Procedure
Mechanisms in Procedures

Procedure 过程
过程:一种很重要的抽象,提供了一种封装代码的方式,用一组参数和一个返回值实现了某种功能,隐藏了行为的具体实现。
不同语言中,过程形式多样:函数、方法、子例程、处理函数,
假设过程P调用过程Q,Q执行后返回P。这些动作包括以下机制.
传递控制:passing control
- 进入过程Q时,程序计数器(PC/%rip)必须被设置为:过程Q代码的起始地址。(过程Q的地址)
- 从过程Q返回时,程序计数器必须被设置为:P中调用Q这句代码
call Q的下一行代码的地址。(P中的)
传递数据:passing data
- P必须能向Q提供一个或多个参数
- 参数<=6个,通过寄存器传递
- 参数>6个,通过将P要传递给Q的参数(6个开外的那些)压入过程P的栈帧来传递。
- Q必须能向P返回一个值(一般用%rax返回)
- P必须能向Q提供一个或多个参数
分配和释放内存:memory management
- Q可能需要为局部变量分配空间,在返回时,又必须释放这些空间。(移动%rsp)
Stack Structure 运行时栈
- 重要图
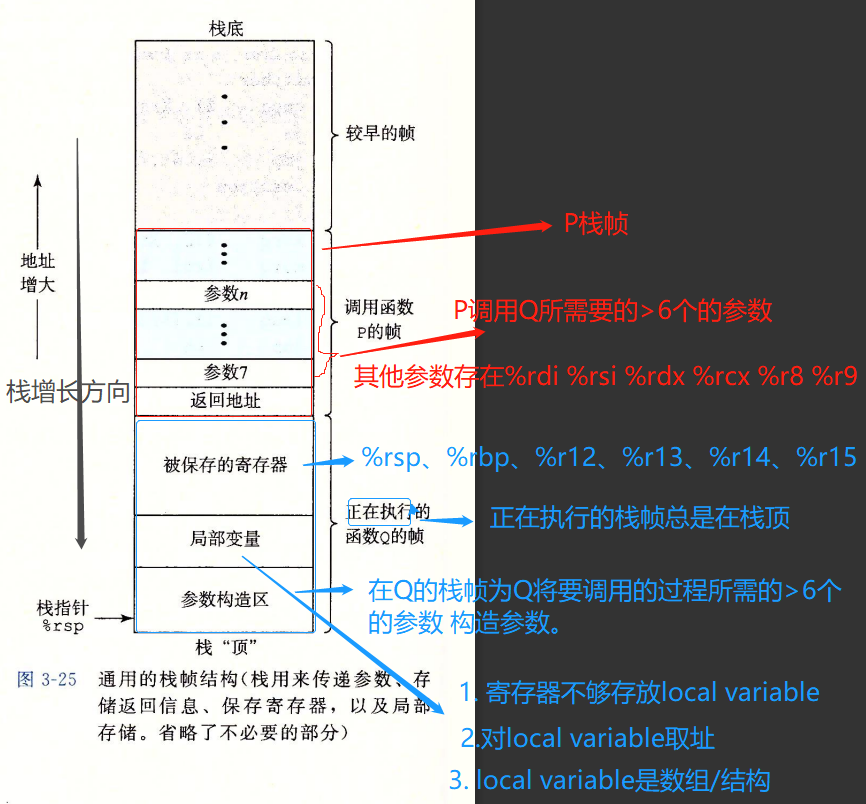
纠正:被保存的reg中的%rsp换成%rbx - 栈由高地址向低地址增长;**%rsp时刻指向栈顶元素**;pushq、popq将数据存入、弹出栈;%rsp减小可以为没指定初始值的数据在栈上分配空间;也可通过增大%rsp释放空间。
- x86-64过程需要的存储空间超过寄存器能存放的时,就会在栈上分配空间,分配的空间称为栈帧。当前在运行的栈帧总是在栈顶。
- P调用Q时,会将Q过程结束后的返回地址(Q返回后,P过程继续执行的地址)压入栈中。我们将这个返回地址视作P栈帧的一部分。(因为这个返回地址说P过程代码的地址,存放的是与P相关的状态)
- Q代码会扩展当前栈的边界,分配它的栈帧所需的空间。
- 这个空间中,它可以保存寄存器的值、分配局部变量空间、为调用过程设置参数。
- 大多数栈帧都是定长的,在过程的开始就分配好了。但是也有些过程需要变长的帧
- 3.10.5。比如P调用Q过程时,Q需要>6个参数,那么P就需要将多出的参数存入P自己的栈帧中。如果<=6个,那么就只需要用寄存器传参数即可。
- 实际上,许多函数甚至不需要栈帧
- 当所有局部变量都可以保存在寄存器中,且该函数不会调用其他函数。
- 栈是所有过程的集合,栈帧是一个过程,在栈顶的栈帧是当前正在执行的过程。
- 也意味着,代码中的其他(过程)函数,无论有多少,在该时刻都被冻结,任何时刻运行的只有一个函数(过程)(位于栈顶的栈帧)
传递控制 Passing Control
大体来说,就是传递控制,就是适当的改变PC/%rip,以控制该执行哪条指令。并在此过程中会用到栈来存储%rip应该变成的地址。
控制从P转移到Q:将PC设置为Q的起始地址即可
控制从Q返回到P:将PC设置为P中call Q的下一条指令的地址。
call Q :过程调用
- (pushq A)将地址A压入栈中。紧跟在call指令后面的那条指令的地址。
- (%rip = Q_addr)将PC设置为Q的起始地址
ret :从过程调用中返回
- (popq)从栈中弹出地址A
- (%rip=A)把PC设置为A
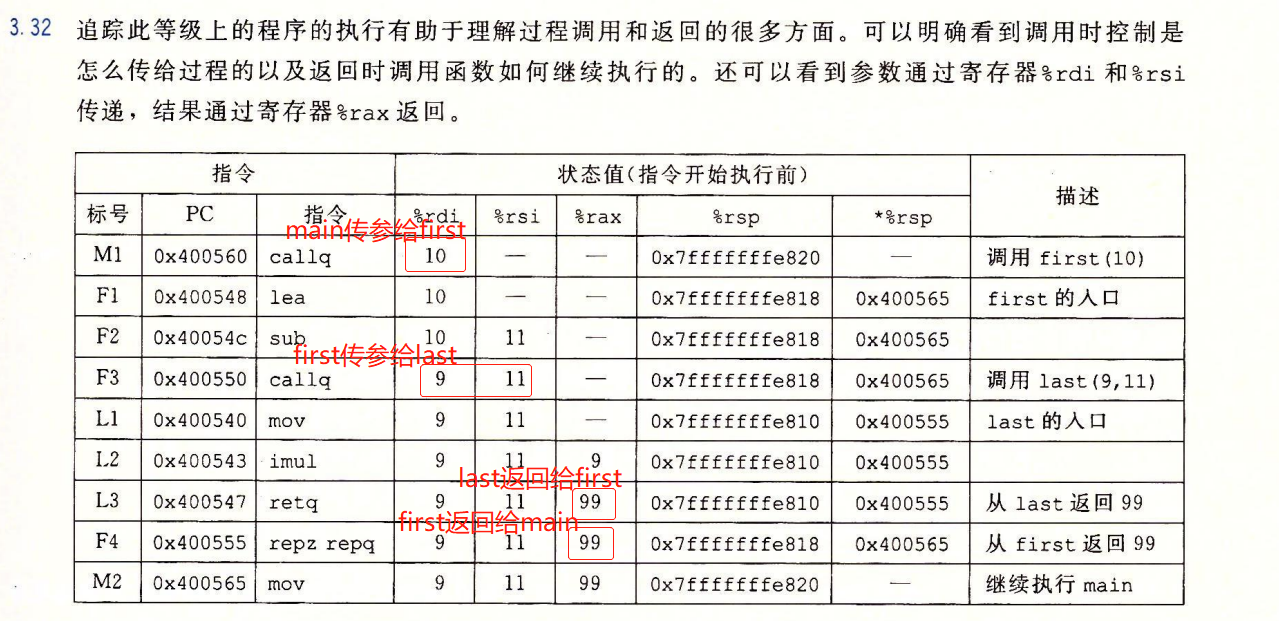
例子1
1
2
3
4
5
6
7
8
9
10begin of fun mulstore
0x0000000000400540 <mulstore>
400540: 53 push %rbx
400541: 48 89 d3 mov %rdx,%rbx
...
40054d: c3 retq
...
main
400563: e8 d8 ff ff ff callq 400540<mulstore>
400568: 48 8b 54 24 08 mov 0x8(%rsp),%rdx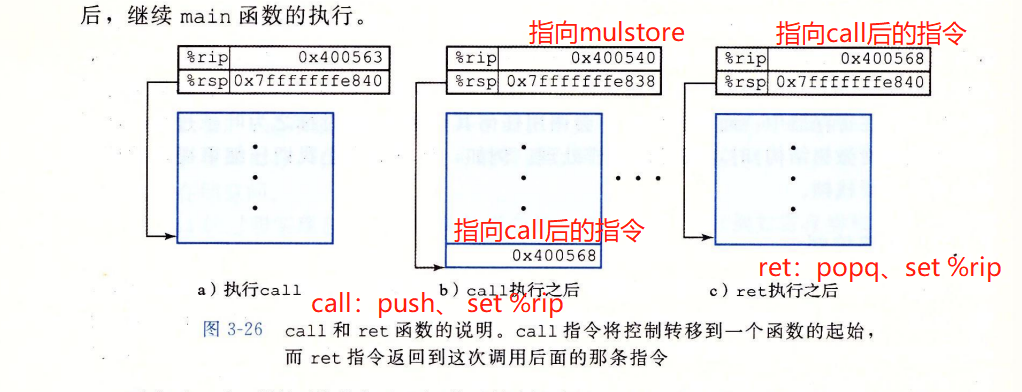
练习


传递数据 Passing Data
Managing local data
- 当调用一个过程时,除了把控制传递给他,并在返回时再传递回来时;还可能包括把数据作为参数传递,而从过程返回害有可能包括返回一个值。
- 过程间的数据大部分通过寄存器传递。
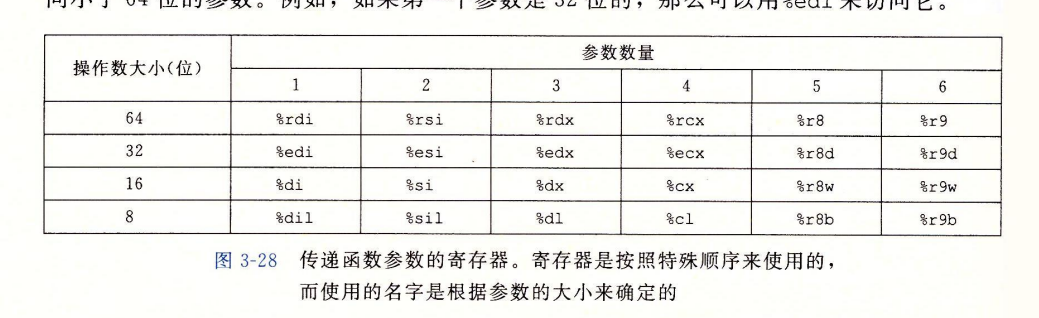
- 如P调用Q,当参数的个数大于6个之后,就需要Q在自己的栈帧中为要传递给q的参数构造参数,称为参数构造区。当构造完成后,即可进行call Q。
- 例子

Local Storage On Stack 栈上的局部存储
- 某些时候,过程的局部数据必须存放在内存中(虚拟内存中的stack)
- 寄存器数量不够,无法存储所有本地数据。
- 对一个局部变量使用取址&,因此必须为他产生一个地址
- 某些局部变量时数组或结构,因此必须通过数组或结构引用被访问到。
- 一般来说,过程通过减小%rsp指针在战胜分配空间,分配的结果作为栈帧的一部分,如重要图中的”局部变量区”。
- 例子


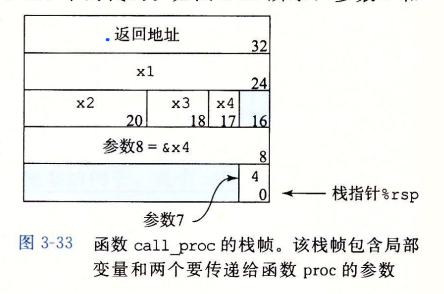
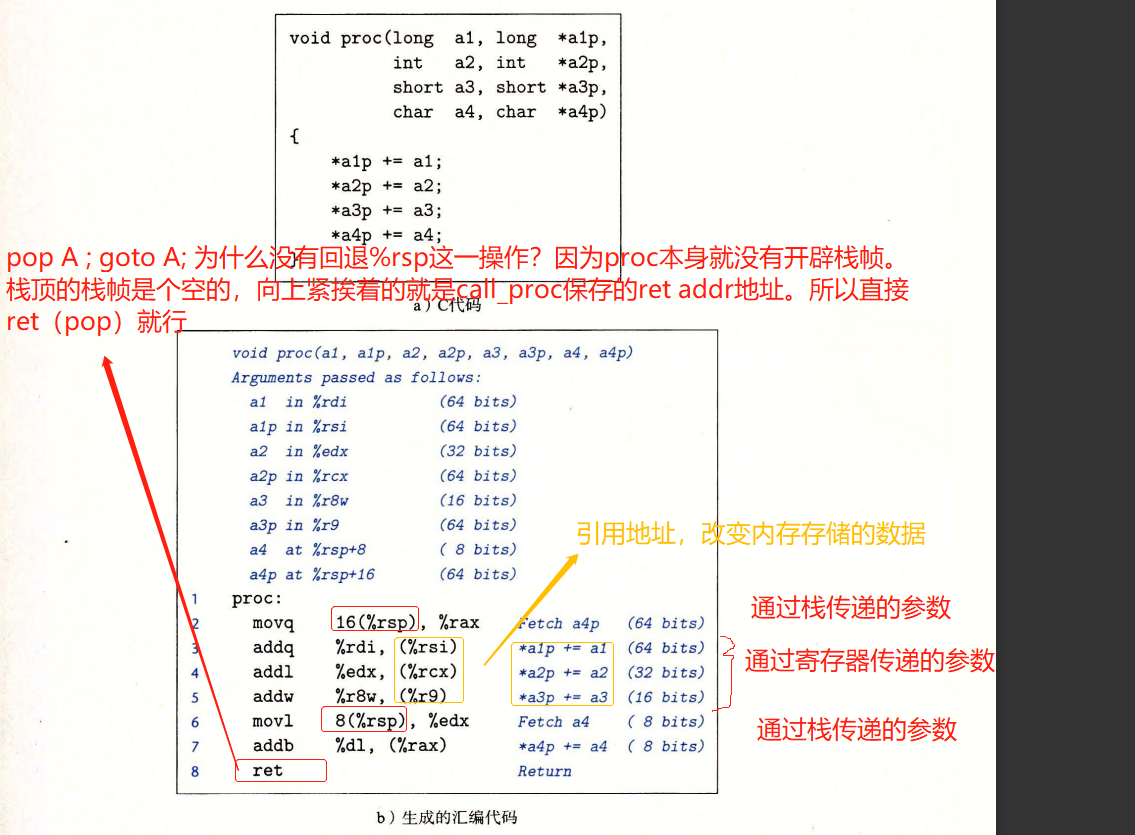
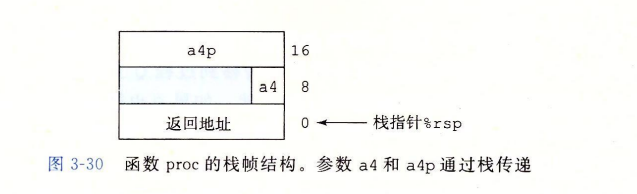
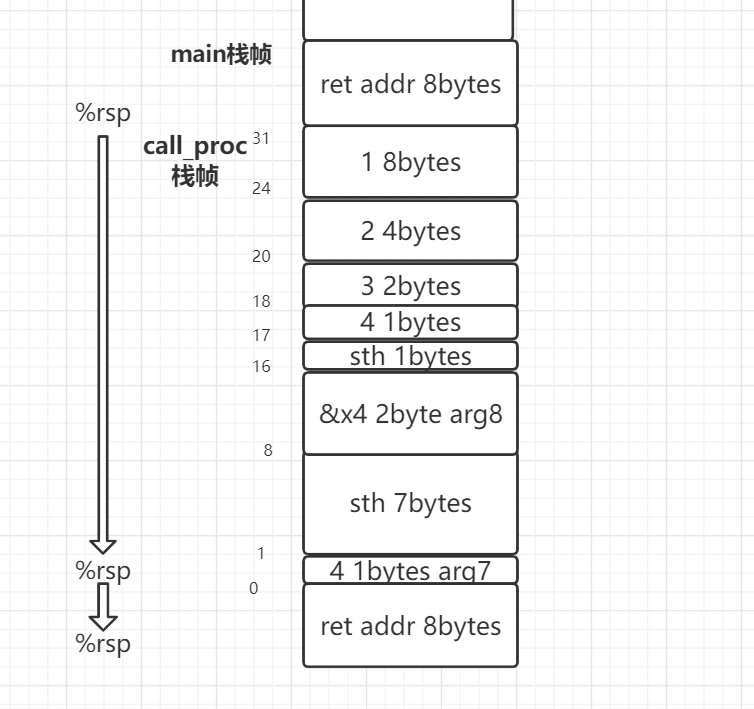
- 注意事项:
- 为调用过程开辟栈帧,是在call Q之后,进入Q之后做得事情,是被调用过程Q自己负责做得。
- 不仅直接移动%rsp会开辟栈帧,push也会;call 也会移动%rsp,拓展栈帧。
寄存器中的局部存储空间
寄存器组是唯一被所有过程共享的资源
为防止覆盖过程执行时覆盖寄存器的问题,按执行保存动作的对象来进行分类
被调用者保存寄存器
- %rbx、%rbp 、%r12~%r15
- 当P调用Q时,Q必须保存寄存器的值,保证他们的值在离开Q返回P时与进入Q之前是一样的。
- 执行过程是保存寄存器的原值是被调用者Q的责任
- 过程Q根本不改变他
- 过程Q把原始值压入栈中(在栈中的这部分称为被保存的寄存器),再改变寄存器。
调用者保存寄存器
- 其他所有寄存器,除了栈指针%rsp
- 过程P调用过程Q。Q可以任意修改这些寄存器。在调用Q之前就保存好这些寄存器的数据是P的责任。
把P中不想让被调用过程Q覆盖、改变的值存入被调用者保存寄存器,然后再调用Q即可。
举例

注意:过程中的局部变量先保存在被调用者保存的寄存器中,如果数量不够,那么在存入本过程的栈帧中。
Illustration Of Recursion
- 感觉没啥好说的。。
数据结构
Array
Basic Principle 基本原则
- T A[N]
- 该声明有两个效果
- 首先,在内存中分配一个L*N字节的连续区域。(L是数据类型T的大小)
- 其次,引入标识符A,可以用A来作为指向数组开头的指针,指针的值就是xa。
- x+i*L即为第i个元素的起始地址(i属于[0,N-1])
- 但是我们定义一个指针的时候,就只有该指针而没有额外分配的空间
- 指针运算
- E的起始地址在%rdx; i存在%rcx

- 看出:关于int的操作是4bytes,用movl;关于指针的操作是8bytes,用leaq。
- 地址计算用leaq,数据计算用movb/w/l/q
- E的起始地址在%rdx; i存在%rcx
Multi-dimensional(nested) 嵌套/多维数组 (内存连续)
整个数组内存连续,在一起,可以一次性计算内存要取的地址。因此,取得数组数据只需一次内存访问mem。(就是计算出地址之后进行一次mem)
嵌套数组和多维数组等价。是一个东西。
typedef int row3_t[3]; row3_t A[5]等价于int A[5][3]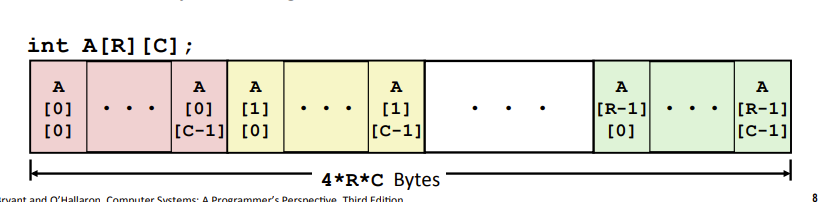
T D[R][C]&D[i][j] = xd + L(C*i+j)
如何取得数组元素。如下
例1:设int A[5][3]。将A[i][j]复制到寄存器%eax中
1
2
3
4A in %rdi , i in %rsi , j in %rdi
leaq (%rsi,%rsi,2),%rax %rax = 3*i # 1行有3个元素,计算i行有几个元素
leaq (%rdi,%rax,4),%rax %rax = %rdi + 4*%rax = xa + 4*(3*i) 1个元素4bytes,4*(3i) i行占多少个bytes
movl (%rax,%rdx,4),%rax %rax = %rax + 4*%rdx = xa + 4*(3*i) + 4*j 加j个元素大小例2:设int pgh[5][4]。将pgh[i][j]放入%eax

Multi-level 多层次数组 (内存不连续)
- 例子
1
2
3
4
5
6
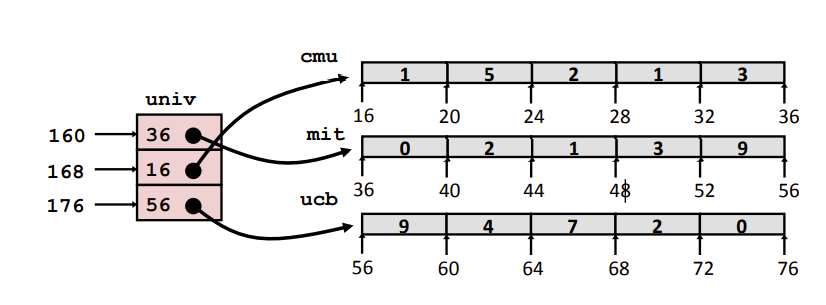
7zip_dig cmu = { 1, 5, 2, 1, 3 };
zip_dig mit = { 0, 2, 1, 3, 9 };
zip_dig ucb = { 9, 4, 7, 2, 0 };
...
int *univ[UCOUNT] = {mit, cmu, ucb};
univ一维数组,每个元素是一个指针,占8bytes。这个指针指向的是一维数组的起始地址。也就是说,这个元素本身的地址并不是数组的起始地址,而是它里面存的值,是数组的起始地址 - 如何取得值。由于内存不连续,不能一次性计算出地址。
- 需要先内存访问mem一次(读取指针),读取指针指向的一维数组的起始地址。然后再在这个的地址进行列的偏移计算。
- 所以获取一个unix[i][j]数据,需要进行两次内存访问。第一次是在计算地址时,第二次是在根据地址获取数据时。
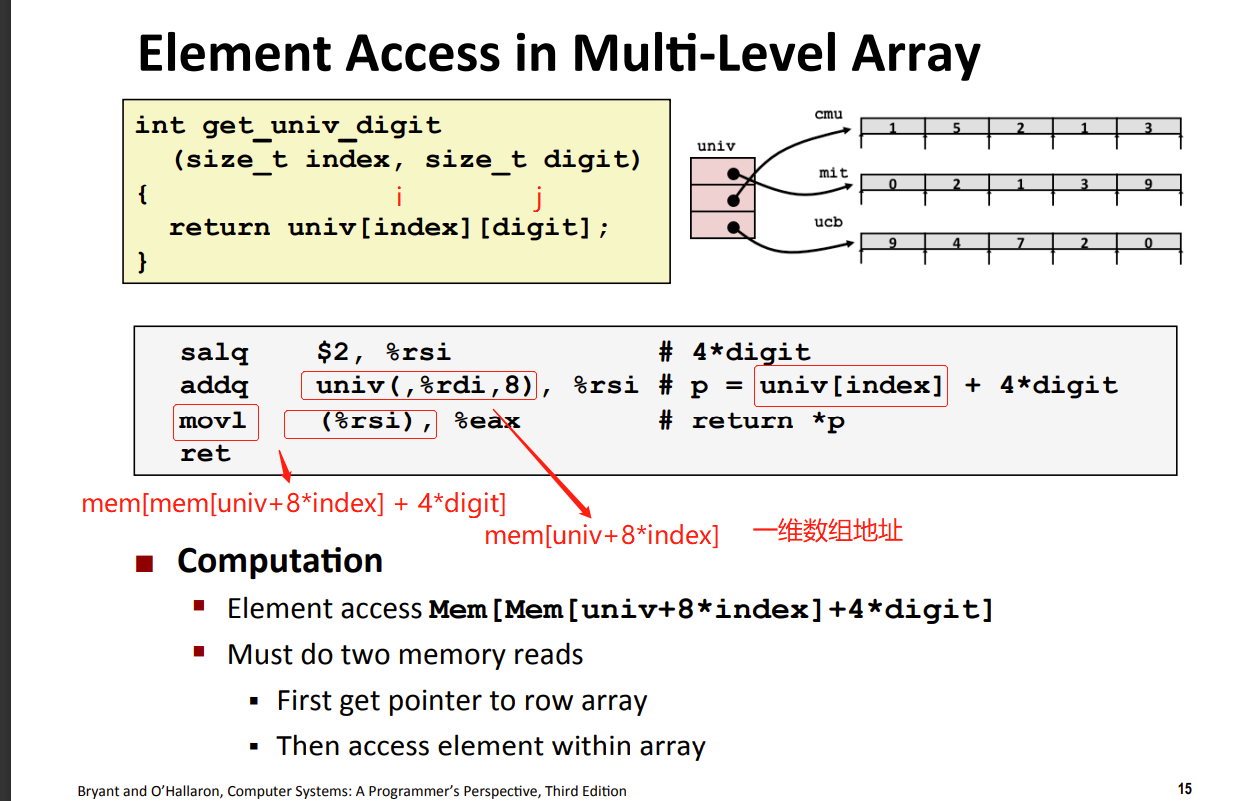
区别
- nested array:嵌套/多维数组
- 内存连续,可一次性计算出元素地址。获取数据只需要一次 mem_read
- multi-level array:多层次数组
- 内存不连续,不能一次性计算出元素地址,获取元素需要两次mem_read
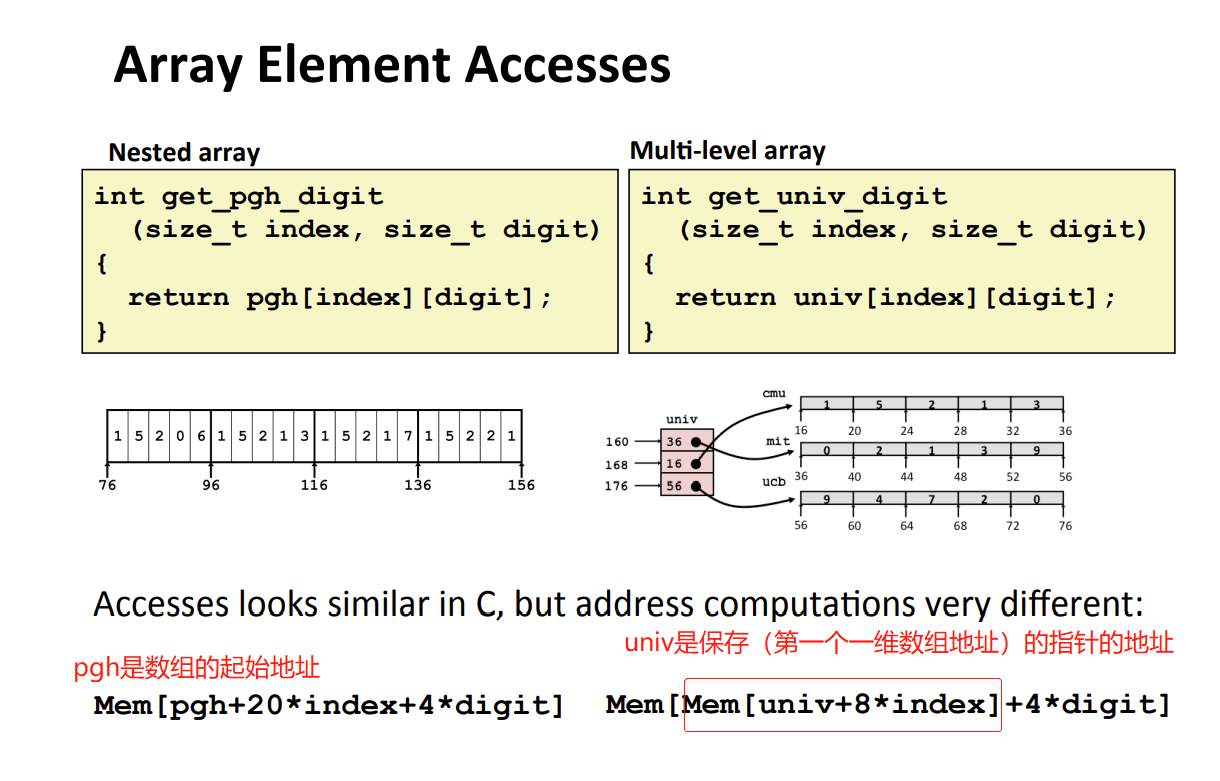
- 内存不连续,不能一次性计算出元素地址,获取元素需要两次mem_read
使用数组

数组越界
1.得到一个随机值
2.地址无效,发生段错误
struct 结构
- 将不同类型的对象组合到一起的机制:结构struct;联合union
- struct结构的所有组成部分都存放在内存中一段连续的区域内。(虽字段内会有内存对齐,但这些字段是连续的)指向结构的指针就是结构第一个字节的地址。
- 编译器维护关于每个结构类型的信息,指示每个字段的字节偏移。

union 联合体
- 联合:一种方式,规避C语言的类型系统,允许以多种类型来引用一个对象。即用不同字段来引用相同的内存块。
- 一个联合的大小 等于 它最大字段的大小
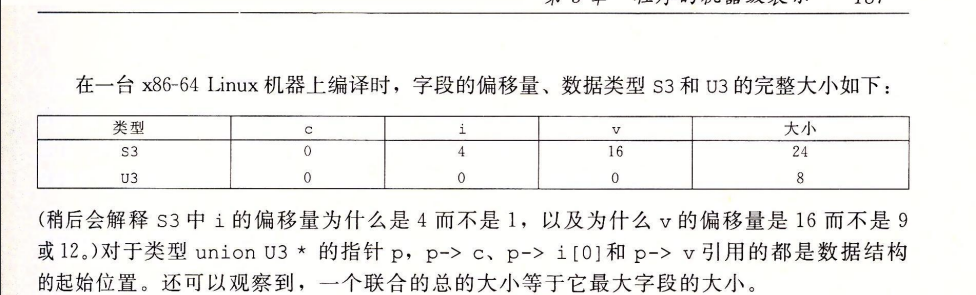
联合作用:
- 一个结构中的两个不同字段的使用是互斥的,那么就将这两个字段声明为联合的一部分,来节省空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18struct node_s{
struct node_s *left;
struct node_s *right;
double data[2];
}
8+8+16 = 32bytes
-->
struct node_t{
type_t t; // 4bytes
union{
struct {
struct node_t *letf;
struct node_t *right;
}internal;
double data[2];
}info // 16 bytes
}
4 + [4] + 16 = 24 - 联合还可用来访问不同数据类型的相同位模式。
- 普通的强制数据类型转换:double d = xxx ; unsigned long u = (unsigned long ) d。u是d的整数表示,且从d转化成u的过程按照IEEE754的标准需要进行位级别的改变(请看上一节博客),也就是说u和d的位模式大不相同。
- 使用union联合
1
2
3
4
5
6
7
8unsigned long double2bits(double d){
union{
double d;
unsigned long u;
} temp;
temp.d = d;
return temp.u;
} - 以一种数据类型(double)来存储union中的参数,又以另一种形式(unsigned long)访问它。temp.d和temp.u所引用的内存块中的位完全相同。
Alignment 数据对齐
对齐原则
- 许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种数据类型对象的地址必须是某个K(2/4/8)值的倍数。这种对齐限制简化了处理器和内存系统之间接口的硬件设计,(注意是基本数据类型,结构体本身不是基本数据类型)
- 对齐原则是任何K字节的基本对象的地址必须是K的倍数
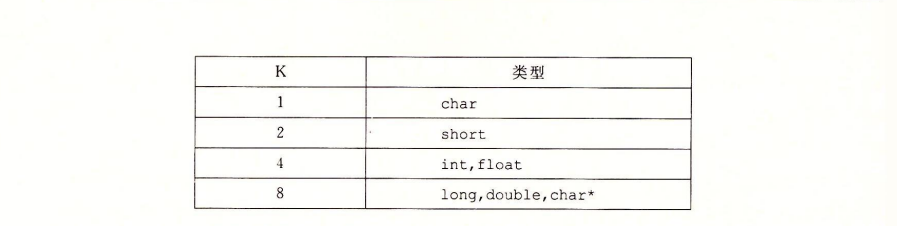
- 确保每种数据类型都是按照指定方式来组织和分配,即每种类型的对象都满足他的对齐限制,就可以保证实施对齐。如

结构的字段对齐
总的来说,结构的对齐要求就是
- (1) K大小的对象的起始地址必须是K的倍数
- (2) 为了下个同类型的结构体的起始地址,需要对本结构体的尾部进行填充。((2)由(1)推出)
- 一个结构体的起始地址应当是这个结构体内最大字段的倍数。(因为基本数据类型最大就是8ytes了。其他都是1、2、4。同时存在1、2、4、8时,起始地址是8的倍数才能满足所有类型的对齐要求。(反正我这么觉得)
- 因此也可以说是,一个结构体的大小,应当是其最大字段的倍数。
对于包含结构的代码,编译器可能需要在阶段的分配中插入间隙,以保证满足元素的对齐要求。
1
2
3
4
5struct S1{
int i;
char c;
int j;
}
为了下一个同类型结构体,对尾部进行填充。(默认进行填充)(按理来说似乎应该结构体数组才会起到作用)
1
2
3
4
5struct S2{
int i;
int j;
char c;
}
- 练习

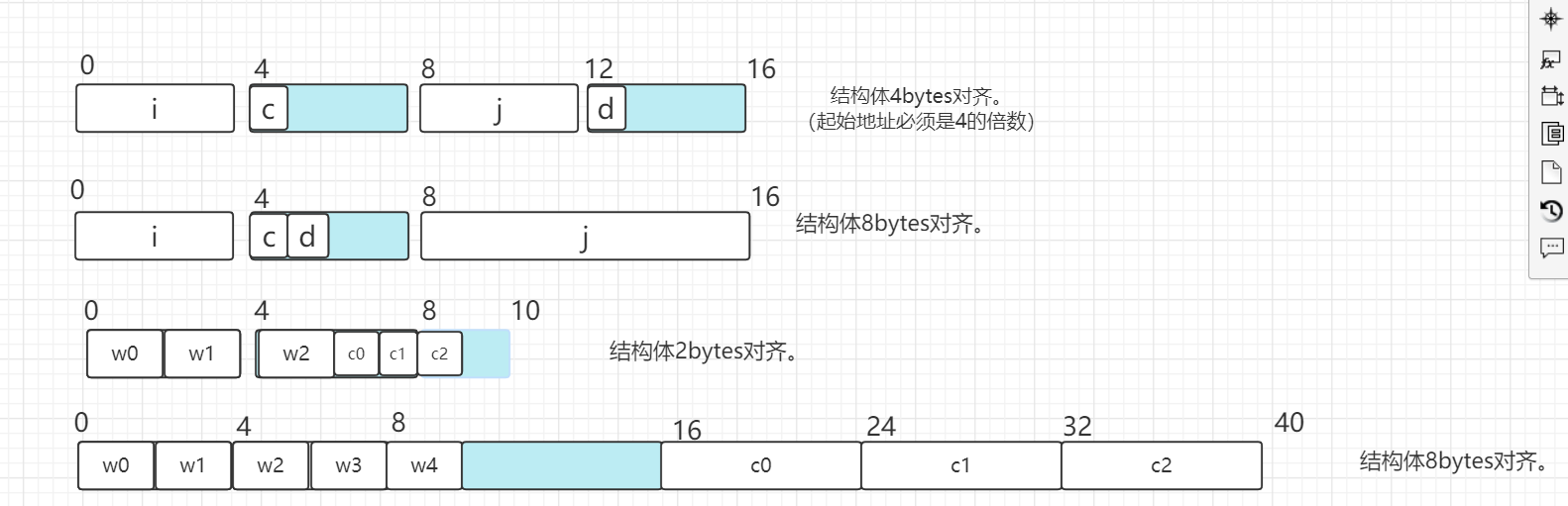

- 重排字段顺序,以最小化浪费的空间:一个有效的方式是按照字段由大到小排列。
安全
指针
- 强转指针类型:只改变类型不改变值。
- 函数指针
- 函数指针的值是函数机器代码的第一条指令的地址
1
2
3
4
5
6
7
8// 定义函数
int fun(int x,int *p);
// 定义指针
int (*fp)(int ,int *);
// 指针赋值
fp = fun;
// 使用指针调用函数:
fp(1,&x);
- 函数指针的值是函数机器代码的第一条指令的地址
- int *f(int *)
- f是一个函数。接收参数int* 返回 int*
- int (*f)(int *)
- f是一个函数指针。指向函数原型为 参数为int* 返回值为int的函数
地址范围
- 程序虚拟地址的大小范围[0,0x00007FFFFFFFFFFF]
- 现在64位机器限制使用47位地址。
- 64位bits 可以表示 2^64个地址 也就是意味着需要有16*10^18个字节。买这么多内存是一笔巨款。(即便是47位也是一笔巨款啊。
2^47/2^20/2^8 *150 = 2^19 * 150 = 75 * 10^6 = 75000000 = 7千5百万)(假设256G内存150RMB)
- 栈大小
- linux常用系统上,栈stack的大小是8MB,意味着如果用指针访问超过栈的8bytes,就会发生段错误seg fault
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17shc@shc-virtual-machine:~/Shared_ln/csapp/bomb$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15409
max locked memory (kbytes, -l) 65536
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
**stack size (kbytes, -s) 8192**
cpu time (seconds, -t) unlimited
max user processes (-u) 15409
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
- linux常用系统上,栈stack的大小是8MB,意味着如果用指针访问超过栈的8bytes,就会发生段错误seg fault
缓冲区溢出
后果
在栈中分配某个字符数组来保存字符串,但是字符串的长度超出了分配的空间。可能会导致
- 破坏本栈帧未被使用的栈空间
- 破坏稍后离开本栈帧返回时的返回地址
- 破坏调用者的栈帧状态
例子

所谓的改变返回地址,实际上就是通过改变存在栈中的ret_addr来改变ret时PC的内容,也就是%rip将要指向的指令地址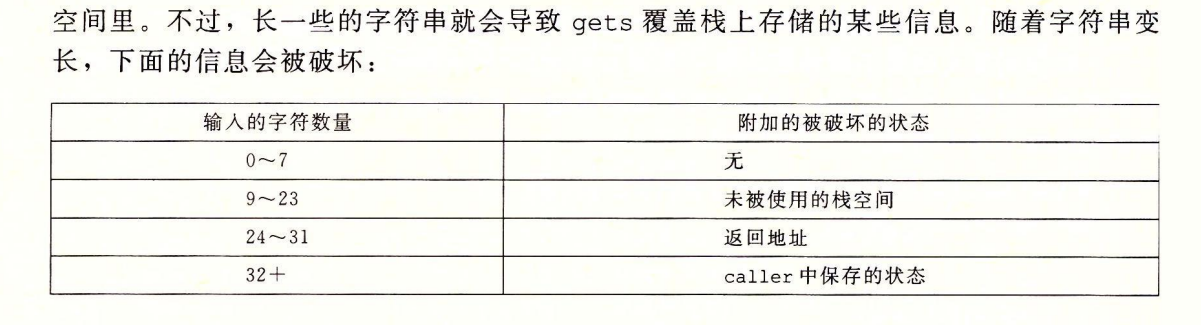

题

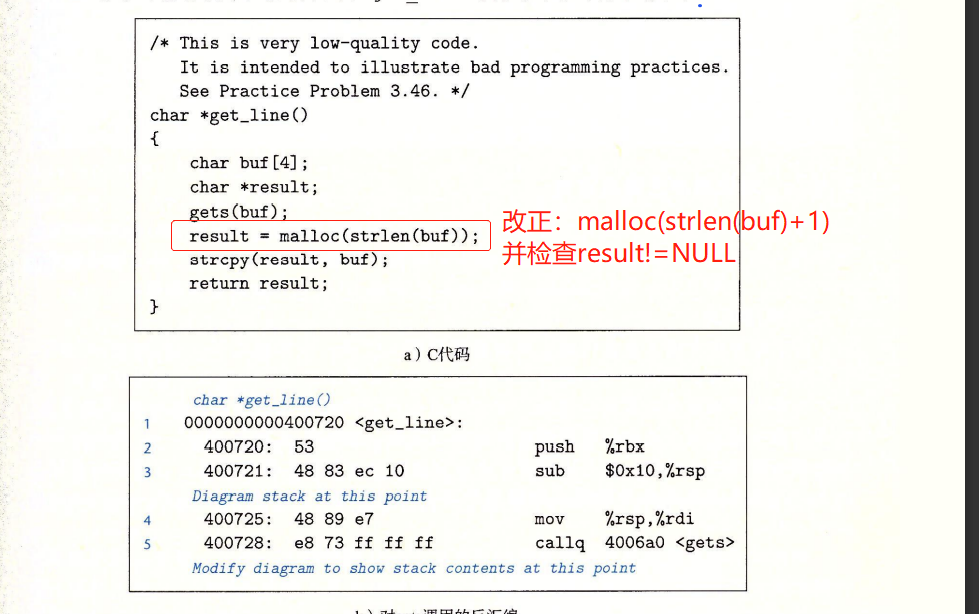

插入攻击代码
- 缓冲区溢出最致命的是可能会让程序执行它本不愿意执行的函数。
- 通过在输入的字符串中加入
- 可执行代码的字节编码,即攻击代码。
- 指向攻击代码指令地址的指针,覆盖原本的ret addr。
- 如P调用Q,Q离开时
- 原本%rip应当指向正常设置好的ret_addr(位于.text段),然后%rip一步步++去执行下一条指令。
- 然而,通过上述操作,使得ret_addr被更改为栈中的另一块地址,并且,栈中的这另一块地址也放入了编号的攻击代码。那么,%rip就会指向这段攻击代码的起始地址。随着%rip++,这段攻击代码就会被执行。
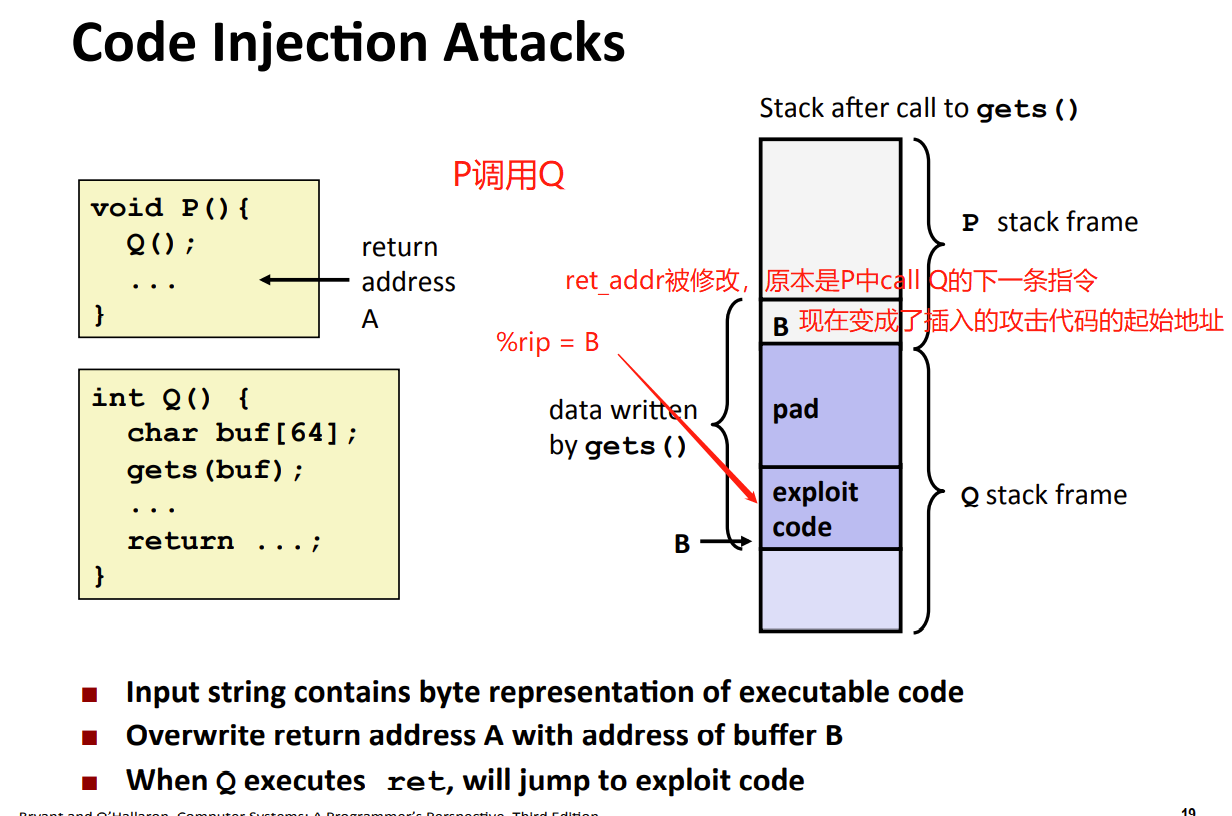
- 如图。gets的字符串溢出。字符串包括 exploit code(攻击代码)、pad(空)、(攻击代码地址)。(pad是为了让ret_addr被覆盖)
- 通过在输入的字符串中加入
对抗缓冲区溢出攻击
- 随机化、栈保护、限制那部分内存可以存储可执行代码
- 是用于最小化程序缓冲区溢出攻击漏洞的三种最常见机制。
- 不需要程序员做任何特殊的奴鲁,带来的性能代价很小甚至没有。
栈随机化
为了在系统中插入攻击代码,攻击者既要插入exploit code,又要插入指向exploit code的pointer,这个pointer也是攻击字符串的一部分。其中产生这个pointer,需要知道字符串缓冲区的栈地址。
如果栈地址非常容易预测,且运行同样程序和操作系统的不同机器上,栈的位置都相当固定。因此,攻击者确定了一个常用的服务器所用的栈空间,就可以设计一个许多机器上都能实现的攻击。形成安全单一化现象:许多系统都易受到同一病毒攻击。
栈随机化:栈的位置在程序每次运行时都有变化。因此,当许多机器运行同样的代码,他们的栈地址是不同的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49int x;
int y = 9;
int fun(){return 0;}
int main()
{
long local;
int * p = (int*)malloc(sizeof(int));
printf("size = %ld\n",sizeof(&local));
printf("local at %p\n",&local);
printf("local at %p\n",p);
printf("local at %p\n",&x);
printf("local at %p\n",&y);
printf("local at %p\n",fun);
return 0;
}
shc@shc-virtual-machine:~/code/try$ gcc aslr.c -o asl.out -Wall
shc@shc-virtual-machine:~/code/try$ ./asl.out
size = 8
local at 0x7ffd1b230218
local at 0x55a4564ab260
local at 0x55a454c25018
local at 0x55a454c25010
local at 0x55a454a246fa
shc@shc-virtual-machine:~/code/try$ ./asl.out
size = 8
local at 0x7ffc2e7746b8
local at 0x55d825bc1260
local at 0x55d824e70018
local at 0x55d824e70010
local at 0x55d824c6f6fa
shc@shc-virtual-machine:~/code/try$ ./asl.out
size = 8
local at 0x7fffb1830868
local at 0x55fa6f69c260
local at 0x55fa6f05d018
local at 0x55fa6f05d010
local at 0x55fa6ee5c6fa
shc@shc-virtual-machine:~/code/try$ ./asl.out
size = 8
local at 0x7ffc45a56418
local at 0x557de4b6c260
local at 0x557de2e3c018
local at 0x557de2e3c010
local at 0x557de2c3b6fa
似乎只有栈在变。。为啥捏。。
>视频:global和fun不变,stack上的局部变量的地址每次会改变,害有heap上的地址每次也会改变- 实现方式:程序开始时,在栈上分配[0,n]bytes之间随即大小的空间。程序不使用这段空间。但他会导致每次执行时后续的栈位置发生变化。
- 分配的范围n必须足够大,才能获得足够多的栈地址变化,但又要足够小,不至于浪费程序太多空间。
- 实现方式:程序开始时,在栈上分配[0,n]bytes之间随即大小的空间。程序不使用这段空间。但他会导致每次执行时后续的栈位置发生变化。
地址空间布局随机化(Address-Space Layout Randomization — ASLR)
每次程序运行时的不同部分:程序代码、库代码、栈、全局变量和堆数据,都被加载到内存不同区域。这意味着不同机器上运行的相同程序,其地址映射不同,以此对抗攻击。
- 但我运行了以下没变啊。
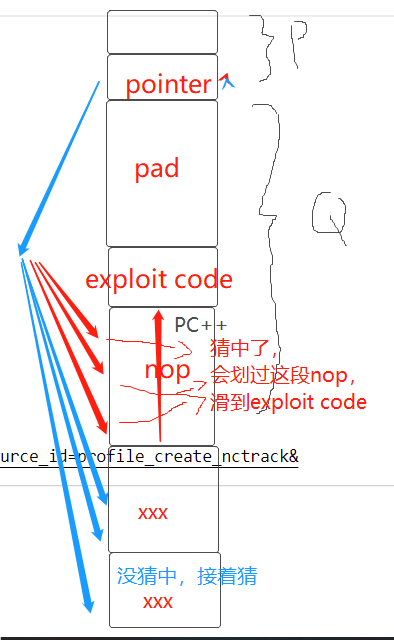
- 空操作雪橇
- 在攻击代码前插入一段很长的nop空指令。只有PC++的效果,无其他行为。只要攻击者能猜中这段序列的某个地址,程序就会划过这个序列。
- 应该是这个意思。至于如何保证pointer放置在原ret_addr位置上,我也不到啊。
栈破坏检测
检测栈何时被破坏
- C无法防止数组越界写,但我们可以在数组越界时,在造成任何有害结果前,尝试检测到他。
栈保护者机制
- 在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀值(canary),也被称为哨兵值。(攻击者没法轻易获取该值)
- 在恢复寄存器状态和从过程返回之前,程序会检查这个金丝雀值是否被该过程的某个操作或者该过程调用的某个过程的某个操作改变。若是,程序异常终止。
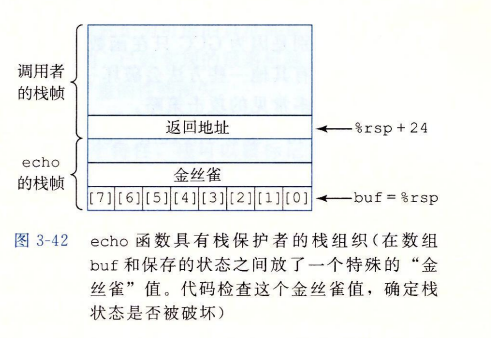

- 在恢复寄存器状态和从过程返回之前,程序会检查这个金丝雀值是否被该过程的某个操作或者该过程调用的某个过程的某个操作改变。若是,程序异常终止。
- 在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀值(canary),也被称为哨兵值。(攻击者没法轻易获取该值)
canary原本被存储在只读段 %fs:40(段寻址)。xorq,结果非0代表canary被改变。
栈保护很好的防止了缓冲区溢出攻击破坏存储在程序栈上的状态,性能损失也很小。
GCC只在函数中有局部char类型缓冲区时才插入这样的代码。
栈状态相关的局部变量应比buf更靠近栈顶,这样buf溢出就更不会破坏局部变量的值。所以自顶向底应该是局部变量、canary、buf。
限制可执行代码区域
- 消除攻击者向系统插入可执行代码的能力
- 方法:限制那些内存区域能够存放可执行代码。
- 在典型的程序中,只有保存编译器产生的代码的那部分(text)内存才需要是可执行的,其他部分被限制为只允许读和写。详情见csapp第9章。
- 硬件支持多种形式的内存保护,可以指明用户程序和os内核所允许的访问形式。
- 许多系统允许控制三种访问形式:读(从内存中读数据)、写(写数据到内存)、执行(将内存的内容看作机器级代码)。
- 以前,x86将读和执行合并成1位标志位,这样任何被标记为可读的页也是可执行的。因为栈上的字节可读,因此栈上的字节也是可执行的。
- 后来,x8664引入No-Excute位,将读和执行模式分开,栈上的字节可以被标记为可读可写不可知性,而检查页是否可执行由硬件完成,效率上没损失。
变长栈帧
场景:当函数中存在变长数组时
帧指针 : frame pointer
- 也被称为基指针 : base pointer
为了管理变长栈帧,x86-64使用寄存器%rbp作为帧指针
使用帧指针的栈帧结构
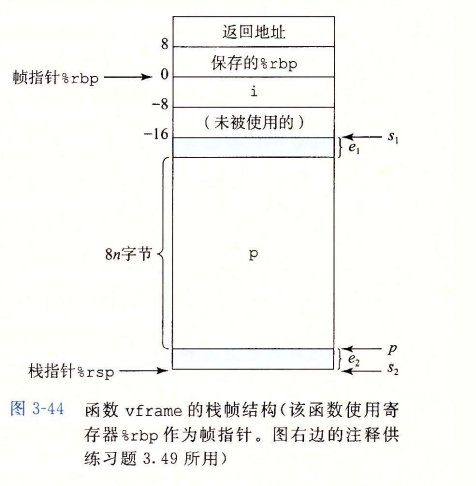
%rbp作用:在函数的整个执行过程中,%rbp一直指向那个时刻栈的位置,然后用固定长度的局部变量(例如i)相对于%rbp的偏移量来引用他们。
- 也就是说,用作一个基坐标,去确定其他变量的地址。
非变长栈帧时,用的基坐标是%rsp,其中注意%rsp时刻指向栈顶,因此当栈帧长度无法确定(编译时无法确定,需运行时确定如由用户输入确定时),编译器就无法确定在某一时刻%rsp的位置,也就无法把他当作基坐标去定位其他变量。因此需要引入一个固定的地址,因此就需要%rbp作为基指针,保存某一时刻(进入过程时)的栈的位置不变,作为基坐标,去定位本过程中用到的其他变量。
剩下的有时间再整理。该补数罗作业了。。。
csapp 202 + 3.49
较早版本的x86中,每个函数都使用帧指针(%rbp存储),而现在,只有栈帧长度为变长时(编译时无法确定的长度)才使用,如例子中的frame。
GDB
- 详情见gdb调试博客
$>gdb prog
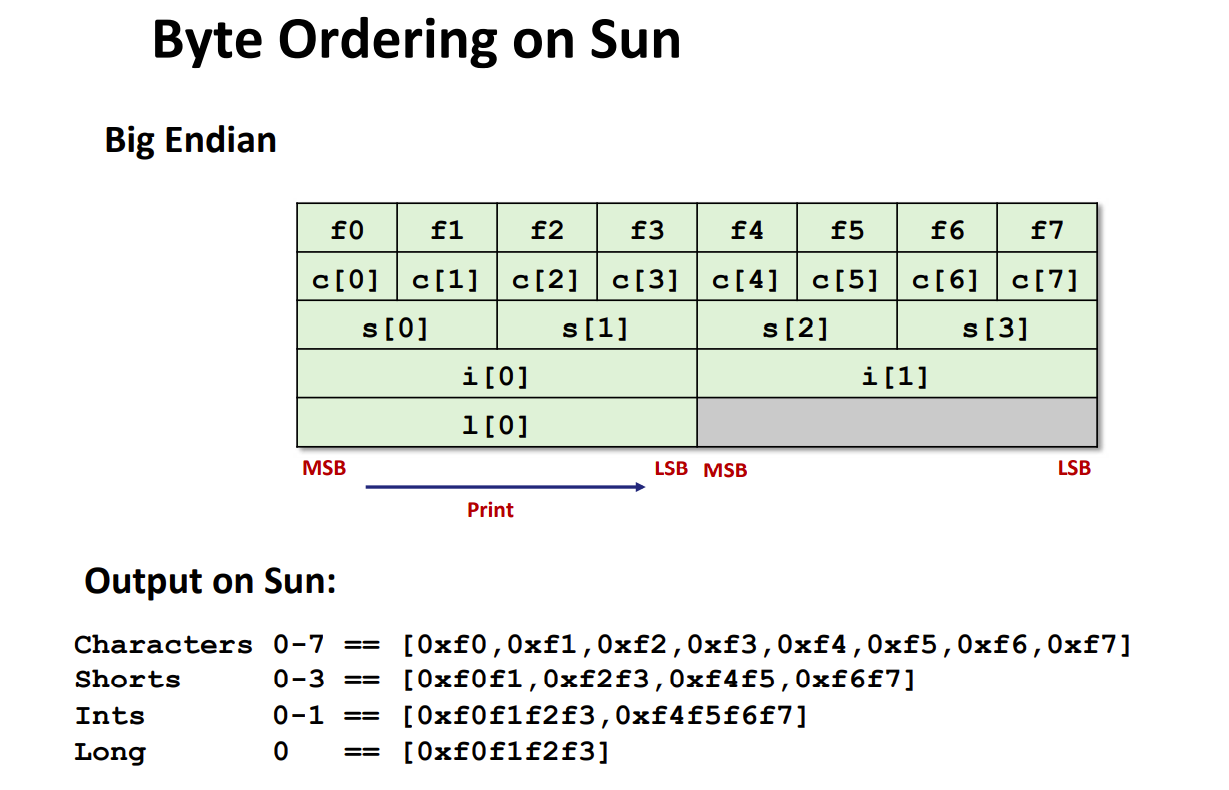
大小端
- 总容易搞混啊md
- 大端模式:低地址放高位 Sprac
- 小端模式:低地址放低位。Intel x86, ARM Android and IOS
- 一个字节内不存在什么大小端。(因为一地址一字节)
- 大小端模式存在于一个基本类型的对象内,其内部的低地址存储低位数据,高地址存储高位数据。
- 而不是不存在于一个数组中,那整个数组岂不是倒过来了。如数组c[8],那么c[0]位于低地址,c[7]位于高地址。
- 小端x86
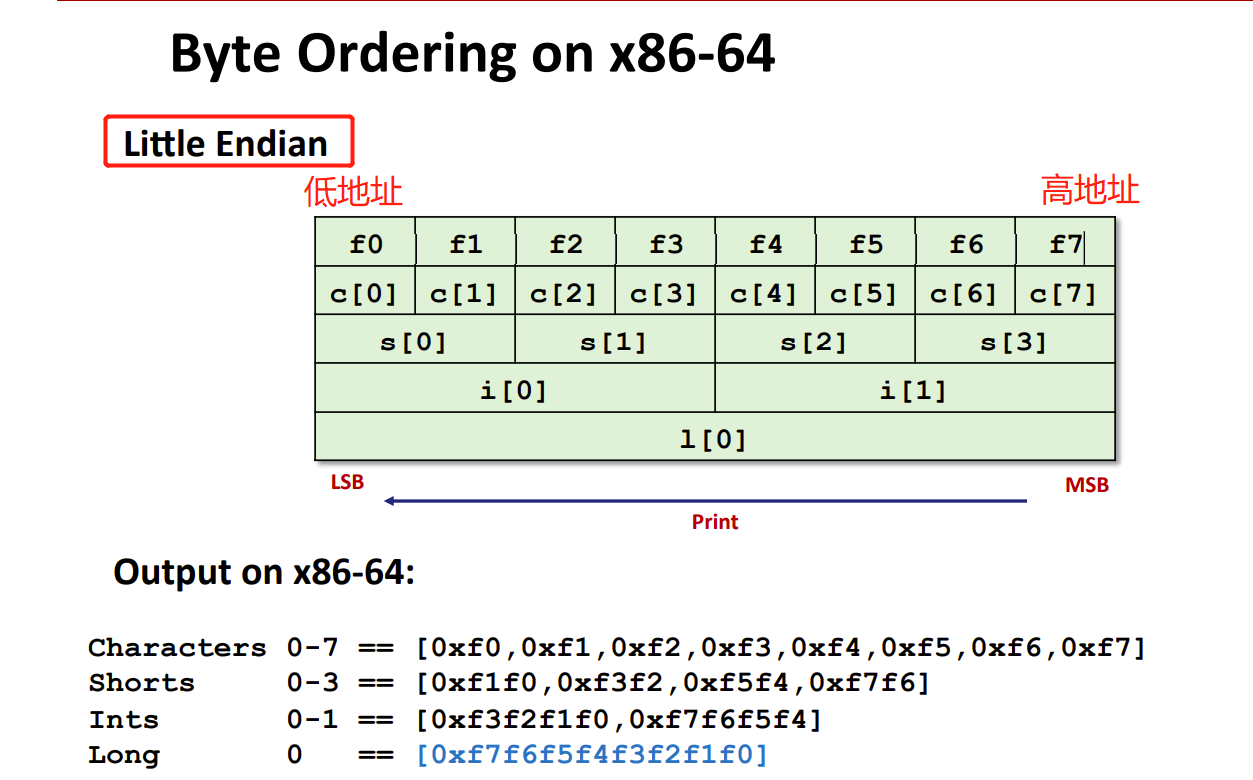
- 大端