@shc-virtual-machine:~/code/csapp_try$ ll
总用量 36
drwxrwxr-x 2 shc shc 4096 5月 31 20:36 ./
drwxr-xr-x 20 shc shc 4096 5月 31 19:43 ../
-rw-rw-r-- 1 shc shc 194 5月 31 20:36 main.c
-rw-rw-r-- 1 shc shc 102 5月 31 19:46 mstore.c
-rw-rw-r-- 1 shc shc 1400 5月 31 20:01 mstore.o
-rw-rw-r-- 1 shc shc 393 5月 31 19:46 mstore.s
-rwxrwxr-x 1 shc shc 8456 5月 31 20:36 prog*gcc -Og -S mstore.c
- O : Optimize 优化
- mstore.c->mstore.s:c语言编译器产生汇编代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22shc@shc-virtual-machine:~/code/csapp_try$ cat mstore.s
.file "mstore.c"
.text
.globl multstore
.type multstore, @function
multstore:
.LFB0:
.cfi_startproc
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movq %rdx, %rbx
call mult2@PLT
movq %rax, (%rbx)
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE0:
.size multstore, .-multstore
.ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
.section .note.GNU-stack,"",@progbits
gcc -Og -c mstore.c
- mstore.c->mstore.o。gcc编译并汇编,生成目标代码文件(机器代码文件)。二进制格式,无法vim直接查看
- gdb查看.o文件
- disassemble 函数名:查看函数二进制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14shc@shc-virtual-machine:~/code/csapp_try$ gdb mstore.o
...
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from mstore.o...(no debugging symbols found)...done.
(gdb) disassemble multstore
Dump of assembler code for function multstore:
0x0000000000000000 <+0>: push %rbx
0x0000000000000001 <+1>: mov %rdx,%rbx
0x0000000000000004 <+4>: callq 0x9 <multstore+9>
0x0000000000000009 <+9>: mov %rax,(%rbx)
0x000000000000000c <+12>: pop %rbx
0x000000000000000d <+13>: retq
End of assembler dump.
- disassemble 函数名:查看函数二进制代码
反汇编器:objdump
- objdump -d mstore.o
1
2
3
4
5
6
7
8
9
10
11
12
13
14shc@shc-virtual-machine:~/code/csapp_try$ objdump -d mstore.o
mstore.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <multstore>:
0: 53 push %rbx
1: 48 89 d3 mov %rdx,%rbx
4: e8 00 00 00 00 callq 9 <multstore+0x9>
9: 48 89 03 mov %rax,(%rbx)
c: 5b pop %rbx
d: c3 retq - 机器代码.o及其反汇编表示的特性
- x86-64的指令长度为1~15字节
- 设计指令格式方式:从某个给定位置开始,可以唯一的将字节解码成机器指令。
- 反汇编程序无法访问源代码,甚至无法访问汇编代码,他只是通过实际代码文件中的字节辨别出来的。
- 反汇编器使用的指令命名规则与gcc生成的汇编代码使用的有细微差别。反汇编器可能省略指令结尾的后缀q(大小指示符)
- objdump -d mstore.o
- gcc -Og -o prog main.c store.c
- 链接:对一组目标代码文件运行链接器。
- prog 比.o大,因为还包含了启动和终止程序的代码。
- objdump -d prog。可执行文件也可以进行反汇编。
- 与机器代码文件mstore.o反汇编的代码几乎完全一样。但也有不同点:
- 重定位:链接器将这段代码地址移到了一段不同的地址范围中。
- 链接器填上了mult2的地址:链接器的任务之一就是为函数调用找到匹配的函数的可执行代码的位置。
- 多行nop。(为了让下一个函数的地址是16的倍数?)存储性能高。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15...
0000000000000739 <mult2>:
739: 48 89 f8 mov %rdi,%rax
73c: 48 0f af c6 imul %rsi,%rax
740: c3 retq
0000000000000741 <multstore>:
741: 53 push %rbx
742: 48 89 d3 mov %rdx,%rbx
745: e8 ef ff ff ff callq 739 <mult2>
74a: 48 89 03 mov %rax,(%rbx)
74d: 5b pop %rbx
74e: c3 retq
74f: 90 nop
...
- 与机器代码文件mstore.o反汇编的代码几乎完全一样。但也有不同点:
寄存器(Register)
- 整数寄存器x86-64 Integer Register

- 有的用来存储地址/整数数据;有的记录某些重要的程序状态;有的用来保存临时数据(参数、局部变量、函数返回值)
- %rsp比较特殊,我们不能随意改变,因为这里面存的是栈指针,指向当前栈顶(stack top)
- 1word = 2bytes。quad word:4字、8bytes、64位;long word:2字、4Bytes、32bit;word:1字、2Bytes、16bit;Bytes:1字节、8bit
- 程序计数器:通常写作PC,x86-64中用%rip表示(instruction pointer)。给出将要执行的下一条指令再内存中的地址。不是我们可以正常访问的寄存器(但也有一些技巧可以获得),它只是告诉我们程序执行到了哪里。
- 条件码寄存器:保存最近执行的算术或者逻辑指令的状态信息。(用于实现if等条件控制语句)
- 一组向量寄存器可以存放1或多个整数或浮点数值
- %rax和%eax和%ax的关系
- 立即数(immediate)
- Example:$0400,$-533
- Like C constant ,but prefixed with $
- encoded with 1,2 or 4 bytes
- 寄存器(register):上图十六个整形寄存器之一
- example:%rax,%r13
- but % rsp reserved for special use
- Others have special uses for particular instructions
- 用ra表示任意寄存器a;R[ra]、Reg[ra]表示它存的值
- 内存(memory):x consecutive bytes of memory at address given by register
- example:(%rax)
- various other “address mode”
- Mb[Addr]:表示对存储在内存中开始的b个字节值得引用,通常省略b。或者mem[addr]。(因此mem[reg[addr]] 就是用寄存器存储的值作为地址进行寻址)
数据格式
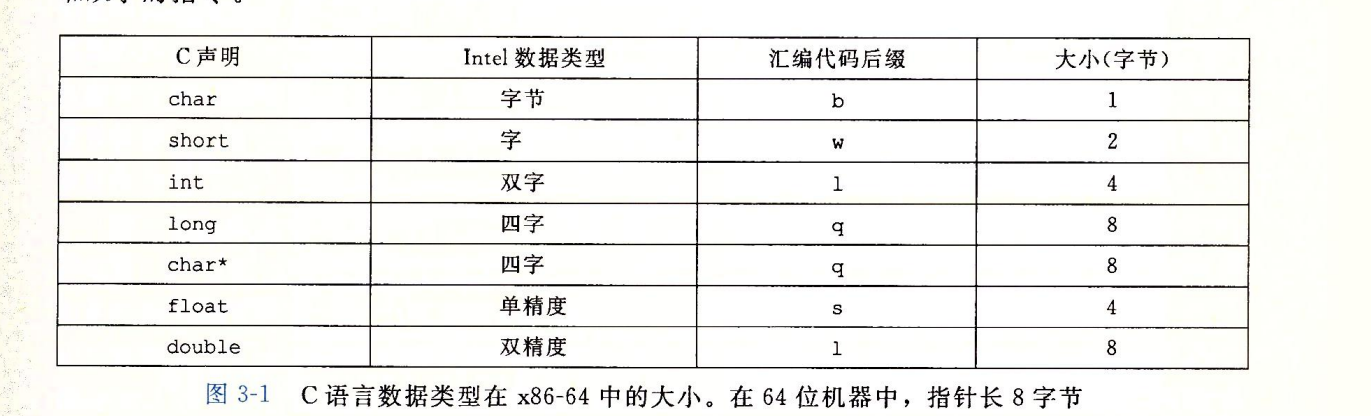
- mov后缀
- movb:传送字节
- movw:传送字
- mobl:传送双字(long word 32位被称为长字)
- movq:传送四字
- 1字 = 2bytes。1byte=8bit
内存地址编码方式
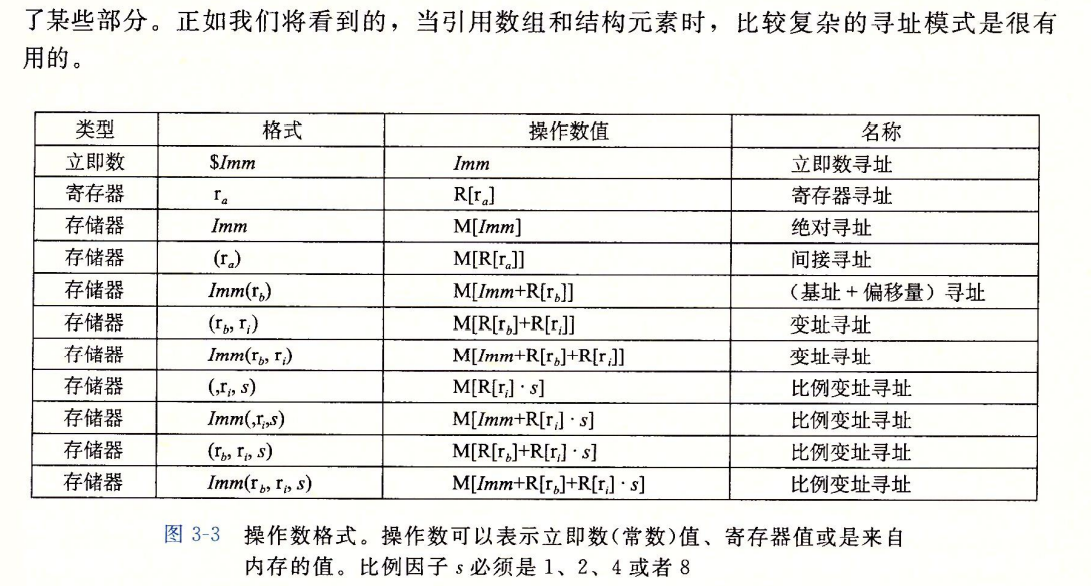
- Simple Memory addressing modes。
- normal:(R) —- mem[reg[R]]
- 寄存器R中存的就是内存地址
- movq (%rcx),%rax :%rax = *(%rcx)
- displacement:D(R) —- mem[reg[R]+D]
- R中存储内存基地址,向高偏移D个Bytes,得到目标地址
- movq 8(%rbp),%rdx :%rdx = *(%rbp+8)
- normal:(R) —- mem[reg[R]]
- Complete Memory Addressing Modes
- most genernal form : D(Rb,Ri,S) —- mem[reg[Rb] + S*reg[Ri] + D]
- 数组引用常见形式
- D:偏移量。1 / 2 / 4 Bytes
- Rb:该寄存器存储目标内存基地址
- Ri:下标寄存器
- Scale:比例。1 / 2 / 4 / 8 Bytes。数组元素的数据类型大小。
- special cases
- (Rb,Ri) —- mem[reg[Rb]+reg[Ri]]。
- D(Rb,Ri) —- mem[reg[Rb]+Reg[Ri]+D]
- (Rb,Ri,S) —- mem[reg[Rb]+S*reg[Ri]]
- most genernal form : D(Rb,Ri,S) —- mem[reg[Rb] + S*reg[Ri] + D]
- 附:
- 用ra表示任意寄存器a;R[ra]、Reg[ra]表示它存的值
- Mb[Addr] 表示对存储在内存中开始的b个字节值得引用。通常省略b
- 基址寄存器rb和变址寄存器ri必须都是64位寄存器。(因为64位系统)
指令类
- 在这些指令中,有很多负责和生成1、2、4、8字节值。当这些指令以寄存器为目标时,对于生成小于8字节结果的指令,寄存器中剩下的字节会怎么样。对此有如下规则
- 生成1byte和2bytes的指令会保持剩下的高位字节不变。
- 生成4bytes的指令会把高位4个bytes置为0。
ATT与Intel区别
- ATT与Intel格式区别(终于解决了我之前看学c++时看反汇编的迷惑)
- ATT:用于gcc、objdump
- Intel:用于微软、Intel
- Intel代码省略指示大小的后缀q。(ATT:pushq;Intel:push)
- Intel代码省略寄存器名字前面的%。(ATT:%eax;Intel:eax)
- 二者用不同方式描述内存位置
- ATT:(%rbx) 使用%rbx寄存中的内容作为addr去寻址
- Intel:QWORD PTR [rbx]
- 多操作数时,顺序相反。
MOV类:数据传送指令
- mov的src和dst
- https://stackoverflow.com/questions/2397528/
- mov dest, src称为 Intel syntax 。 (例如mov eax, 123)
- mov src, dest称为 AT&T syntax 。 (例如mov $123, %eax)
- 包括GNU汇编器在内的UNIX汇编器使用AT&T语法,所有其他x86汇编器都使用Intel语法
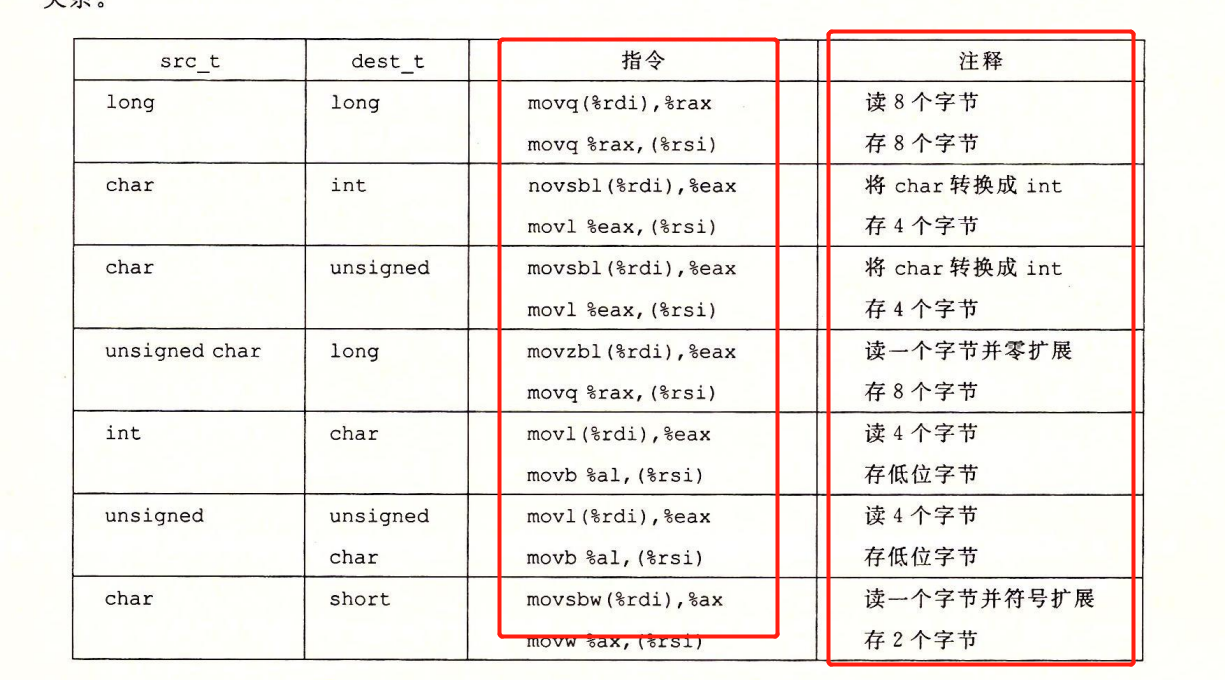
- mov指令的两个操作数src和dst必须同样大小(没使用movz类和movs类时)
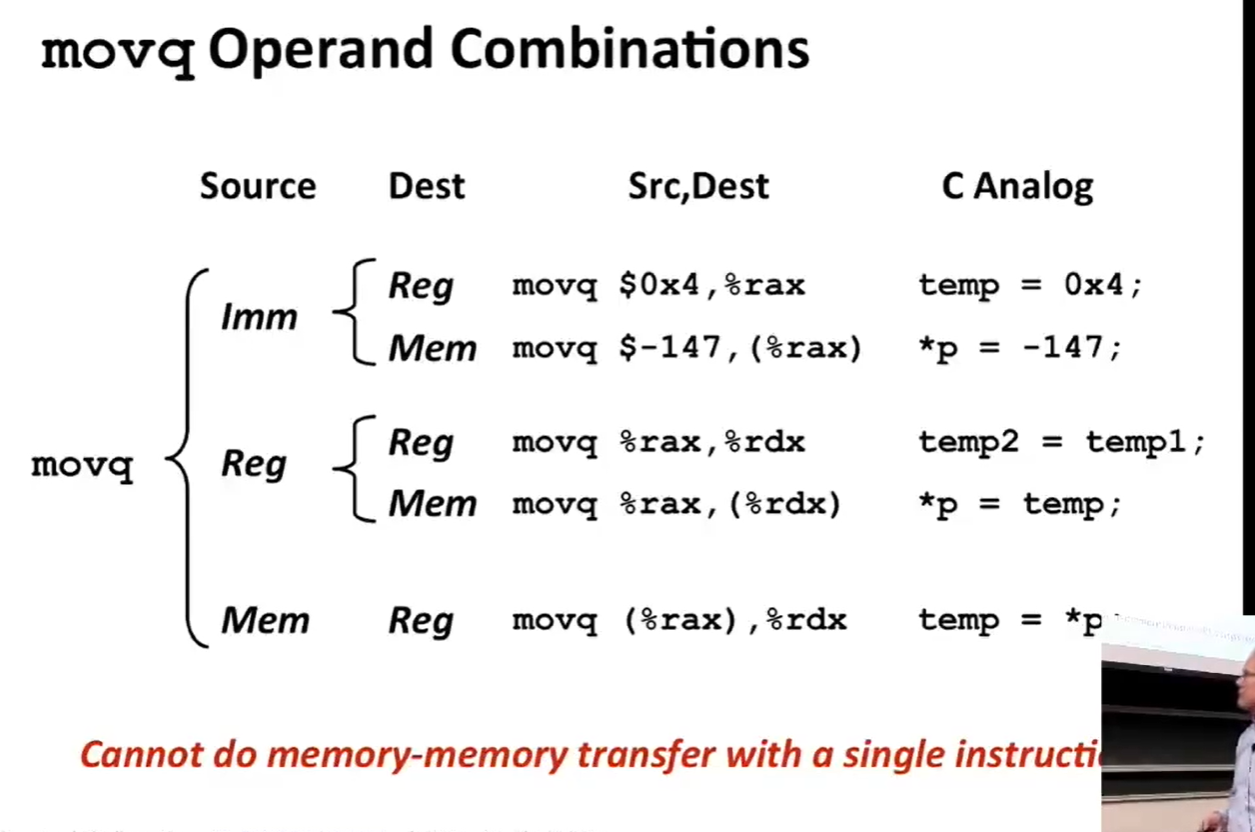
- 机器不允许直接将数据从一个内存位置复制到另一个内存位置。需要使用两个指令。
- 先将内存的值移到寄存器中
- 再将寄存器中的值移到内存中
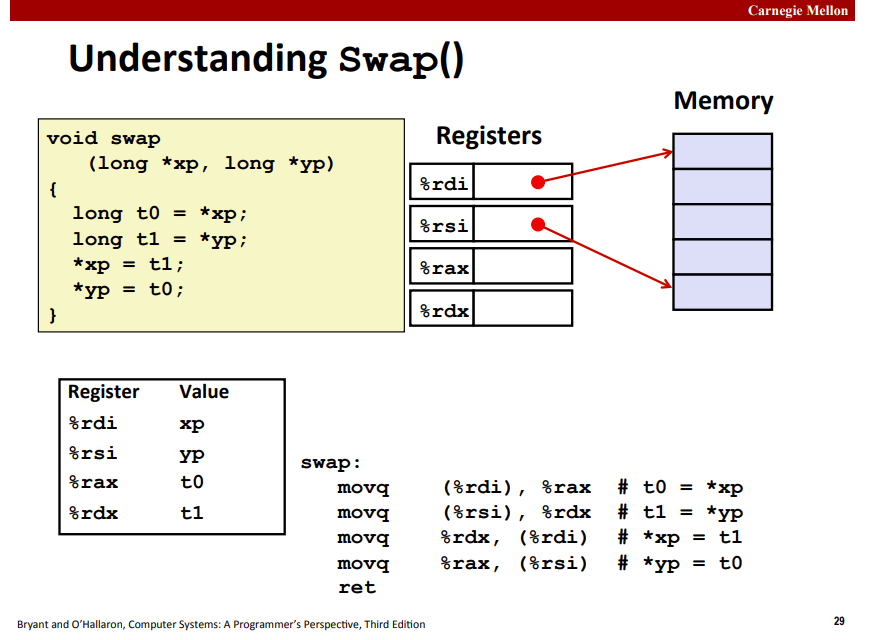
- understanding swap
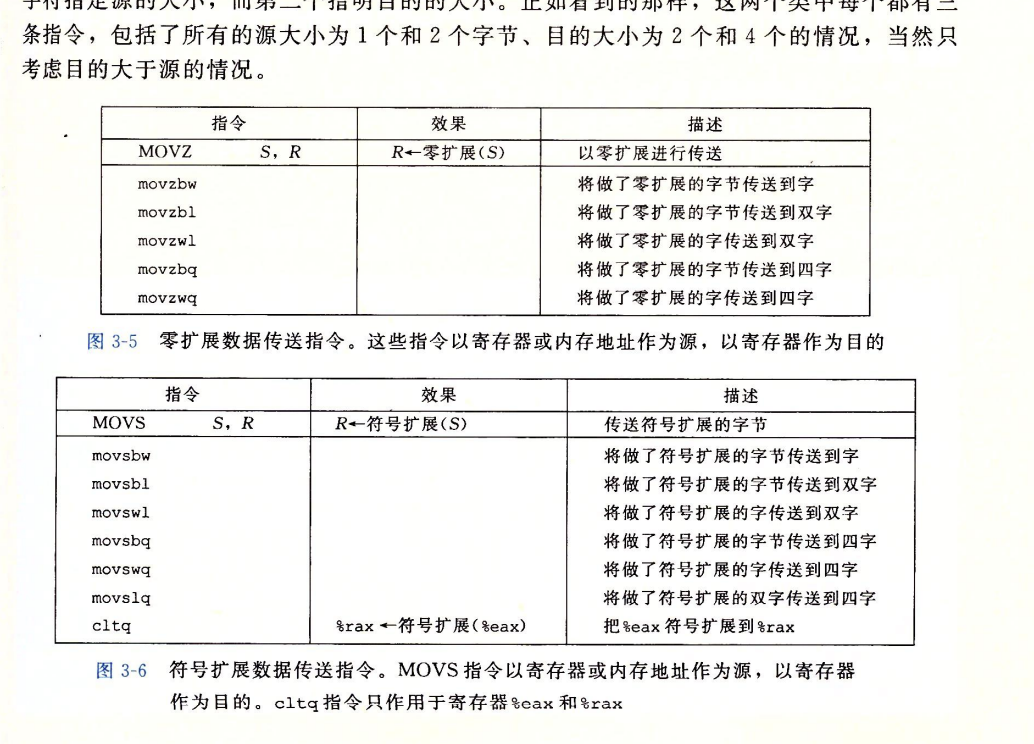
MOVS类 MOVZ类
- MOVZ类:把目的中剩余的字节填充为0
- MOVS类:把目的中剩余的字节通过符号扩展填充
- MOVS和MOVZ都是以寄存器或内存地址作为src,寄存器作为dest
- 例子


- 三连错。。啧啧
- 练习题3.2

1
2
3
4
5
6
71. movl, 因为%eax为2字4bytes32位寄存器
2. movw, 因为%dx为1字16位寄存器
3. movb, 因为%bl为1byte寄存器
4. movb, 因为%dl为1byte寄存器
5. movq, 因为%rax为4字64位寄存器
6. movw, 因为%dx为1字16位寄存器
从题中可以看出一个重要特性,x86-64 中的内存引用总是用四字长寄存器给出,例如 %rax,哪怕操作数只是一个字节、一个字或是一个双字
- 练习题3.3

1
2
3
4
5
6
71. x86-64中的内存引用总是用4字长64位寄存器给出,如%rax。所以改为movb $0xF,(%rbx)
2. %rax是64位寄存器,应当用movq %rax ,(%rsp)
3. movw (%rax),4(%rsp)。mov的src和dst不能同时都是地址
4. 没有寄存器叫%sl
5. immediate不能作为dst
6. 64位%eax和32位%rdx大小不一致。改为movl %eax,%edx;或者movq %rax,%rdx
7. %si是2字16bytes寄存器,应当改为 movl %si,8(%rbp) 或者 movb %sil,8(%rbp) - 练习题3.4

- 注意点
- movz、movs指令以寄存器或内存地址作为源,以寄存器作为目的
- 发生的是有符号扩展还是无符号扩展,也即使用的是movs类还是movz类,是看源操作数是什么,也就是由将发生符号扩展(类型转换)的数本身是什么类型决定的,而不是看目的数是什么类型
- 注意点
lea:加载有效地址
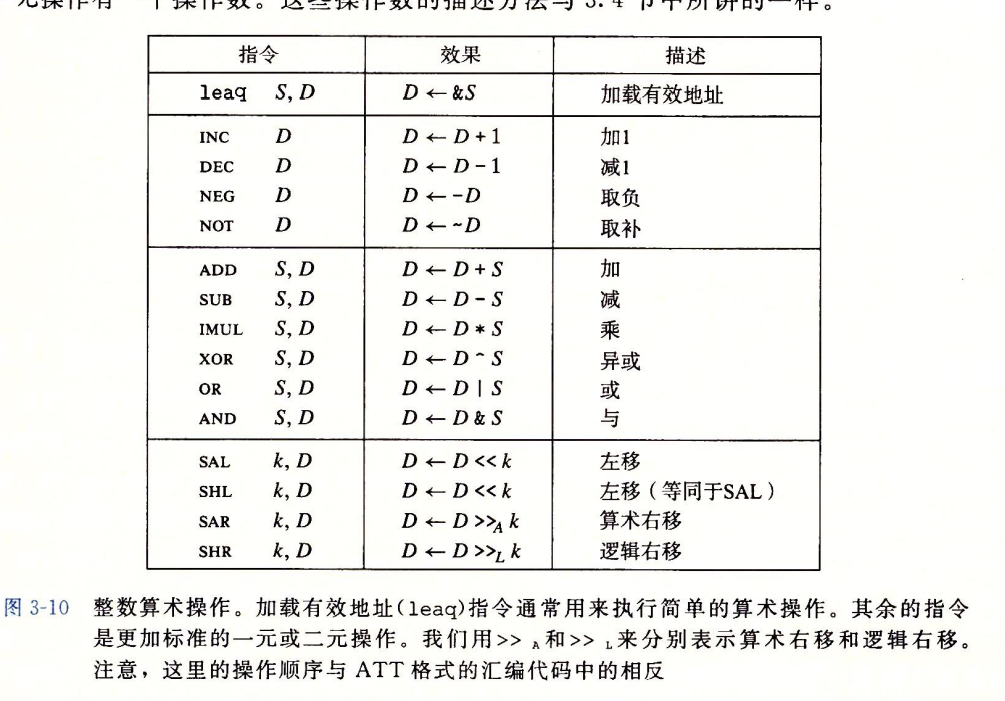
- lea指令:load effective address。将src表达的地址值赋值给Dst
- leaq Src Dst(AT&T syntax)
- src is address mode expression andset dest to address denoted by expression
- 第一个操作数src看上去是一个内存引用,但实际上根本没有引用内存。该lea指令不是从指定的内存地址读取数据,而是将这个(地址表达式)作为结果写入dest寄存器。
- 作用:
- 计算地址 p = &x[i]
- 计算数值 x + k*y
- 例子
1
2
3
4
5
6
7long func(long x)
{
return x*12;
// convert to asm by complier
leaq (%rdi,%rdi,2),%rax :reg[%rax] = reg[%rdi]+reg[%rdi]*2 = 3 * %rdi
salq $2 , %rax :%rax << 2 = %rax * 4 = 12 & %rdi
}
- leaq Src Dst(AT&T syntax)
- 例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24long arith(long x,long y,long z)
{
long t1 = x+y; t1 :
long t2 = z+t1; t2 :
long t3 = x+4;
long t4 = y*48;
long t5 = t3+t4;
long rval = t2*t5;
return rval;
}
arith:
leaq (%rdi,%rsi),%rax ---> %rax = %rdi+%rsi // t1
addq %rdx,%rax ---> %rax += %rdx // t2
leaq (%rsi,%rsi,2),%rdx ---> %rdx = 2*rsi + %rsi = 3*%rsi
salq $4 , %rdx ---> %rdx <<= 4 // t4
leaq 4(%rdi,%rdx),%rcx ---> %rcx = %rdx + %rdi + 4 // t5 t3 = %rdi + 4
imulq %rdx,%rax ---> %rax = %rax * %rcx // rval
ret
%rdi x
%rsi y
%rax t1 t2 val
%rdx t4
push、pop:压入、弹出栈数据
- 栈底:高地址。栈顶:低地址。栈由高地址向低地址增长。栈底在上,就是栈顶向下方向增长;栈底在下,就是栈顶向上增长。
- 栈指针:%rsp。栈顶元素的地址是栈中元素最低的。
- %rsp中的指针指向的内存空间有内容,该指针指向的是栈顶地址最低的归本栈帧(有内容)的内存单元
- pushq:pushq %rbp
1
2subq $8,%rsp
movq %rbp,(%rsp) - popq:popq %rax
1
2movq (%rsp),%rax
addq $8,%rsp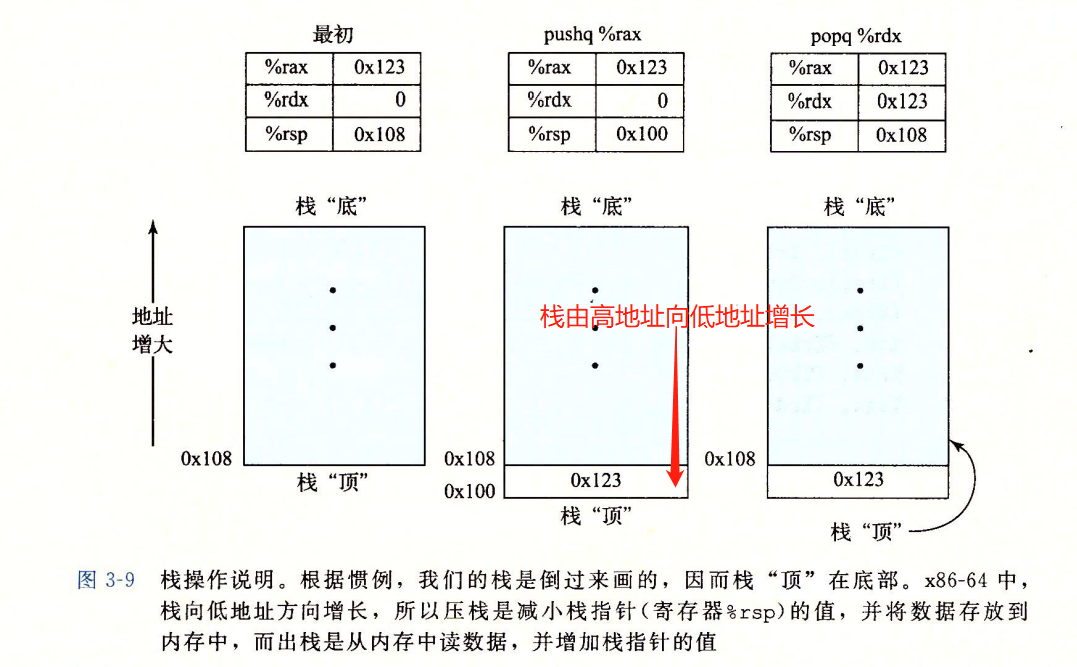
移位
- 左移不分算数、逻辑;右移分算数、逻辑
1
2
3
4salq src dst dst = dst << src
shlq src dst dst = dst << src // 和上一行相同,两者作用一样 都是向左移动。右边填0;只有右移操作需要区分有符号数无符号数。
sarq src dst dst = dst >> src // 算数右移
shrq src dst dst = dst >> src // 逻辑右移
其他指令

addq,subq,imulq,salq,sarq,shrq,xorq,andq,orq等,都是src在前,dest在后。
1
2
3
4
5
6addq src dst dst = dst + src
subq src dst dst = dst - src
imulq src dst dst = dst * src
xorq src dst dst = dst ^ src
andq src dst dst = dst & src
orq src dst dst = dst | srcxorq %rdx,%rdx作用
- 将%rdx置0;等价于movq $0,%rdx
- xorq版本只用3个Bytes。movq版本需要7个Bytes
- 其他将%rdx置0的方法都依赖于该属性:任何更新寄存器低4Bytes的的操作,都会将高位Bytes置为0。因此,可以使用 xorl %edx,%edx(2Bytes) ;或者 movl $0,%edx(5Bytes)
乘法:(i)mulq
- imulq src,dst :dst = src*dst
- imulq S:R[%rax] = R[%rax]*S
- 存储128位乘积时需要两次mov。
- movq %rax,(%rdi)
- movq %rdx,8(%rdi)
除法:(i)divq
- 被除数:%rdx AND %rax
- 余数:%rdx
- 商:%rax
例子


- cqto:隐含读出%rax的符号位,并复制到%rdx的所有位
- 无符号除法(divq)时,不用cqto,而是一般先将%rdx设置为0,其他我认为都一样。
涉及到内存(存储器)才有大小端问题,寄存器里没有大小端呀,顶多叫高位字节 低位字节
Control
information about currently executing program
- temproary data(临时量):
- %rax…
- location of runtime stack:
- %rsp(栈指针):指向当前栈顶
- location of current code control point
- %rip(当前程序运行到哪里):给出将要执行的下一条指令再内存中的地址。不是我们可以正常访问的寄存器(但也有一些技巧可以获得),它只是告诉我们程序执行到了哪里。
- 条件码 Single bit register
- 他们在算数过程中是如何被设置的?如 addq Src,Dest <-> t=a+b。他们的设置可以被认为是算数运算的副作用。
- CF:(unsigned) t<(unsigned) a
- ZF:t=-0
- SF:t<0(signed)
- OF:a>0&&b>0&&t<0 || a<0&&b<0&&t>=0
- lea指令不会设置这些标志位,
Explicitly Setting: Compare
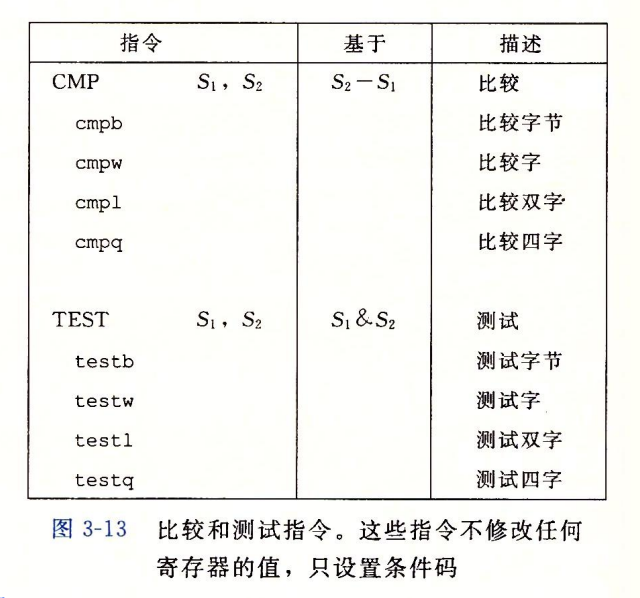
- cmpq b,a(cmpq Src2,Src1)
- like computing a-b without setting destination
- CF:最高位进位。(当src为unsigned时,该寄存器有意义)
- ZF:if a==b
- SF:if(a-b)<0 (as signed)
- OF:(a>0&&b<0&&(a-b)<0) || (a<0&&b>0&&(a-b)>0)
Explicitly Setting: Test
- testq b,a(testq Src2,Src1)
- like computing a&b without setting destination
- sets condition codes based on value of a&b(根据a&b的结果设置条件码)
- useful to have one of operands be a mask(适用于有一个操作数是掩码的时候)
- ZF set when a&b==0
- SF set when a&b<0
- 典型用法:testq %rax,%rax :测试%rax是>0 <0 还是=0。
- 该指令时有 CF=0,OF=0。
- %rax=0时,也即%rax&%rax==0时,才有ZF=1;否则ZF=0。
- %rax>0时,%rax&%rax>0,有SF=0;%rax<0时,%rax&%rax<0,有SF=1.
Condition Code 使用
根据条件码组合,将一个字节设置为0或者1
可以条件跳转到程序的某个其他部分
可以条件传送数据
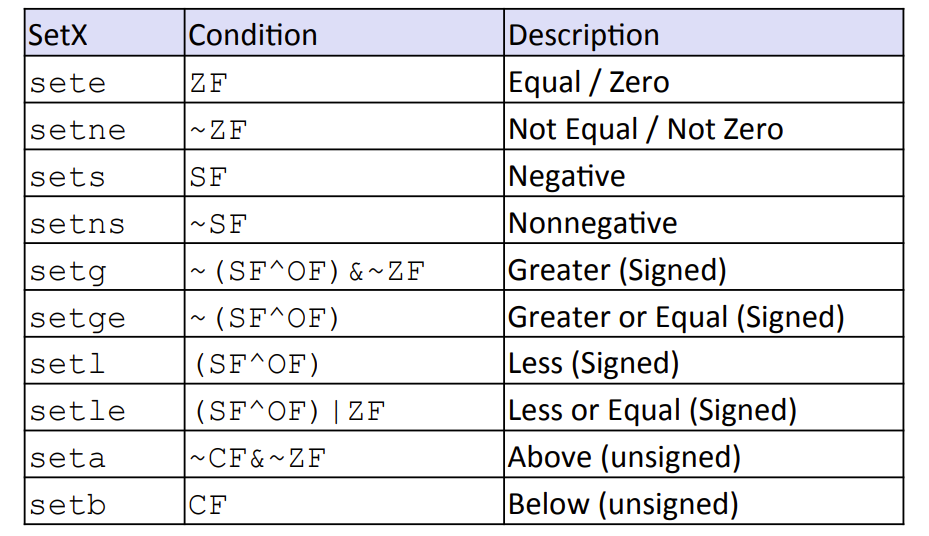
SetX指令
set后面跟的后缀符号指的是所考虑的条件码的组合,而非什么操作数大小。当setX相对应的条件码组合为1时,将所操作的寄存器低位byte赋值为1。
根据条件码设置某一寄存器的最低字节,寄存器的其他高位bytes不变。

1
2
3cmpq b,a // Compare a:b t = a - b
setX %al
movzbl %al,%eax有符号数比较的set指令
- sete : ZF
- a=b时,t=a-b=0
- setl : SF^OF
- OF=0(未发生signed溢出)
- SF=1:t=a-b<0 —> a<b
- SF=0:t=a-b>=0 —> a>=b
- OF=1(发生signed溢出)
- SF=1:t=a-b<0 —> a>0,b<0 发生上溢
- SF=0:t=a-b>0 —> a<0,b>0 发生下溢(下溢最夸张也就到1,到不了0:Tmin-Tmax)。有a<b
- 也即SF^OF代表刚刚的算术结果是个负数
- OF=0(未发生signed溢出)
- 所以有符号的其他比较基于SF^OF和ZF的组合
- setge : ~(SF^OF)
- setg : ~(SF^OF)&(~ZF)
- setle : (DF^OF)|ZF
- sete : ZF
无符号数比较的set指令
- sete : ZF
- a=b时,t=a-b=0
- setb : CF
- CF:进位标志。CF = (最高位是否向更高发生进位) ^ (加法0 减法1)。(计算规则为采用补码,也即减法时需要先将-x变为+(-x)补)
- 例子
1
2
3
4
5
6
7
8
9
10
11
12au = 101 = 5
bu = 111 = 7 -bu -> 补码 = ~bu+1 = 001
au - bu =
101
- 111
-------
101
+ 001
-------
110 = 补码意义下的-2,无符号数意义下的6
由上述知: CF = 0^1 = 1
判断发生溢出,符合预期
- 所以无符号数的set比较基于CF和ZF的组合
- seta: ~CF & ~ZF
- setbe: CF|ZF
- setae: ~CF
- setb: CF
- sete : ZF
复习au-bu:计算机中的无符号数减法如何进行
- 也是按照有符号数补码的计算规则进行(计算机内部就都是补码运算,只不过整数的补码等于其本身,详情间补码原码反码运算博客)
- 计算出(-bu)的补码,在与au相加,也即 au + (-bu)补。其中(-bu)补 = ~(bu)原+1。(又对于无符号数bu原=b真值)
- 但是-bu的类型还是无符号数!!!不是有符号数。他只是在按照规则进行位级操作而已,对位的意义如何解释是由-bu的类型决定的,而-bu还是无符号数。
1
2
3
4
5
6
7
8
9unsigned int x = 1;
cout<<x<<endl;
cout<<-x<<endl;
cout<<abi::__cxa_demangle(typeid(x).name(),0,0,0 )<<endl;
cout<<abi::__cxa_demangle(typeid(-x).name(),0,0,0 )<<endl;
1
4294967295
unsigned int
unsigned int
练习题
cmpl testl setl 的l所指的东西不一样。前两者指的是操作数的大小。setl的l指的是要进行less比较。
条件跳转
请见p145-146
跳转指令
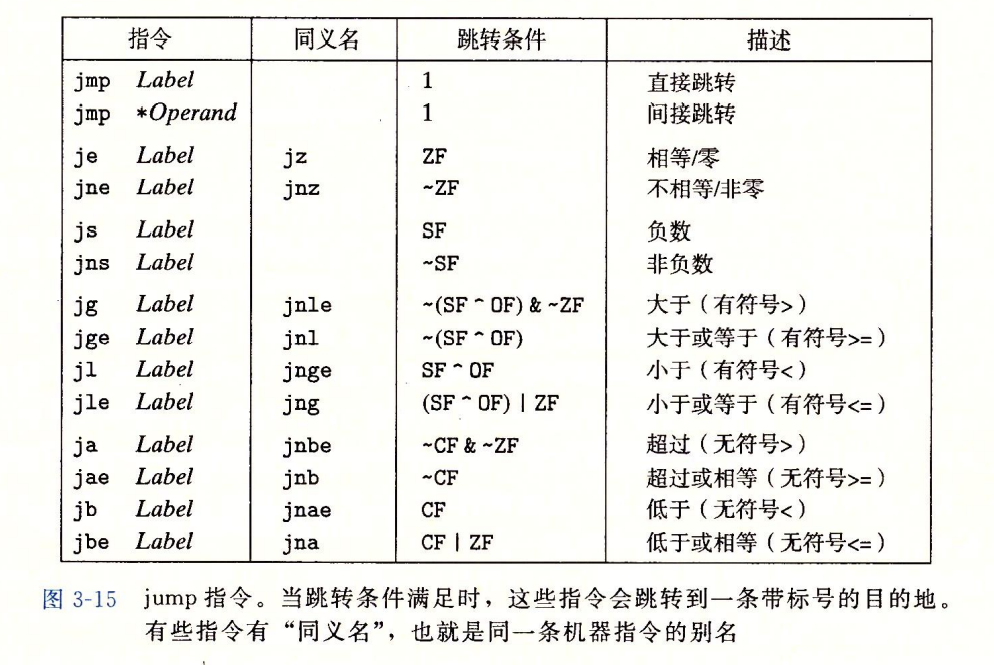
- jmp:无条件跳转
- 直接跳转:jmp *%rax。以%rax的值作为跳转目标
- 间接跳转:jmp *(%rax)。以%rax的值寻址,从内存中读出跳转目标
- 条件跳转:根据条件码的组合跳转
- 只能直接跳转
- 跳转指令中,执行PC相对寻址时,程序计数器的值是jX跳转指令后面的那条指令的地址,而不是jX本身的地址

- ```bash
test %rax,%rax
jg .L3
jg作用:当%rax>0时,跳转到.L3
jg:(SF^OF)&ZF
SF^OF:由test%rax,%rax知一定未溢出。故SF^OF代表运算结果为负数
ZF:test计算结果为01
2
3
4
5
6
7
8
9
10- 练习题
- 
##### 条件控制实现条件分支
- C的if-else
```c++
if(test-expr)
then-statement
else
else-statement
- 汇编形式
1
2
3
4
5
6
7
8t = test-expr;
if(!t)
goto false;
then-statement
goto done;
false:
elses-statement
done;
分支预测
抄书 加深下印象。解决了计组里的疑惑。
处理器通过流水线获得高性能,这种方法通过重叠连续指令的步骤来获得高性能。为此,就要实现能确定要执行的指令的顺序,这样才能保证流水线中充满待执行的指令。当机器遇到条件跳转(分支)时,只有当分支条件求值完成后,才能决定分支往哪里走。处理器采用非常精密的分支预测逻辑来猜测每条跳转指令是否会执行。只要他的猜测还比较可靠(现代微处理器设计试图达到90%以上的成功率),指令流水线就会充满指令。另一方面,错误预测一个跳转,要求处理器丢掉它为该跳转指令后所有指令已做的工作。然后再开始用从正确位置处起始的指令去填充流水线。正如我们看到的,这样一个错误预测会招致很严重的惩罚,浪费大约15~30个时钟周期,导致程序性能严重下降。
惩罚
惩罚分析

- A. Tavg = (1-p)*Tok + p*(Tok+Tmp) = Tok + pTmp
可预测时:p=0;Tok = 16
随机时:31 = Tok + pTmp = 16 + 0.5*Tmp;Tmp = 30。 - B. Trun = Tok + Tmp = 46

条件传送指令
- 一定情况下,基于条件数据传送的代码会比基于条件控制转移的代码性能要好。
用条件传送实现条件分支
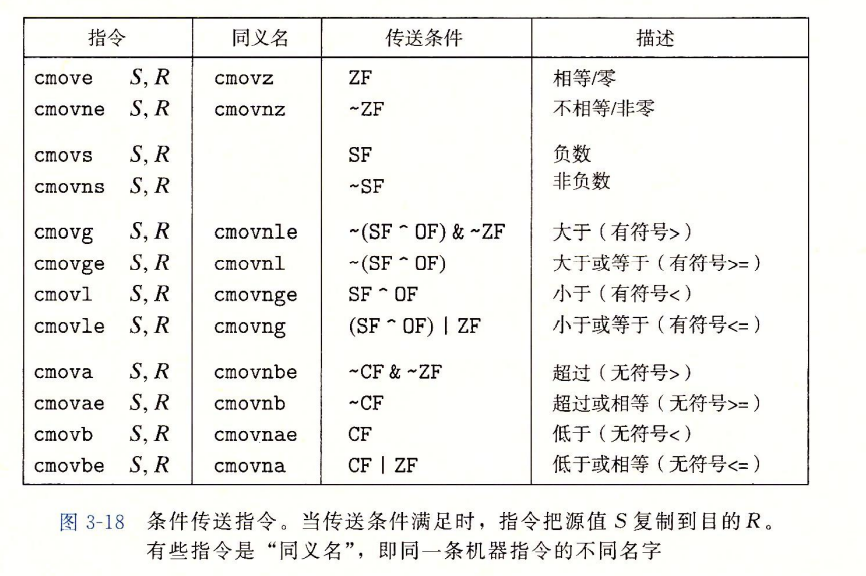
- 与setX和jX一样,取决于条件码的组合。
- 与条件跳转不同,处理器无需预测测试结果就可执行条件传送,处理器只是读源值,检查条件码,然后要么更新目的寄存器,要么保持不变。
- 对比
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17v = test-expr ? then-expr:else-expr
条件控制转移
if(!test_expr)
goto false;
v = then-expr
goto done;
false:
v = else-expr
done:
条件传送代码
v = then-expr
ve = else-expr
t = test-expr
if(!t) v= ve // 该条语句用条件传送实现,只有当测试条件t不满足时,才mov - 当对then-expr和else-expr求值会产生错误条件或者副作用时,不能采用条件传送。
- 使用条件传送也不总是会提高代码效率。如果then-expr或者else-expr需要大量计算,那么相对应的条件不满足时,所对应工作就白费了。编译器必须考虑浪费的计算和由于分支预测错误所造成的性能处罚之间的相对性能。说实话,编译器并不具有足够信息来做出可靠决定;例如,他们不知道分支会多好的遵循可预测的模式。我们对gcc的实验表明,只有当两个表达式都很容易计算时,例如分支表达式分别都只是条加法指令,他才会使用条件传送。根据我们的经验,即使许多分支预测错误的开销会超过复杂的计算,gcc还是会使用条件控制转移。
- 总的来说,条件数据传送提供了一种条件控制转移来实现条件操作的替代策略,他们只能用于受限情况,但还是很常见的,且与现代处理器运行方式更契合。
- 练习
- do-while



- while



- for



switch
- 使用跳转表是一种非常有效的实现多重分支的方式
- switch语句:根据一个整数(无符号数)的索引值进行分支跳转。
- 跳转表
- 一个数组,其中的每一个元素都是一个代码段的起始地址
- 根据提供的索引值i会从跳转表中确定目标代码段地址,执行一个跳转。
- 优点:执行switch语句的时间与case的数量无关。
- GCC会根据case的数量和值的情况来决定如何翻译switch语句。case数量多且值跨度小时,翻译为跳转表方式。
- switch语句例子


- 跳转表

- 跳转表的地址数组索引应当尽量从0开始,所以翻译成汇编时会有相应的偏置值相加减。quad 表示这里需要个8bytes的值。
- 课堂例子

- 练习题

Control 小结
